 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment-Aware Measure (SAM) for Evaluating Sentiment Transfer by Machine Translation Systems
Oct 05, 2021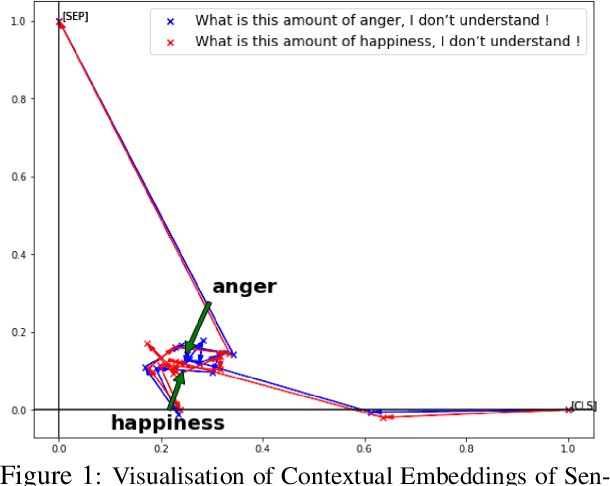

In translating text where sentiment is the main message, human translators give particular attention to sentiment-carrying words. The reason is that an incorrect translation of such words would miss the fundamental aspect of the source text, i.e. the author's sentiment. In the online world, MT systems are extensively used to translate User-Generated Content (UGC) such as reviews, tweets, and social media posts, where the main message is often the author's positive or negative attitude towards the topic of the text. It is important in such scenarios to accurately measure how far an MT system can be a reliable real-life utility in transferring the correct affect message. This paper tackles an under-recognised problem in the field of machine translation evaluation which is judging to what extent automatic metrics concur with the gold standard of human evaluation for a correct translation of sentiment. We evaluate the efficacy of conventional quality metrics in spotting a mistranslation of sentiment, especially when it is the sole error in the MT output. We propose a numerical `sentiment-closeness' measure appropriate for assessing the accuracy of a translated affect message in UGC text by an MT system. We will show that incorporating this sentiment-aware measure can significantly enhance the correlation of some available quality metrics with the human judgement of an accurate translation of sentiment.
* Accepted for RANLP (Recent Advances in Natural Language Processing) 2021
