 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Pre-trained Encoder-Decoder Transformers for Sequence-to-Sequence Constituent Parsing
May 13, 2026To achieve deep natural language understanding, syntactic constituent parsing plays a crucial role and is widely required by many artificial intelligence systems for processing both text and speech. A recent approach involves using standard sequence-to-sequence models to handle constituent parsing as a machine translation problem, moving away from traditional task-specific parsers. These models are typically initialized with pre-trained encoder-only language models like BERT or RoBERTa. However, the use of pre-trained encoder-decoder language models for constituency parsing has not been thoroughly explored. To bridge this gap, we extend the sequence-to-sequence framework by investigating parsers built on pre-trained encoder-decoder architectures, including BART, mBART, and T5. We fine-tune them to generate linearized parse trees and extensively evaluate them on different linearization strategies across both continuous treebanks and more complex discontinuous benchmarks. Our results demonstrate that our approach outperforms all prior sequence-to-sequence models and performs competitively with leading task-specific constituent parsers on continuous constituent parsing.
Structured Sentiment Analysis as Transition-based Dependency Parsing
May 09, 2023



Structured sentiment analysis (SSA) aims to automatically extract people's opinions from a text in natural language and adequately represent that information in a graph structure. One of the most accurate methods for performing SSA was recently proposed and consists of approaching it as a dependency parsing task. Although we can find in the literature how transition-based algorithms excel in dependency parsing in terms of accuracy and efficiency, all proposed attempts to tackle SSA following that approach were based on graph-based models. In this article, we present the first transition-based method to address SSA as dependency parsing. Specifically, we design a transition system that processes the input text in a left-to-right pass, incrementally generating the graph structure containing all identified opinions. To effectively implement our final transition-based model, we resort to a Pointer Network architecture as a backbone. From an extensive evaluation, we demonstrate that our model offers the best performance to date in practically all cases among prior dependency-based methods, and surpass recent task-specific techniques on the most challenging datasets. We additionally include an in-depth analysis and empirically prove that the overall time-complexity cost of our approach is quadratic in the sentence length, being more efficient than top-performing graph-based parsers.
Transition-based Semantic Role Labeling with Pointer Networks
May 20, 2022



Semantic role labeling (SRL) focuses on recognizing the predicate-argument structure of a sentence and plays a critical role in many natural language processing tasks such as machine translation and question answering. Practically all available methods do not perform full SRL, since they rely on pre-identified predicates, and most of them follow a pipeline strategy, using specific models for undertaking one or several SRL subtasks. In addition, previous approaches have a strong dependence on syntactic information to achieve state-of-the-art performance, despite being syntactic trees equally hard to produce. These simplifications and requirements make the majority of SRL systems impractical for real-world applications. In this article, we propose the first transition-based SRL approach that is capable of completely processing an input sentence in a single left-to-right pass, with neither leveraging syntactic information nor resorting to additional modules. Thanks to our implementation based on Pointer Networks, full SRL can be accurately and efficiently done in $O(n^2)$, achieving the best performance to date on the majority of languages from the CoNLL-2009 shared task.
Discontinuous Grammar as a Foreign Language
Oct 20, 2021
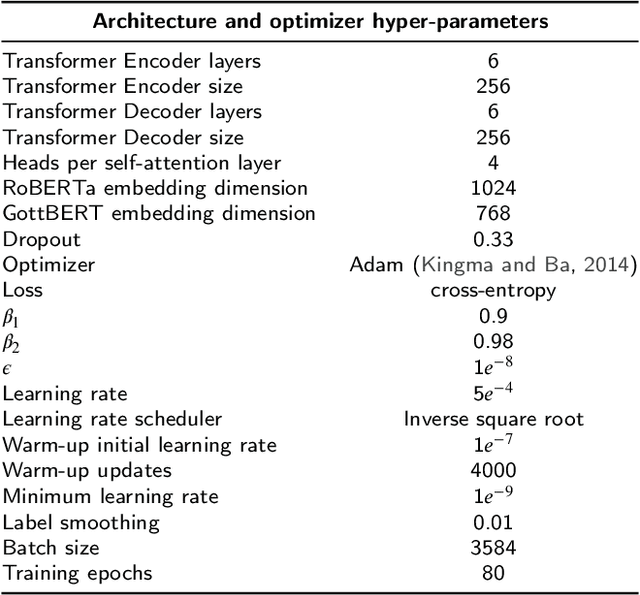
In order to achieve deep natural language understanding, syntactic constituent parsing is a vital step, highly demanded by many artificial intelligence systems to process both text and speech. One of the most recent proposals is the use of standard sequence-to-sequence models to perform constituent parsing as a machine translation task, instead of applying task-specific parsers. While they show a competitive performance, these text-to-parse transducers are still lagging behind classic techniques in terms of accuracy, coverage and speed. To close the gap, we here extend the framework of sequence-to-sequence models for constituent parsing, not only by providing a more powerful neural architecture for improving their performance, but also by enlarging their coverage to handle the most complex syntactic phenomena: discontinuous structures. To that end, we design several novel linearizations that can fully produce discontinuities and, for the first time, we test a sequence-to-sequence model on the main discontinuous benchmarks, obtaining competitive results on par with task-specific discontinuous constituent parsers and achieving state-of-the-art scores on the (discontinuous) English Penn Treebank.
Dependency Parsing with Bottom-up Hierarchical Pointer Networks
May 20, 2021



