 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent experiments through real-time AI: Fast Data Processing and Autonomous Detector Control for sPHENIX and future EIC detectors
Jan 08, 2025This R\&D project, initiated by the DOE Nuclear Physics AI-Machine Learning initiative in 2022, leverages AI to address data processing challenges in high-energy nuclear experiments (RHIC, LHC, and future EIC). Our focus is on developing a demonstrator for real-time processing of high-rate data streams from sPHENIX experiment tracking detectors. The limitations of a 15 kHz maximum trigger rate imposed by the calorimeters can be negated by intelligent use of streaming technology in the tracking system. The approach efficiently identifies low momentum rare heavy flavor events in high-rate p+p collisions (3MHz), using Graph Neural Network (GNN) and High Level Synthesis for Machine Learning (hls4ml). Success at sPHENIX promises immediate benefits, minimizing resources and accelerating the heavy-flavor measurements. The approach is transferable to other fields. For the EIC, we develop a DIS-electron tagger using Artificial Intelligence - Machine Learning (AI-ML) algorithms for real-time identification, showcasing the transformative potential of AI and FPGA technologies in high-energy nuclear and particle experiments real-time data processing pipelines.
Achieving Human Parity in Conversational Speech Recognition
Feb 17, 2017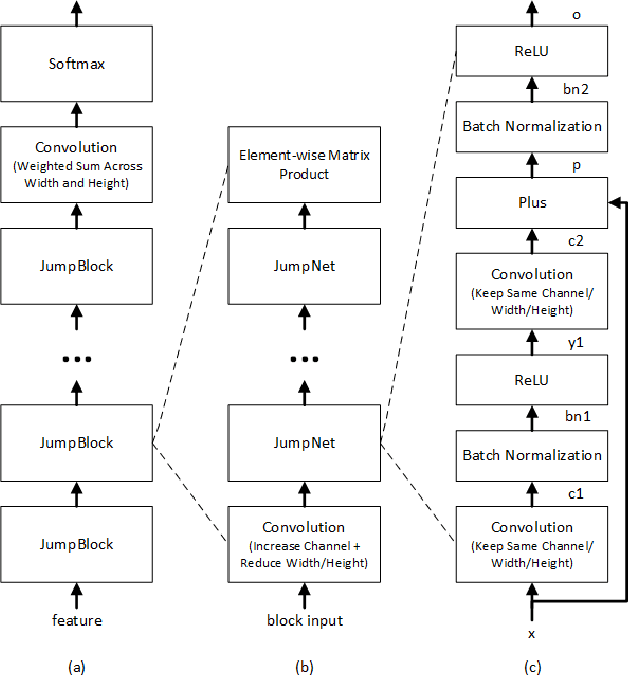
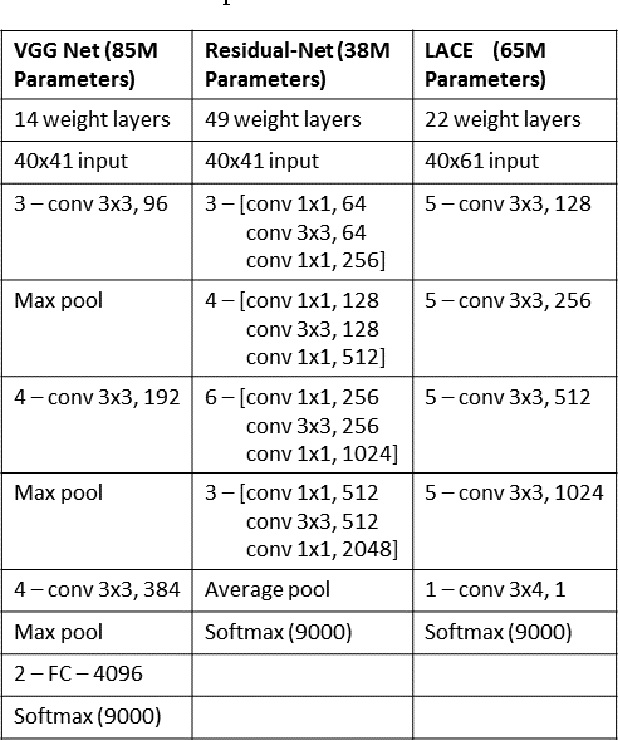
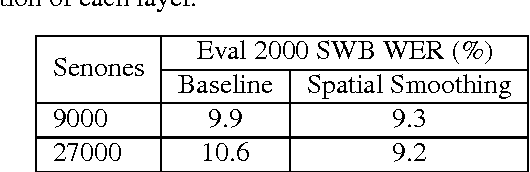
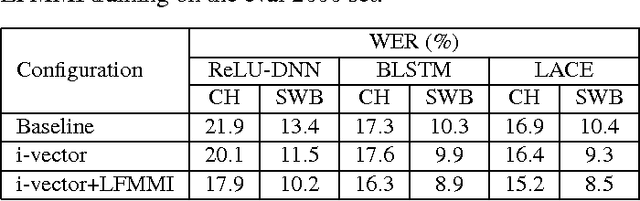
Conversational speech recognition has served as a flagship speech recognition task since the release of the Switchboard corpus in the 1990s. In this paper, we measure the human error rate on the widely used NIST 2000 test set, and find that our latest automated system has reached human parity. The error rate of professional transcribers is 5.9% for the Switchboard portion of the data, in which newly acquainted pairs of people discuss an assigned topic, and 11.3% for the CallHome portion where friends and family members have open-ended conversations. In both cases, our automated system establishes a new state of the art, and edges past the human benchmark, achieving error rates of 5.8% and 11.0%, respectively. The key to our system's performance is the use of various convolutional and LSTM acoustic model architectures, combined with a novel spatial smoothing method and lattice-free MMI acoustic training, multiple recurrent neural network language modeling approaches, and a systematic use of system combination.
