 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Test-time Actor-Critic Approach to News Images Generation
Jun 19, 2026This paper introduces the CERTH-ITI solution for the MediaEval NewsImages 2026 challenge, which focuses on generating images related to news headlines. Inspired by the Actor-Critic paradigm in reinforcement learning, we present a test-time, model-agnostic Actor-Critic Image Generation approach (ACIG). ACIG generates prompts for image creation, produces the images, evaluates the generated results, and if needed refines the image generation prompts accordingly in a feedback loop. ACIG achieved the best results in the NewsImages 2026 challenge, according to the challenge's leaderboard.
Sens-VisualNews: A Benchmark Dataset for Sensational Image Detection
May 11, 2026The detection of sensational content in media items can be a critical filtering mechanism for identifying check-worthy content and flagging potential disinformation, since such content triggers physiological arousal that often bypasses critical evaluation and accelerates viral sharing. In this paper we introduce the task of sensational image detection, which aims to determine whether an image contains shocking, provocative, or emotionally charged features to grab attention and trigger strong emotional responses. To support research on this task, we create a new benchmark dataset (called Sens-VisualNews) that contains 9,576 images from news items, annotated based on the (in-)existence of various sensational concepts and events in their visual content. Finally, using Sens-VisualNews, we study the prompt sensitivity, performance and robustness of a wide range of open SotA Multimodal LLMs, across both zero-shot and fine-tuned settings.
Are All Combinations Equal? Combining Textual and Visual Features with Multiple Space Learning for Text-Based Video Retrieval
Nov 21, 2022In this paper we tackle the cross-modal video retrieval problem and, more specifically, we focus on text-to-video retrieval. We investigate how to optimally combine multiple diverse textual and visual features into feature pairs that lead to generating multiple joint feature spaces, which encode text-video pairs into comparable representations. To learn these representations our proposed network architecture is trained by following a multiple space learning procedure. Moreover, at the retrieval stage, we introduce additional softmax operations for revising the inferred query-video similarities. Extensive experiments in several setups based on three large-scale datasets (IACC.3, V3C1, and MSR-VTT) lead to conclusions on how to best combine text-visual features and document the performance of the proposed network. Source code is made publicly available at: https://github.com/bmezaris/TextToVideoRetrieval-TtimesV
Learning to detect video events from zero or very few video examples
Nov 25, 2015
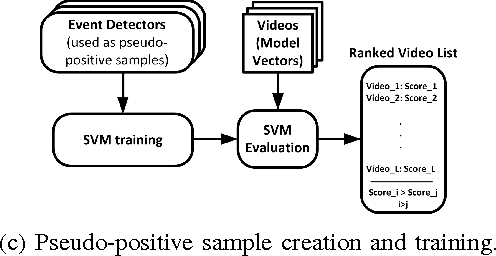
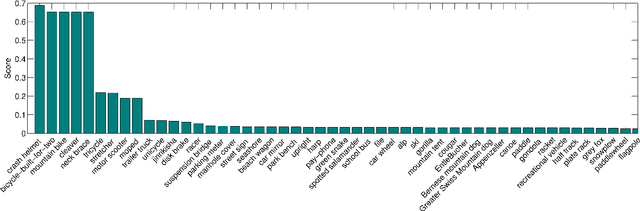
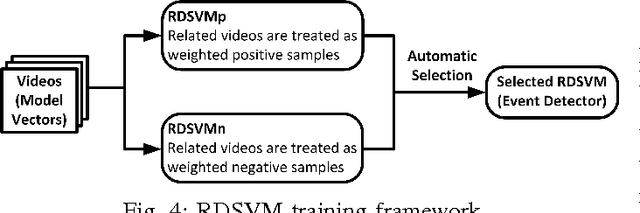
In this work we deal with the problem of high-level event detection in video. Specifically, we study the challenging problems of i) learning to detect video events from solely a textual description of the event, without using any positive video examples, and ii) additionally exploiting very few positive training samples together with a small number of ``related'' videos. For learning only from an event's textual description, we first identify a general learning framework and then study the impact of different design choices for various stages of this framework. For additionally learning from example videos, when true positive training samples are scarce, we employ an extension of the Support Vector Machine that allows us to exploit ``related'' event videos by automatically introducing different weights for subsets of the videos in the overall training set. Experimental evaluations performed on the large-scale TRECVID MED 2014 video dataset provide insight on the effectiveness of the proposed methods.
* Image and Vision Computing Journal, Elsevier, 2015, accepted for publication