 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSYNTAGMA. A Linguistic Approach to Parsing
Jan 21, 2016SYNTAGMA is a rule-based parsing system, structured on two levels: a general parsing engine and a language specific grammar. The parsing engine is a language independent program, while grammar and language specific rules and resources are given as text files, consisting in a list of constituent structuresand a lexical database with word sense related features and constraints. Since its theoretical background is principally Tesniere's Elements de syntaxe, SYNTAGMA's grammar emphasizes the role of argument structure (valency) in constraint satisfaction, and allows also horizontal bounds, for instance treating coordination. Notions such as Pro, traces, empty categories are derived from Generative Grammar and some solutions are close to Government&Binding Theory, although they are the result of an autonomous research. These properties allow SYNTAGMA to manage complex syntactic configurations and well known weak points in parsing engineering. An important resource is the semantic network, which is used in disambiguation tasks. Parsing process follows a bottom-up, rule driven strategy. Its behavior can be controlled and fine-tuned.
Syntax-Semantics Interaction Parsing Strategies. Inside SYNTAGMA
Jan 21, 2016This paper discusses SYNTAGMA, a rule based NLP system addressing the tricky issues of syntactic ambiguity reduction and word sense disambiguation as well as providing innovative and original solutions for constituent generation and constraints management. To provide an insight into how it operates, the system's general architecture and components, as well as its lexical, syntactic and semantic resources are described. After that, the paper addresses the mechanism that performs selective parsing through an interaction between syntactic and semantic information, leading the parser to a coherent and accurate interpretation of the input text.
Syntagma Lexical Database
Mar 19, 2015This paper discusses the structure of Syntagma's Lexical Database (focused on Italian). The basic database consists in four tables. Table Forms contains word inflections, used by the POS-tagger for the identification of input-words. Forms is related to Lemma. Table Lemma stores all kinds of grammatical features of words, word-level semantic data and restrictions. In the table Meanings meaning-related data are stored: definition, examples, domain, and semantic information. Table Valency contains the argument structure of each meaning, with syntactic and semantic features for each argument. The extended version of SLD contains the links to Syntagma's Semantic Net and to the WordNet synsets of other languages.
Rule-Based Semantic Tagging. An Application Undergoing Dictionary Glosses
May 17, 2013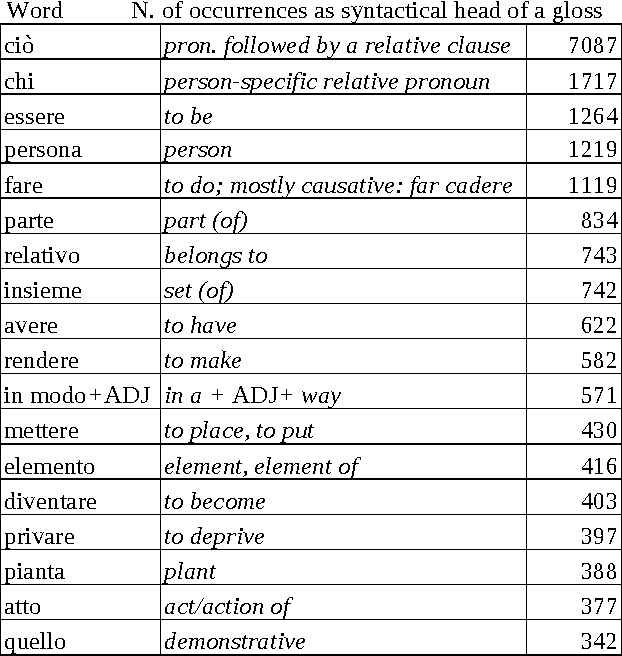
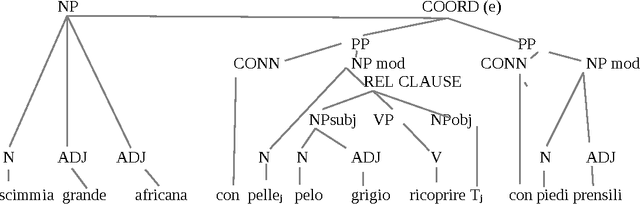
The project presented in this article aims to formalize criteria and procedures in order to extract semantic information from parsed dictionary glosses. The actual purpose of the project is the generation of a semantic network (nearly an ontology) issued from a monolingual Italian dictionary, through unsupervised procedures. Since the project involves rule-based Parsing, Semantic Tagging and Word Sense Disambiguation techniques, its outcomes may find an interest also beyond this immediate intent. The cooperation of both syntactic and semantic features in meaning construction are investigated, and procedures which allows a translation of syntactic dependencies in semantic relations are discussed. The procedures that rise from this project can be applied also to other text types than dictionary glosses, as they convert the output of a parsing process into a semantic representation. In addition some mechanism are sketched that may lead to a kind of procedural semantics, through which multiple paraphrases of an given expression can be generated. Which means that these techniques may find an application also in 'query expansion' strategies, interesting Information Retrieval, Search Engines and Question Answering Systems.