The Microsoft 2016 Conversational Speech Recognition System
Jan 25, 2017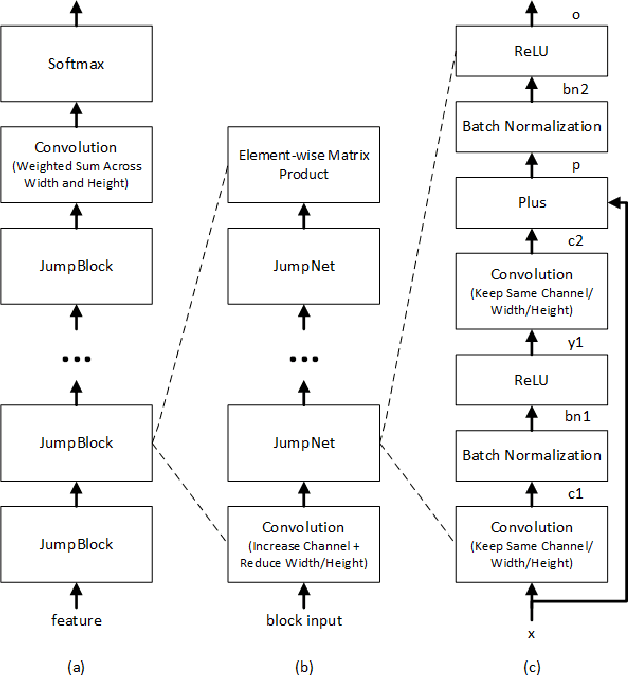
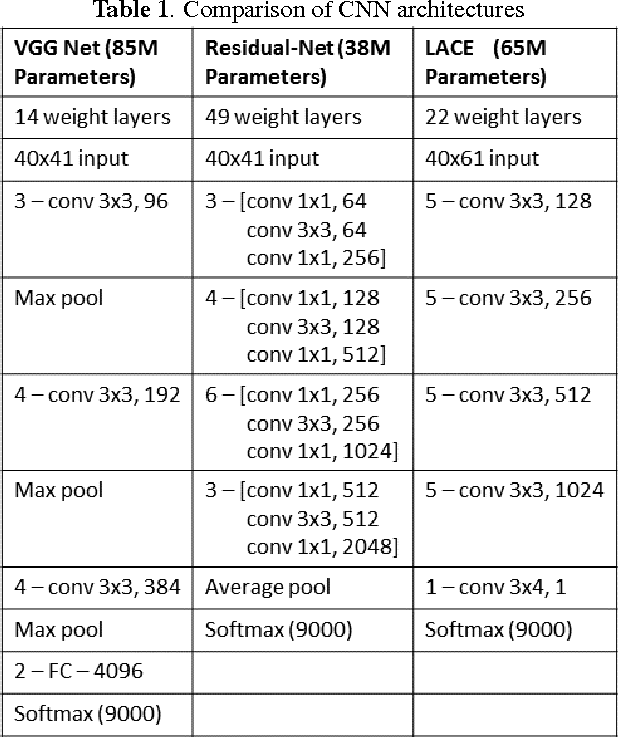
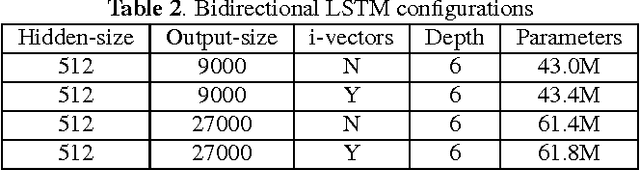
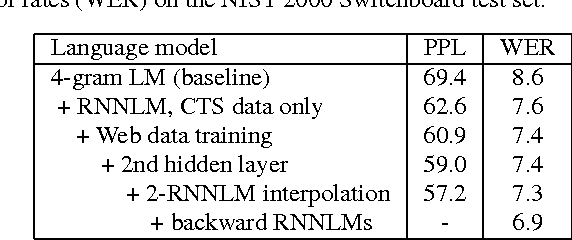
We describe Microsoft's conversational speech recognition system, in which we combine recent developments in neural-network-based acoustic and language modeling to advance the state of the art on the Switchboard recognition task. Inspired by machine learning ensemble techniques, the system uses a range of convolutional and recurrent neural networks. I-vector modeling and lattice-free MMI training provide significant gains for all acoustic model architectures. Language model rescoring with multiple forward and backward running RNNLMs, and word posterior-based system combination provide a 20% boost. The best single system uses a ResNet architecture acoustic model with RNNLM rescoring, and achieves a word error rate of 6.9% on the NIST 2000 Switchboard task. The combined system has an error rate of 6.2%, representing an improvement over previously reported results on this benchmark task.