 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrand New K-FACs: Speeding up K-FAC with Online Decomposition Updates
Oct 16, 2022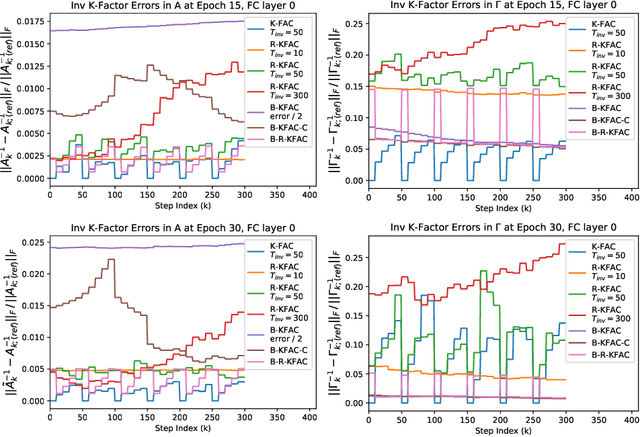
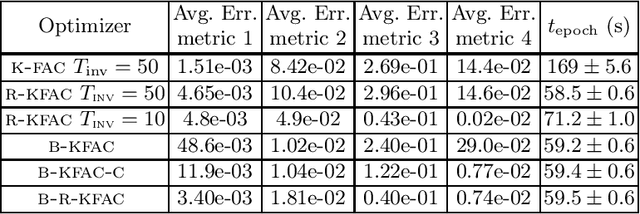
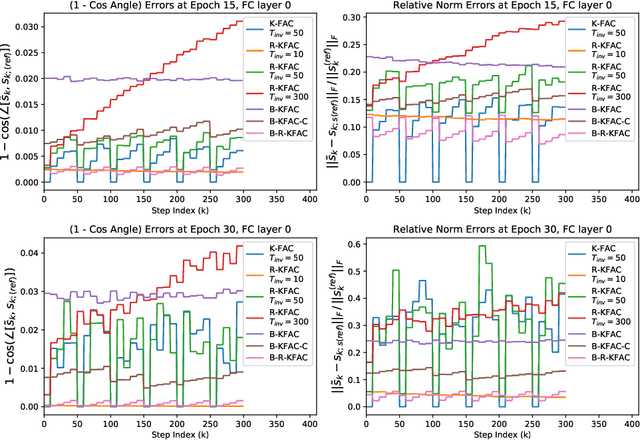
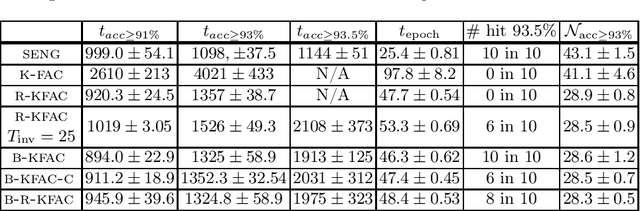
K-FAC (arXiv:1503.05671, arXiv:1602.01407) is a tractable implementation of Natural Gradient (NG) for Deep Learning (DL), whose bottleneck is computing the inverses of the so-called ``Kronecker-Factors'' (K-factors). RS-KFAC (arXiv:2206.15397) is a K-FAC improvement which provides a cheap way of estimating the K-factors inverses. In this paper, we exploit the exponential-average construction paradigm of the K-factors, and use online numerical linear algebra techniques to propose an even cheaper (but less accurate) way of estimating the K-factors inverses for Fully Connected layers. Numerical results show RS-KFAC's inversion error can be reduced with minimal CPU overhead by adding our proposed update to it. Based on the proposed procedure, a correction to it, and RS-KFAC, we propose three practical algorithms for optimizing generic Deep Neural Nets. Numerical results show that two of these outperform RS-KFAC for any target test accuracy on CIFAR10 classification with a slightly modified version of VGG16_bn. Our proposed algorithms achieve 91$\%$ test accuracy faster than SENG (the state of art implementation of empirical NG for DL; arXiv:2006.05924) but underperform it for higher test-accuracy.