BLEU, METEOR, BERTScore: Evaluation of Metrics Performance in Assessing Critical Translation Errors in Sentiment-oriented Text
Sep 29, 2021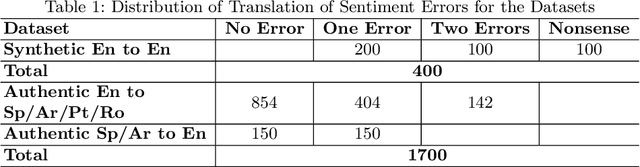
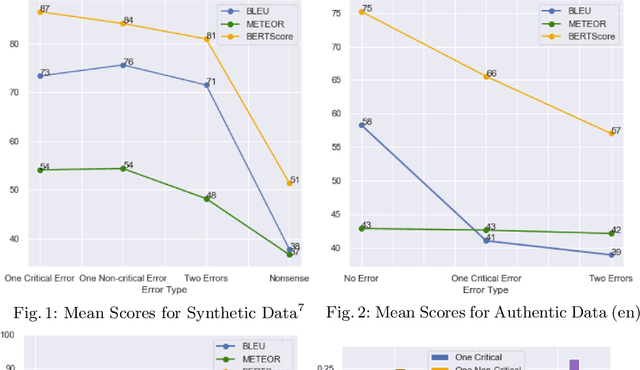
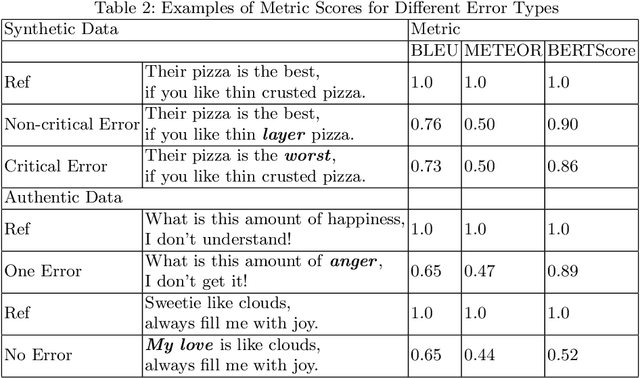
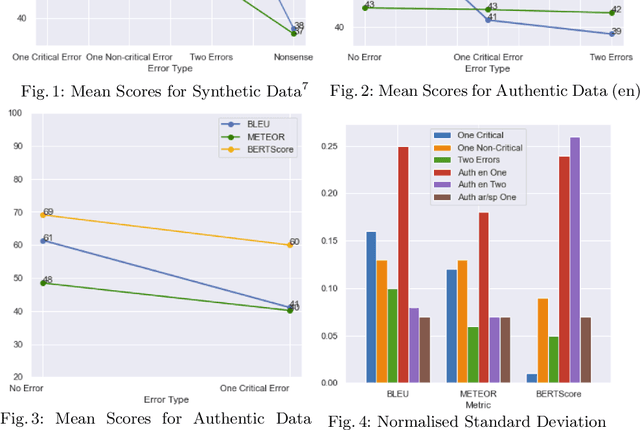
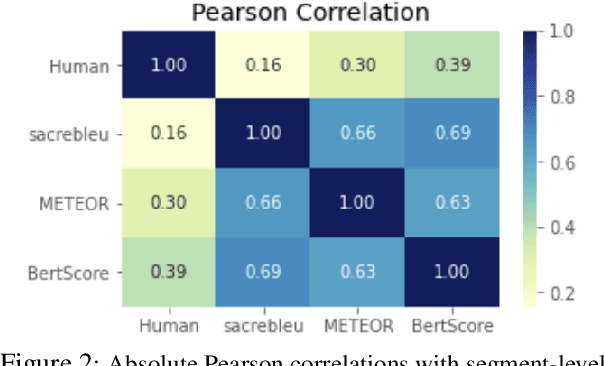
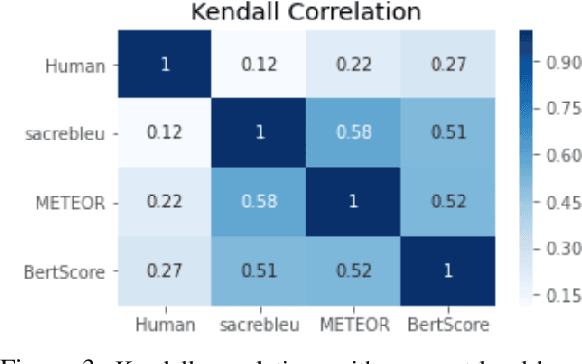
Social media companies as well as authorities make extensive use of artificial intelligence (AI) tools to monitor postings of hate speech, celebrations of violence or profanity. Since AI software requires massive volumes of data to train computers, Machine Translation (MT) of the online content is commonly used to process posts written in several languages and hence augment the data needed for training. However, MT mistakes are a regular occurrence when translating sentiment-oriented user-generated content (UGC), especially when a low-resource language is involved. The adequacy of the whole process relies on the assumption that the evaluation metrics used give a reliable indication of the quality of the translation. In this paper, we assess the ability of automatic quality metrics to detect critical machine translation errors which can cause serious misunderstanding of the affect message. We compare the performance of three canonical metrics on meaningless translations where the semantic content is seriously impaired as compared to meaningful translations with a critical error which exclusively distorts the sentiment of the source text. We conclude that there is a need for fine-tuning of automatic metrics to make them more robust in detecting sentiment critical errors.
