 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOldies but Goldies: The Potential of Character N-grams for Romanian Texts
Jun 18, 2025This study addresses the problem of authorship attribution for Romanian texts using the ROST corpus, a standard benchmark in the field. We systematically evaluate six machine learning techniques: Support Vector Machine (SVM), Logistic Regression (LR), k-Nearest Neighbors (k-NN), Decision Trees (DT), Random Forests (RF), and Artificial Neural Networks (ANN), employing character n-gram features for classification. Among these, the ANN model achieved the highest performance, including perfect classification in four out of fifteen runs when using 5-gram features. These results demonstrate that lightweight, interpretable character n-gram approaches can deliver state-of-the-art accuracy for Romanian authorship attribution, rivaling more complex methods. Our findings highlight the potential of simple stylometric features in resource, constrained or under-studied language settings.
A chain dictionary method for Word Sense Disambiguation and applications
Jun 16, 2008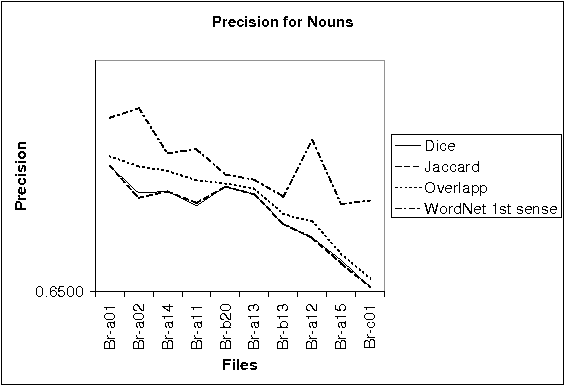
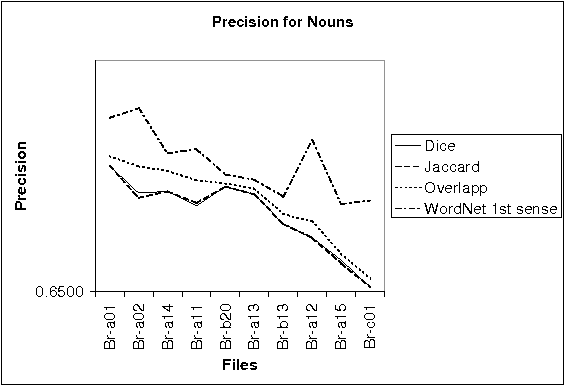
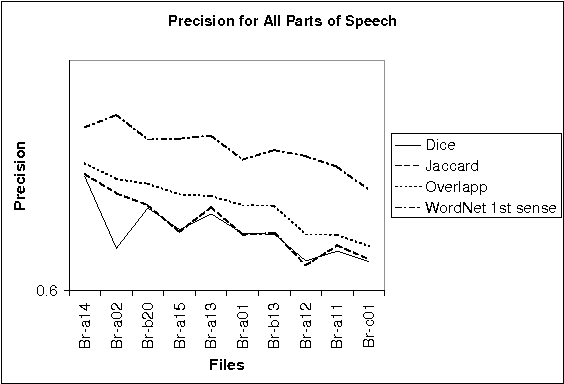
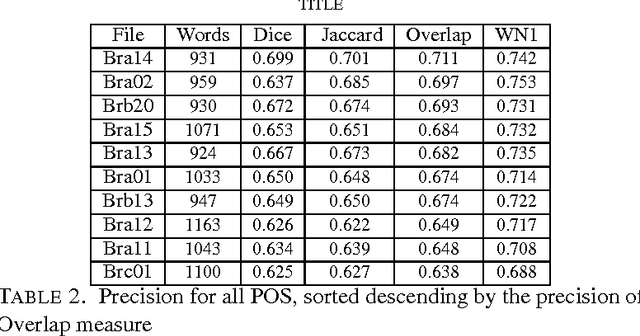
A large class of unsupervised algorithms for Word Sense Disambiguation (WSD) is that of dictionary-based methods. Various algorithms have as the root Lesk's algorithm, which exploits the sense definitions in the dictionary directly. Our approach uses the lexical base WordNet for a new algorithm originated in Lesk's, namely "chain algorithm for disambiguation of all words", CHAD. We show how translation from a language into another one and also text entailment verification could be accomplished by this disambiguation.
* 8 pages, 5 figures