 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Global AI Regulation: A Multi-Jurisdictional Retrieval-Augmented Generation System
Apr 28, 2026Navigating AI regulation across jurisdictions is increasingly difficult for policymakers, legal professionals, and researchers. To address this, we present a multi-jurisdictional Retrieval-Augmented Generation system for global AI regulation. Our corpus includes 242 documents across 68 jurisdictions, ranging from formal legislation like the EU AI Act to unstructured policy documents such as national AI strategies. The system makes three technical contributions: type-specific chunking that preserve legal structure across heterogenous documents; conditional retrieval routing with entity detection and metadata for legal citations; and priority-based re-ranking to boost enacted legislation over policy and secondary sources. Evaluation of 50 queries reveals strong performance across both single-entity and multi-jurisdictional questions, achieving 0.87 average faithfulness and 0.84 average answer relevancy. Single-entity queries achieve 0.86 average faithfulness and 0.92 average answer relevancy, while multi-jurisdictional comparison queries achieve 0.88 average faithfulness and 0.75 average answer relevancy. These findings highlight the effectiveness of domain-specific retrieval strategies for navigating complex, heterogenous regulatory corpora.
Explaining Classifications to Non Experts: An XAI User Study of Post Hoc Explanations for a Classifier When People Lack Expertise
Dec 19, 2022Very few eXplainable AI (XAI) studies consider how users understanding of explanations might change depending on whether they know more or less about the to be explained domain (i.e., whether they differ in their expertise). Yet, expertise is a critical facet of most high stakes, human decision making (e.g., understanding how a trainee doctor differs from an experienced consultant). Accordingly, this paper reports a novel, user study (N=96) on how peoples expertise in a domain affects their understanding of post-hoc explanations by example for a deep-learning, black box classifier. The results show that peoples understanding of explanations for correct and incorrect classifications changes dramatically, on several dimensions (e.g., response times, perceptions of correctness and helpfulness), when the image-based domain considered is familiar (i.e., MNIST) as opposed to unfamiliar (i.e., Kannada MNIST). The wider implications of these new findings for XAI strategies are discussed.
Play MNIST For Me! User Studies on the Effects of Post-Hoc, Example-Based Explanations & Error Rates on Debugging a Deep Learning, Black-Box Classifier
Sep 10, 2020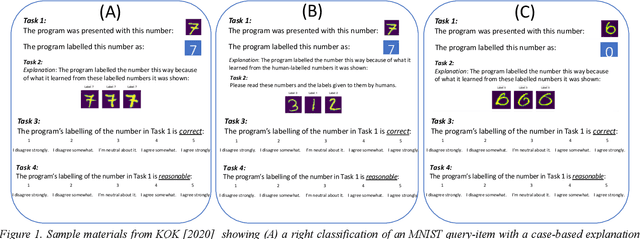
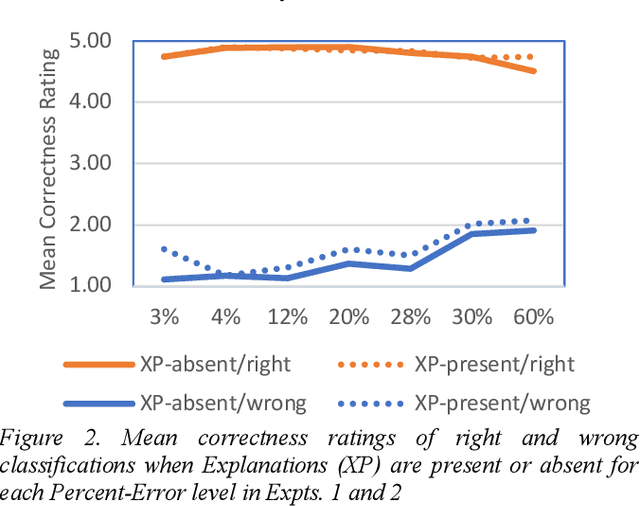
This paper reports two experiments (N=349) on the impact of post hoc explanations by example and error rates on peoples perceptions of a black box classifier. Both experiments show that when people are given case based explanations, from an implemented ANN CBR twin system, they perceive miss classifications to be more correct. They also show that as error rates increase above 4%, people trust the classifier less and view it as being less correct, less reasonable and less trustworthy. The implications of these results for XAI are discussed.
* 2 Figures, 1 Table, 8 pages