* Accepted for TRITON (TRanslation and Interpreting Technology ONline) 2021
Challenges in Translation of Emotions in Multilingual User-Generated Content: Twitter as a Case Study
Jun 20, 2021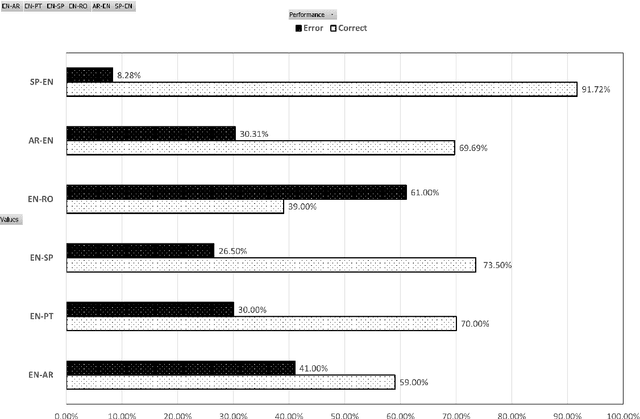
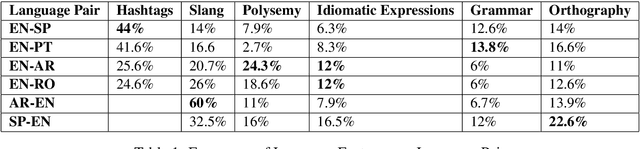
Although emotions are universal concepts, transferring the different shades of emotion from one language to another may not always be straightforward for human translators, let alone for machine translation systems. Moreover, the cognitive states are established by verbal explanations of experience which is shaped by both the verbal and cultural contexts. There are a number of verbal contexts where expression of emotions constitutes the pivotal component of the message. This is particularly true for User-Generated Content (UGC) which can be in the form of a review of a product or a service, a tweet, or a social media post. Recently, it has become common practice for multilingual websites such as Twitter to provide an automatic translation of UGC to reach out to their linguistically diverse users. In such scenarios, the process of translating the user's emotion is entirely automatic with no human intervention, neither for post-editing nor for accuracy checking. In this research, we assess whether automatic translation tools can be a successful real-life utility in transferring emotion in user-generated multilingual data such as tweets. We show that there are linguistic phenomena specific of Twitter data that pose a challenge in translation of emotions in different languages. We summarise these challenges in a list of linguistic features and show how frequent these features are in different language pairs. We also assess the capacity of commonly used methods for evaluating the performance of an MT system with respect to the preservation of emotion in the source text.
An Exploratory Analysis of Multilingual Word-Level Quality Estimation with Cross-Lingual Transformers
May 31, 2021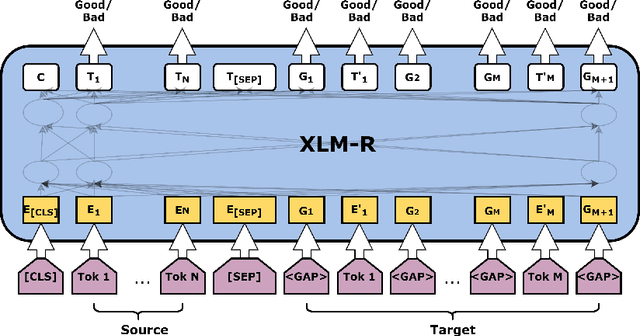
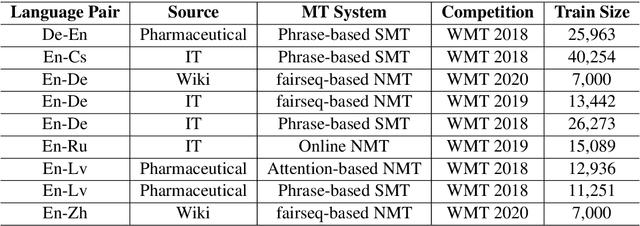
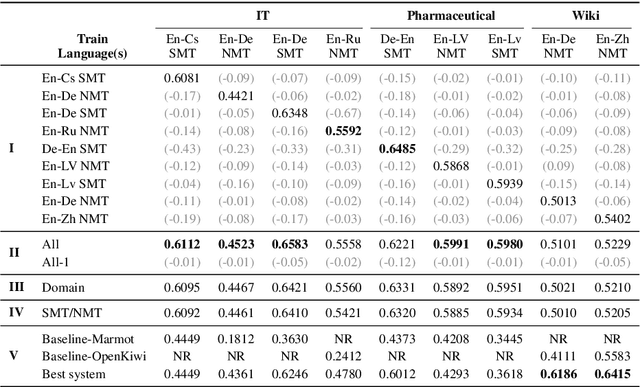
