 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPs at the EOC: Dynamics of Feature Learning
Feb 18, 2025Since infinitely wide neural networks in the kernel regime are random feature models, the success of contemporary deep learning lies in the rich regime, where a satisfying theory should explain not only the convergence of gradient descent but the learning of features along the way. Such a theory should also cover phenomena observed by practicioners including the Edge of Stability (EOS) and the catapult mechanism. For a practically relevant theory in the limit, neural network parameterizations have to efficiently reproduce limiting behavior as width and depth are scaled up. While widthwise scaling is mostly settled, depthwise scaling is solved only at initialization by the Edge of Chaos (EOC). During training, scaling up depth is either done by inversely scaling the learning rate or adding residual connections. We propose $(1)$ the Normalized Update Parameterization ($\nu$P) to solve this issue by growing hidden layer sizes depthwise inducing the regularized evolution of preactivations, $(2)$ a hypothetical explanation for feature learning via the cosine of new and cumulative parameter updates and $(3)$ a geometry-aware learning rate schedule that is able to prolong the catapult phase indefinitely. We support our hypotheses and demonstrate the usefulness of $\nu$P and the learning rate schedule by empirical evidence.
MLPs at the EOC: Concentration of the NTK
Jan 24, 2025
We study the concentration of the Neural Tangent Kernel (NTK) $K_\theta : \mathbb{R}^{m_0} \times \mathbb{R}^{m_0} \to \mathbb{R}^{m_l \times m_l}$ of $l$-layer Multilayer Perceptrons (MLPs) $N : \mathbb{R}^{m_0} \times \Theta \to \mathbb{R}^{m_l}$ equipped with activation functions $\phi(s) = a s + b \vert s \vert$ for some $a,b \in \mathbb{R}$ with the parameter $\theta \in \Theta$ being initialized at the Edge Of Chaos (EOC). Without relying on the gradient independence assumption that has only been shown to hold asymptotically in the infinitely wide limit, we prove that an approximate version of gradient independence holds at finite width. Showing that the NTK entries $K_\theta(x_{i_1},x_{i_2})$ for $i_1,i_2 \in [1:n]$ over a dataset $\{x_1,\cdots,x_n\} \subset \mathbb{R}^{m_0}$ concentrate simultaneously via maximal inequalities, we prove that the NTK matrix $K(\theta) = [\frac{1}{n} K_\theta(x_{i_1},x_{i_2}) : i_1,i_2 \in [1:n]] \in \mathbb{R}^{nm_l \times nm_l}$ concentrates around its infinitely wide limit $\overset{\scriptscriptstyle\infty}{K} \in \mathbb{R}^{nm_l \times nm_l}$ without the need for linear overparameterization. Our results imply that in order to accurately approximate the limit, hidden layer widths have to grow quadratically as $m_k = k^2 m$ for some $m \in \mathbb{N}+1$ for sufficient concentration. For such MLPs, we obtain the concentration bound $\mathbb{P}( \Vert K(\theta) - \overset{\scriptscriptstyle\infty}{K} \Vert \leq O((\Delta_\phi^{-2} + m_l^{\frac{1}{2}} l) \kappa_\phi^2 m^{-\frac{1}{2}})) \geq 1-O(m^{-1})$ modulo logarithmic terms, where we denoted $\Delta_\phi = \frac{b^2}{a^2+b^2}$ and $\kappa_\phi = \frac{\vert a \vert + \vert b \vert}{\sqrt{a^2 + b^2}}$. This reveals in particular that the absolute value ($\Delta_\phi=1$, $\kappa_\phi=1$) beats the ReLU ($\Delta_\phi=\frac{1}{2}$, $\kappa_\phi=\sqrt{2}$) in terms of the concentration of the NTK.
A framework for overparameterized learning
May 26, 2022An explanation for the success of deep neural networks is a central question in theoretical machine learning. According to classical statistical learning, the overparameterized nature of such models should imply a failure to generalize. Many argue that good empirical performance is due to the implicit regularization of first order optimization methods. In particular, the Polyak-{\L}ojasiewicz condition leads to gradient descent finding a global optimum that is close to initialization. In this work, we propose a framework consisting of a prototype learning problem, which is general enough to cover many popular problems and even the cases of infinitely wide neural networks and infinite data. We then perform an analysis from the perspective of the Polyak-{\L}ojasiewicz condition. We obtain theoretical results of independent interest, concerning gradient descent on a composition $(f \circ F): G \to \mathbb{R}$ of functions $F: G \to H$ and $f: H \to \mathbb{R}$ with $G, H$ being Hilbert spaces. Building on these results, we determine the properties that have to be satisfied by the components of the prototype problem for gradient descent to find a global optimum that is close to initialization. We then demonstrate that supervised learning, variational autoencoders and training with gradient penalty can be translated to the prototype problem. Finally, we lay out a number of directions for future research.
Optimal transport with $f$-divergence regularization and generalized Sinkhorn algorithm
May 29, 2021
Entropic regularization provides a generalization of the original optimal transport problem. It introduces a penalty term defined by the Kullback-Leibler divergence, making the problem more tractable via the celebrated Sinkhorn algorithm. Replacing the Kullback-Leibler divergence with a general $f$-divergence leads to a natural generalization. Using convex analysis, we extend the theory developed so far to include $f$-divergences defined by functions of Legendre type, and prove that under some mild conditions, strong duality holds, optimums in both the primal and dual problems are attained, the generalization of the $c$-transform is well-defined, and we give sufficient conditions for the generalized Sinkhorn algorithm to converge to an optimal solution. We propose a practical algorithm for computing the regularized optimal transport cost and its gradient via the generalized Sinkhorn algorithm. Finally, we present experimental results on synthetic 2-dimensional data, demonstrating the effects of using different $f$-divergences for regularization, which influences convergence speed, numerical stability and sparsity of the optimal coupling.
