 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Learning, with or without Labels
Dec 30, 2019

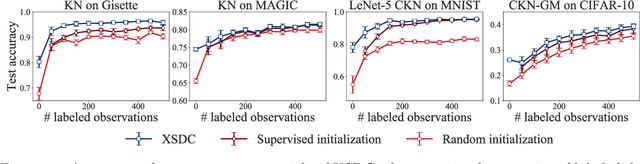
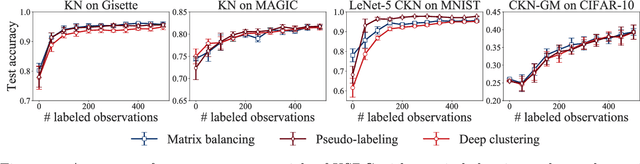
We present an approach for end-to-end learning that allows one to jointly learn a feature representation from unlabeled data (with or without labeled data) and predict labels for unlabeled data. The feature representation is assumed to be specified in a differentiable programming framework, that is, as a parameterized mapping amenable to automatic differentiation. The proposed approach can be used with any amount of labeled and unlabeled data, gracefully adjusting to the amount of supervision. We provide experimental results illustrating the effectiveness of the approach.
Kernel-based Translations of Convolutional Networks
Mar 19, 2019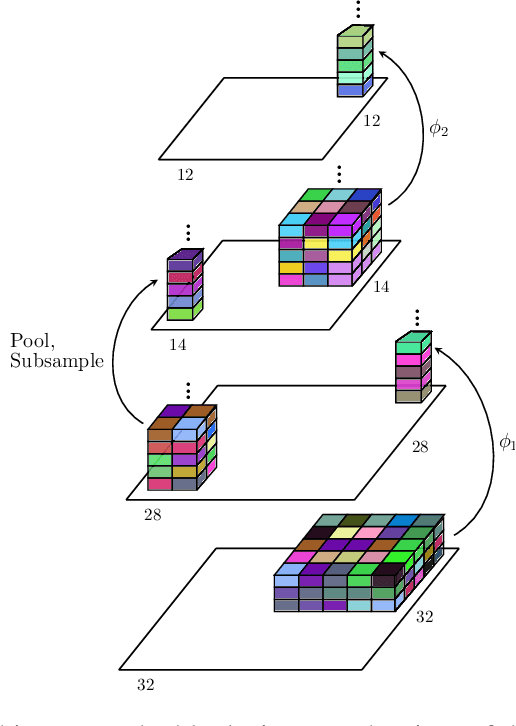

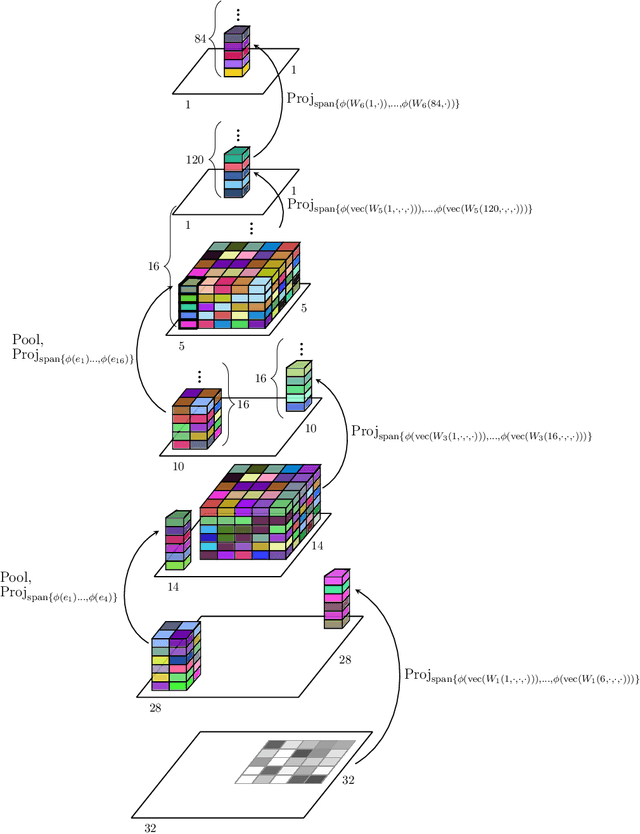
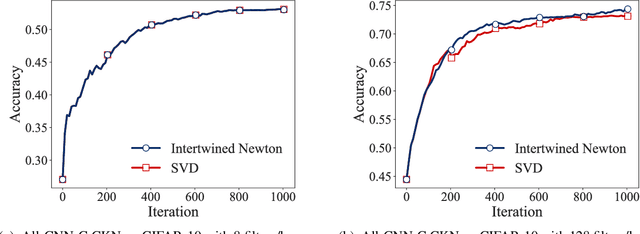
Convolutional Neural Networks, as most artificial neural networks, are commonly viewed as methods different in essence from kernel-based methods. We provide a systematic translation of Convolutional Neural Networks (ConvNets) into their kernel-based counterparts, Convolutional Kernel Networks (CKNs), and demonstrate that this perception is unfounded both formally and empirically. We show that, given a Convolutional Neural Network, we can design a corresponding Convolutional Kernel Network, easily trainable using a new stochastic gradient algorithm based on an accurate gradient computation, that performs on par with its Convolutional Neural Network counterpart. We present experimental results supporting our claims on landmark ConvNet architectures comparing each ConvNet to its CKN counterpart over several parameter settings.