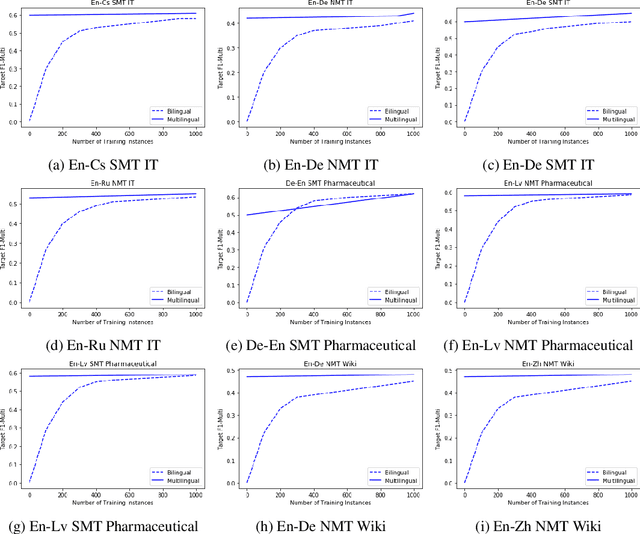
Most studies on word-level Quality Estimation (QE) of machine translation focus on language-specific models. The obvious disadvantages of these approaches are the need for labelled data for each language pair and the high cost required to maintain several language-specific models. To overcome these problems, we explore different approaches to multilingual, word-level QE. We show that these QE models perform on par with the current language-specific models. In the cases of zero-shot and few-shot QE, we demonstrate that it is possible to accurately predict word-level quality for any given new language pair from models trained on other language pairs. Our findings suggest that the word-level QE models based on powerful pre-trained transformers that we propose in this paper generalise well across languages, making them more useful in real-world scenarios.
TransQuest: Translation Quality Estimation with Cross-lingual Transformers
Nov 04, 2020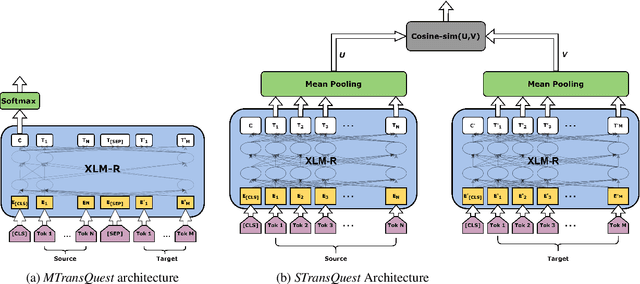
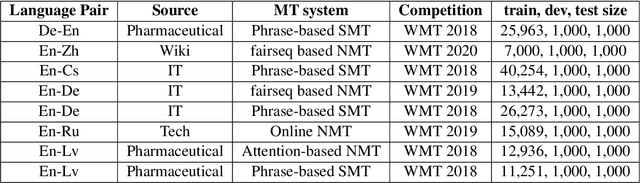
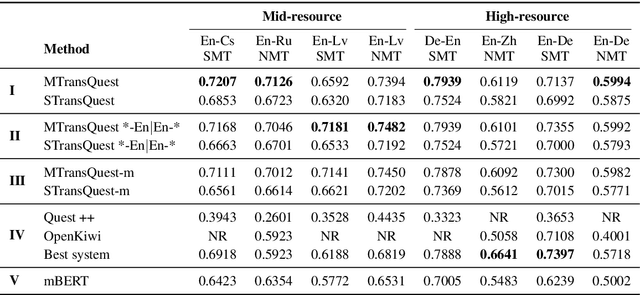
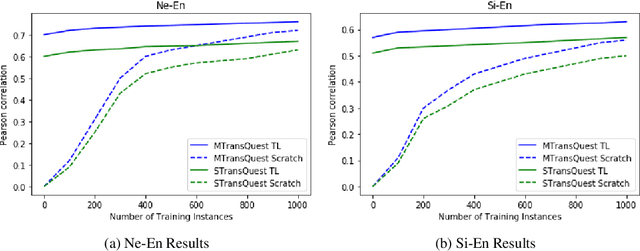
Recent years have seen big advances in the field of sentence-level quality estimation (QE), largely as a result of using neural-based architectures. However, the majority of these methods work only on the language pair they are trained on and need retraining for new language pairs. This process can prove difficult from a technical point of view and is usually computationally expensive. In this paper we propose a simple QE framework based on cross-lingual transformers, and we use it to implement and evaluate two different neural architectures. Our evaluation shows that the proposed methods achieve state-of-the-art results outperforming current open-source quality estimation frameworks when trained on datasets from WMT. In addition, the framework proves very useful in transfer learning settings, especially when dealing with low-resourced languages, allowing us to obtain very competitive results.