Dependency parsing is a crucial step towards deep language understanding and, therefore, widely demanded by numerous Natural Language Processing applications. In particular, left-to-right and top-down transition-based algorithms that rely on Pointer Networks are among the most accurate approaches for performing dependency parsing. Additionally, it has been observed for the top-down algorithm that Pointer Networks' sequential decoding can be improved by implementing a hierarchical variant, more adequate to model dependency structures. Considering all this, we develop a bottom-up-oriented Hierarchical Pointer Network for the left-to-right parser and propose two novel transition-based alternatives: an approach that parses a sentence in right-to-left order and a variant that does it from the outside in. We empirically test the proposed neural architecture with the different algorithms on a wide variety of languages, outperforming the original approach in practically all of them and setting new state-of-the-art results on the English and Chinese Penn Treebanks for non-contextualized and BERT-based embeddings.
Reducing Discontinuous to Continuous Parsing with Pointer Network Reordering
Apr 13, 2021

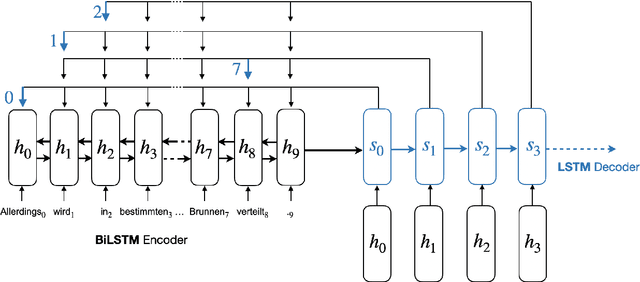

Discontinuous constituent parsers have always lagged behind continuous approaches in terms of accuracy and speed, as the presence of constituents with discontinuous yield introduces extra complexity to the task. However, a discontinuous tree can be converted into a continuous variant by reordering tokens. Based on that, we propose to reduce discontinuous parsing to a continuous problem, which can then be directly solved by any off-the-shelf continuous parser. To that end, we develop a Pointer Network capable of accurately generating the continuous token arrangement for a given input sentence and define a bijective function to recover the original order. Experiments on the main benchmarks with two continuous parsers prove that our approach is on par in accuracy with purely discontinuous state-of-the-art algorithms, but considerably faster.
Multitask Pointer Network for Multi-Representational Parsing
Sep 21, 2020
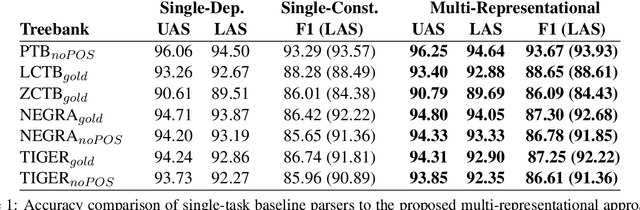