Moreau-Yosida $f$-divergences
Feb 26, 2021
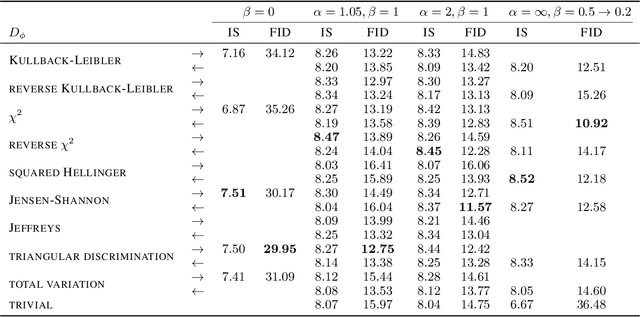


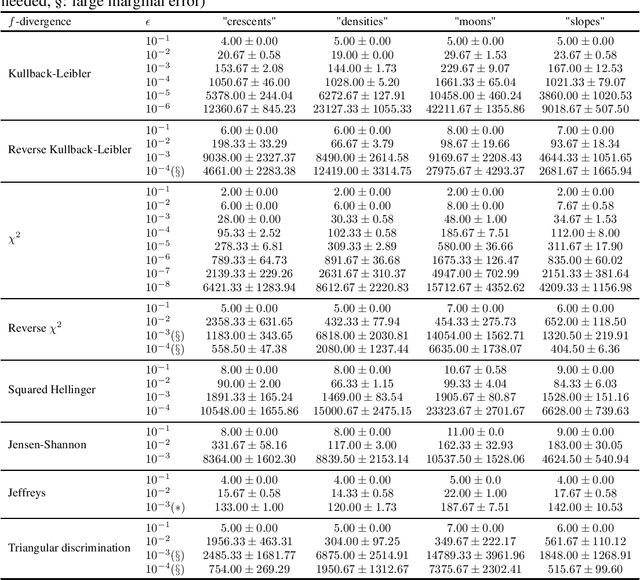
Variational representations of $f$-divergences are central to many machine learning algorithms, with Lipschitz constrained variants recently gaining attention. Inspired by this, we generalize the so-called tight variational representation of $f$-divergences in the case of probability measures on compact metric spaces to be taken over the space of Lipschitz functions vanishing at an arbitrary base point, characterize functions achieving the supremum in the variational representation, propose a practical algorithm to calculate the tight convex conjugate of $f$-divergences compatible with automatic differentiation frameworks, define the Moreau-Yosida approximation of $f$-divergences with respect to the Wasserstein-$1$ metric, and derive the corresponding variational formulas, providing a generalization of a number of recent results, novel special cases of interest and a relaxation of the hard Lipschitz constraint. As an application of our theoretical results, we propose the Moreau-Yosida $f$-GAN, providing an implementation of the variational formulas for the Kullback-Leibler, reverse Kullback-Leibler, $\chi^2$, reverse $\chi^2$, squared Hellinger, Jensen-Shannon, Jeffreys, triangular discrimination and total variation divergences as GANs trained on CIFAR-10, leading to competitive results and a simple solution to the problem of uniqueness of the optimal critic.
Virtual Adversarial Lipschitz Regularization
Jul 12, 2019
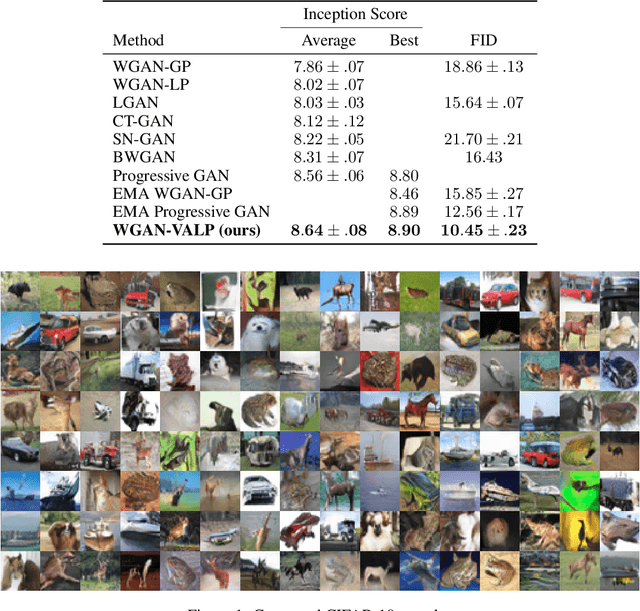
Generative adversarial networks (GANs) are one of the most popular approaches when it comes to training generative models, among which variants of Wasserstein GANs are considered superior to the standard GAN formulation in terms of learning stability and sample quality. However, Wasserstein GANs require the critic to be K-Lipschitz, which is often enforced implicitly by penalizing the norm of its gradient, or by globally restricting its Lipschitz constant via weight normalization techniques. Training with a regularization term penalizing the violation of the Lipschitz constraint explicitly, instead of through the norm of the gradient, was found to be practically infeasible in most situations. With a novel generalization of Virtual Adversarial Training, called Virtual Adversarial Lipschitz Regularization, we show that using an explicit Lipschitz penalty is indeed viable and leads to state-of-the-art performance in terms of Inception Score and Fr\'echet Inception Distance when applied to Wasserstein GANs trained on CIFAR-10.