Fake or Real? A Study of Arabic Satirical Fake News
Nov 01, 2020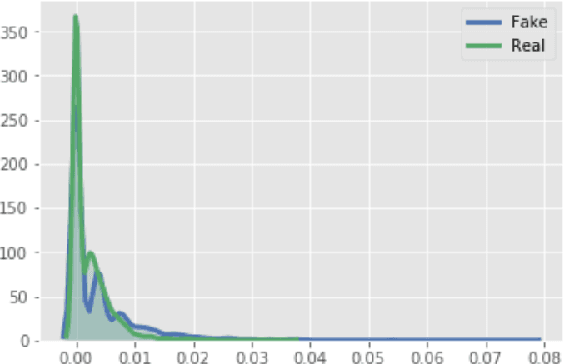
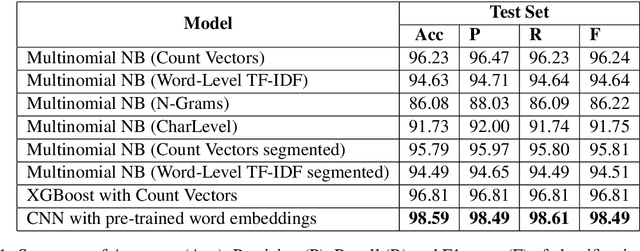
One very common type of fake news is satire which comes in a form of a news website or an online platform that parodies reputable real news agencies to create a sarcastic version of reality. This type of fake news is often disseminated by individuals on their online platforms as it has a much stronger effect in delivering criticism than through a straightforward message. However, when the satirical text is disseminated via social media without mention of its source, it can be mistaken for real news. This study conducts several exploratory analyses to identify the linguistic properties of Arabic fake news with satirical content. We exploit these features to build a number of machine learning models capable of identifying satirical fake news with an accuracy of up to 98.6%.
Is it Great or Terrible? Preserving Sentiment in Neural Machine Translation of Arabic Reviews
Oct 26, 2020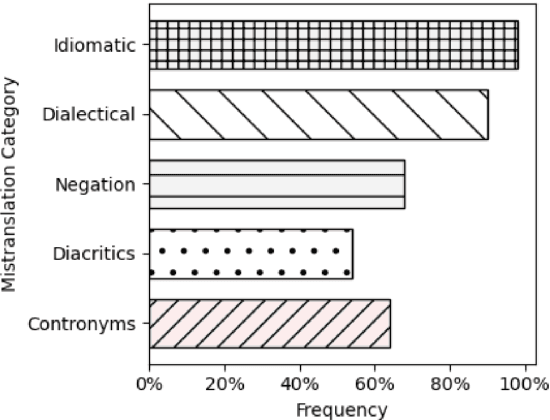
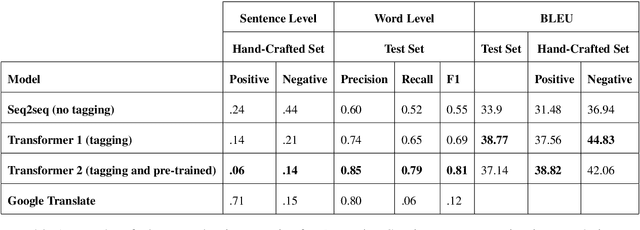
Since the advent of Neural Machine Translation (NMT) approaches there has been a tremendous improvement in the quality of automatic translation. However, NMT output still lacks accuracy in some low-resource languages and sometimes makes major errors that need extensive post-editing. This is particularly noticeable with texts that do not follow common lexico-grammatical standards, such as user generated content (UGC). In this paper we investigate the challenges involved in translating book reviews from Arabic into English, with particular focus on the errors that lead to incorrect translation of sentiment polarity. Our study points to the special characteristics of Arabic UGC, examines the sentiment transfer errors made by Google Translate of Arabic UGC to English, analyzes why the problem occurs, and proposes an error typology specific of the translation of Arabic UGC. Our analysis shows that the output of online translation tools of Arabic UGC can either fail to transfer the sentiment at all by producing a neutral target text, or completely flips the sentiment polarity of the target word or phrase and hence delivers a wrong affect message. We address this problem by fine-tuning an NMT model with respect to sentiment polarity showing that this approach can significantly help with correcting sentiment errors detected in the online translation of Arabic UGC.