Randomized K-FACs: Speeding up K-FAC with Randomized Numerical Linear Algebra
Jun 30, 2022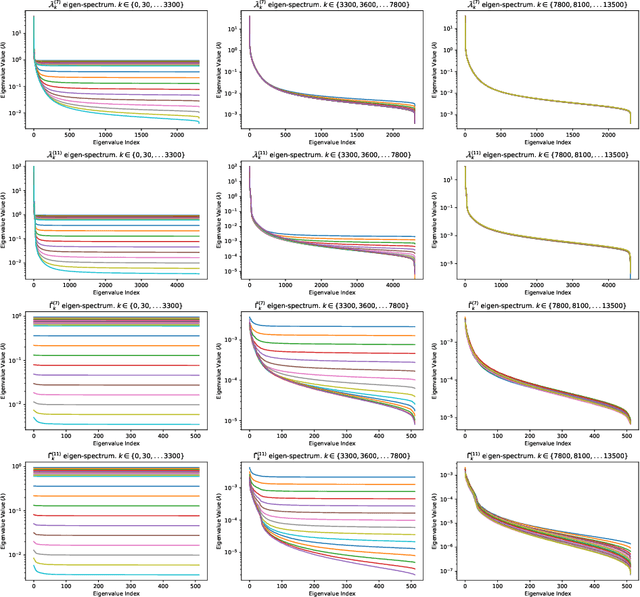

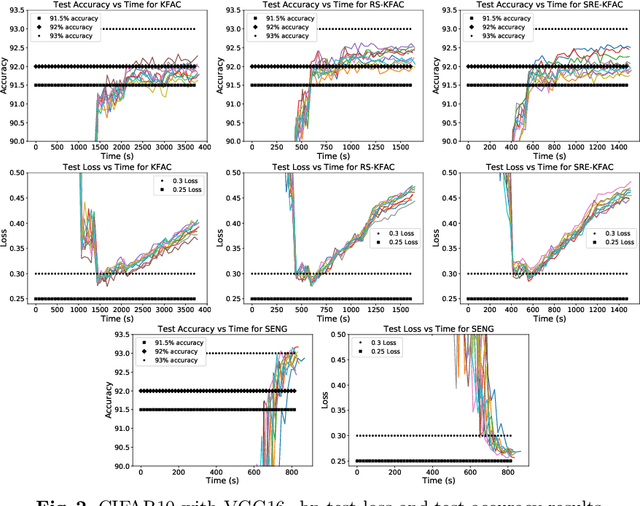
K-FAC is a successful tractable implementation of Natural Gradient for Deep Learning, which nevertheless suffers from the requirement to compute the inverse of the Kronecker factors (through an eigen-decomposition). This can be very time-consuming (or even prohibitive) when these factors are large. In this paper, we theoretically show that, owing to the exponential-average construction paradigm of the Kronecker factors that is typically used, their eigen-spectrum must decay. We show numerically that in practice this decay is very rapid, leading to the idea that we could save substantial computation by only focusing on the first few eigen-modes when inverting the Kronecker-factors. Randomized Numerical Linear Algebra provides us with the necessary tools to do so. Numerical results show we obtain $\approx2.5\times$ reduction in per-epoch time and $\approx3.3\times$ reduction in time to target accuracy. We compare our proposed K-FAC sped-up versions with a more computationally efficient NG implementation, SENG, and observe we perform on par with it.
Rethinking Exponential Averaging of the Fisher
Apr 10, 2022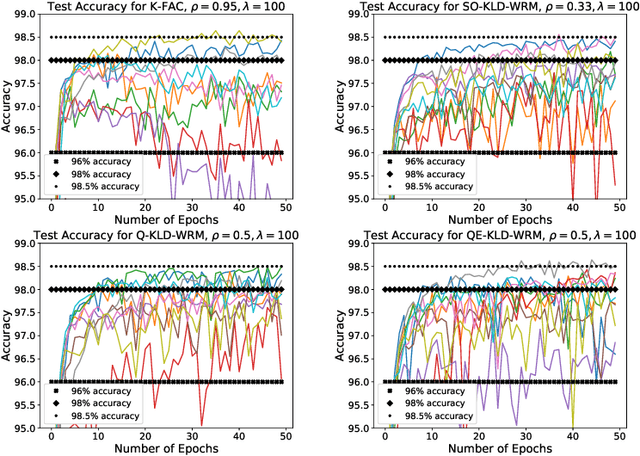
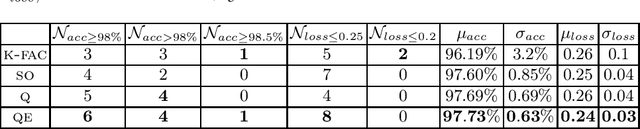
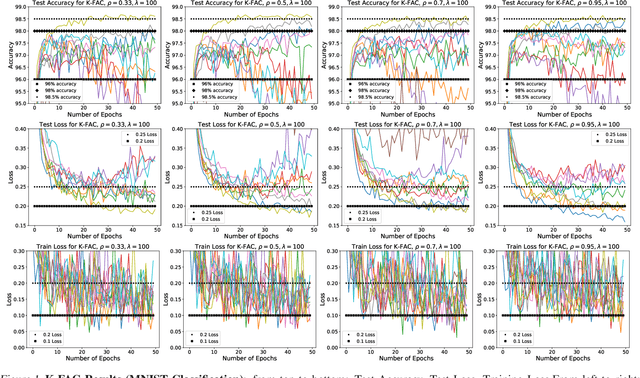
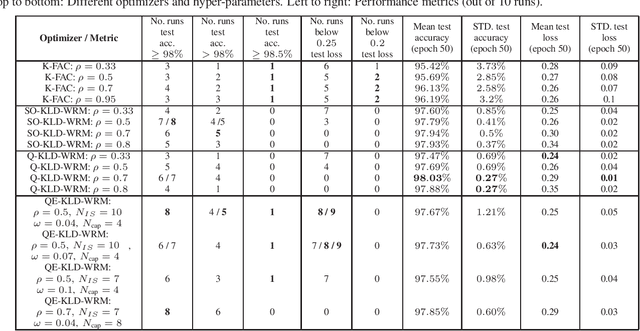
In optimization for Machine learning (ML), it is typical that curvature-matrix (CM) estimates rely on an exponential average (EA) of local estimates (giving EA-CM algorithms). This approach has little principled justification, but is very often used in practice. In this paper, we draw a connection between EA-CM algorithms and what we call a "Wake of Quadratic regularized models". The outlined connection allows us to understand what EA-CM algorithms are doing from an optimization perspective. Generalizing from the established connection, we propose a new family of algorithms, "KL-Divergence Wake-Regularized Models" (KLD-WRM). We give three different practical instantiations of KLD-WRM, and show numerical results where we outperform K-FAC.