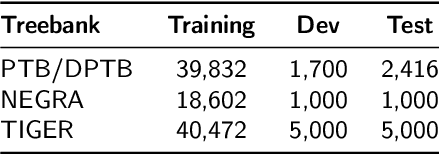
We propose a transition-based approach that, by training a single model, can efficiently parse any input sentence with both constituent and dependency trees, supporting both continuous/projective and discontinuous/non-projective syntactic structures. To that end, we develop a Pointer Network architecture with two separate task-specific decoders and a common encoder, and follow a multitask learning strategy to jointly train them. The resulting quadratic system, not only becomes the first parser that can jointly produce both unrestricted constituent and dependency trees from a single model, but also proves that both syntactic formalisms can benefit from each other during training, achieving state-of-the-art accuracies in several widely-used benchmarks such as the continuous English and Chinese Penn Treebanks, as well as the discontinuous German NEGRA and TIGER datasets.
Transition-based Semantic Dependency Parsing with Pointer Networks
May 28, 2020



Transition-based parsers implemented with Pointer Networks have become the new state of the art in dependency parsing, excelling in producing labelled syntactic trees and outperforming graph-based models in this task. In order to further test the capabilities of these powerful neural networks on a harder NLP problem, we propose a transition system that, thanks to Pointer Networks, can straightforwardly produce labelled directed acyclic graphs and perform semantic dependency parsing. In addition, we enhance our approach with deep contextualized word embeddings extracted from BERT. The resulting system not only outperforms all existing transition-based models, but also matches the best fully-supervised accuracy to date on the SemEval 2015 Task 18 English datasets among previous state-of-the-art graph-based parsers.
Enriched In-Order Linearization for Faster Sequence-to-Sequence Constituent Parsing
May 27, 2020



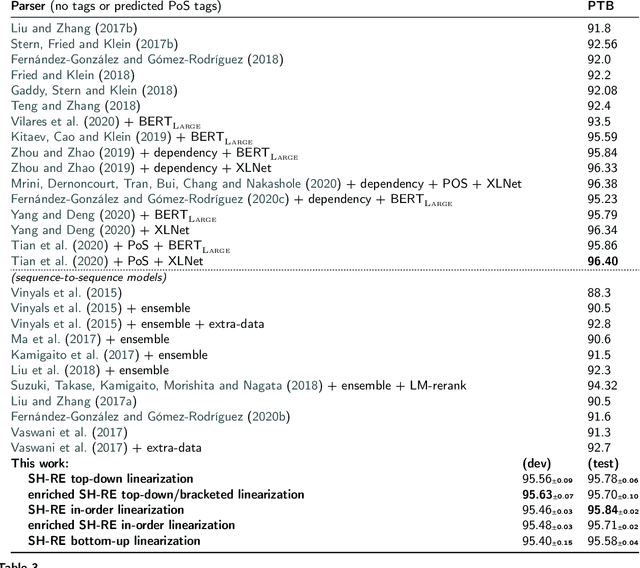
Sequence-to-sequence constituent parsing requires a linearization to represent trees as sequences. Top-down tree linearizations, which can be based on brackets or shift-reduce actions, have achieved the best accuracy to date. In this paper, we show that these results can be improved by using an in-order linearization instead. Based on this observation, we implement an enriched in-order shift-reduce linearization inspired by Vinyals et al. (2015)'s approach, achieving the best accuracy to date on the English PTB dataset among fully-supervised single-model sequence-to-sequence constituent parsers. Finally, we apply deterministic attention mechanisms to match the speed of state-of-the-art transition-based parsers, thus showing that sequence-to-sequence models can match them, not only in accuracy, but also in speed.
Discontinuous Constituent Parsing with Pointer Networks
Feb 05, 2020



One of the most complex syntactic representations used in computational linguistics and NLP are discontinuous constituent trees, crucial for representing all grammatical phenomena of languages such as German. Recent advances in dependency parsing have shown that Pointer Networks excel in efficiently parsing syntactic relations between words in a sentence. This kind of sequence-to-sequence models achieve outstanding accuracies in building non-projective dependency trees, but its potential has not been proved yet on a more difficult task. We propose a novel neural network architecture that, by means of Pointer Networks, is able to generate the most accurate discontinuous constituent representations to date, even without the need of Part-of-Speech tagging information. To do so, we internally model discontinuous constituent structures as augmented non-projective dependency structures. The proposed approach achieves state-of-the-art results on the two widely-used NEGRA and TIGER benchmarks, outperforming previous work by a wide margin.