RGCL at SemEval-2020 Task 6: Neural Approaches to Definition Extraction
Oct 13, 2020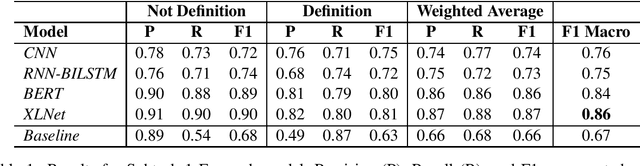
This paper presents the RGCL team submission to SemEval 2020 Task 6: DeftEval, subtasks 1 and 2. The system classifies definitions at the sentence and token levels. It utilises state-of-the-art neural network architectures, which have some task-specific adaptations, including an automatically extended training set. Overall, the approach achieves acceptable evaluation scores, while maintaining flexibility in architecture selection.
TransQuest at WMT2020: Sentence-Level Direct Assessment
Oct 11, 2020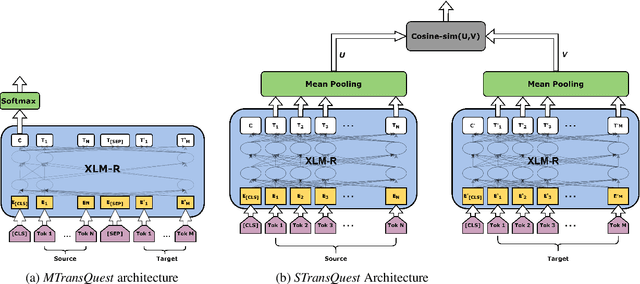
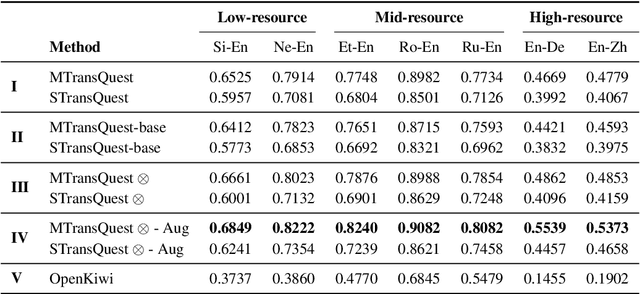
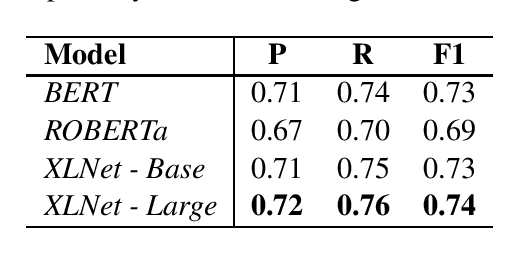
This paper presents the team TransQuest's participation in Sentence-Level Direct Assessment shared task in WMT 2020. We introduce a simple QE framework based on cross-lingual transformers, and we use it to implement and evaluate two different neural architectures. The proposed methods achieve state-of-the-art results surpassing the results obtained by OpenKiwi, the baseline used in the shared task. We further fine tune the QE framework by performing ensemble and data augmentation. Our approach is the winning solution in all of the language pairs according to the WMT 2020 official results.
Intelligent Translation Memory Matching and Retrieval with Sentence Encoders
Apr 27, 2020

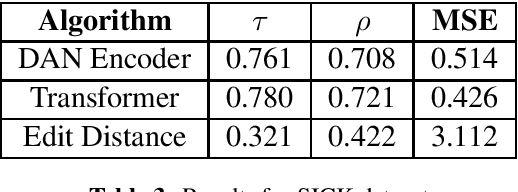
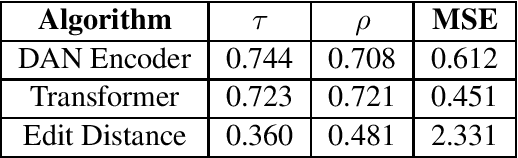
Matching and retrieving previously translated segments from a Translation Memory is the key functionality in Translation Memories systems. However this matching and retrieving process is still limited to algorithms based on edit distance which we have identified as a major drawback in Translation Memories systems. In this paper we introduce sentence encoders to improve the matching and retrieving process in Translation Memories systems - an effective and efficient solution to replace edit distance based algorithms.