 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Formal Natural Language Specifications
Oct 05, 2023Interactive proof assistants are computer programs carefully constructed to check a human-designed proof of a mathematical claim with high confidence in the implementation. However, this only validates truth of a formal claim, which may have been mistranslated from a claim made in natural language. This is especially problematic when using proof assistants to formally verify the correctness of software with respect to a natural language specification. The translation from informal to formal remains a challenging, time-consuming process that is difficult to audit for correctness. This paper shows that it is possible to build support for specifications written in expressive subsets of natural language, within existing proof assistants, consistent with the principles used to establish trust and auditability in proof assistants themselves. We implement a means to provide specifications in a modularly extensible formal subset of English, and have them automatically translated into formal claims, entirely within the Lean proof assistant. Our approach is extensible (placing no permanent restrictions on grammatical structure), modular (allowing information about new words to be distributed alongside libraries), and produces proof certificates explaining how each word was interpreted and how the sentence's structure was used to compute the meaning. We apply our prototype to the translation of various English descriptions of formal specifications from a popular textbook into Lean formalizations; all can be translated correctly with a modest lexicon with only minor modifications related to lexicon size.
* arXiv admin note: substantial text overlap with arXiv:2205.07811
Preprocessing Source Code Comments for Linguistic Models
Aug 26, 2022
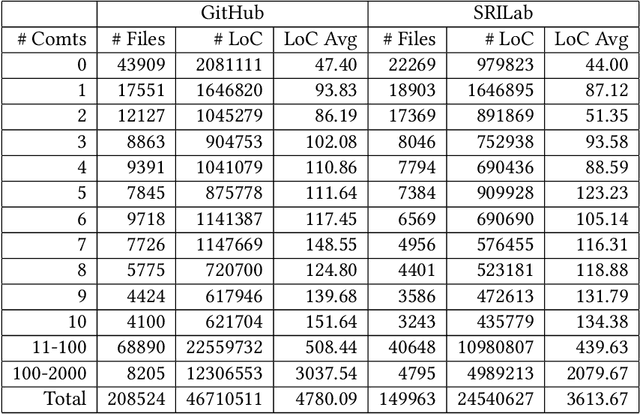
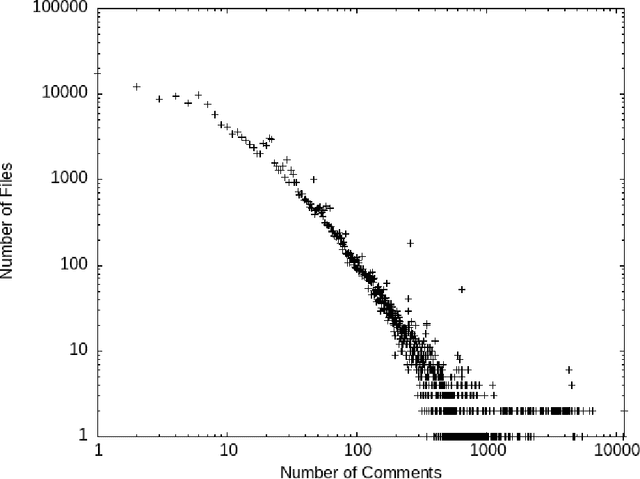
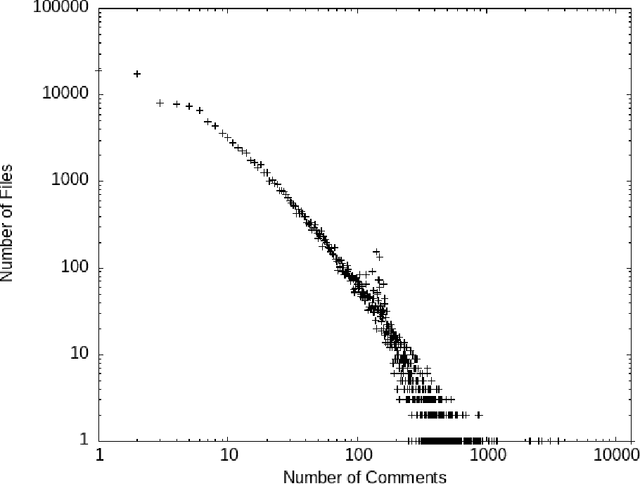
Comments are an important part of the source code and are a primary source of documentation. This has driven interest in using large bodies of comments to train or evaluate tools that consume or produce them -- such as generating oracles or even code from comments, or automatically generating code summaries. Most of this work makes strong assumptions about the structure and quality of comments, such as assuming they consist mostly of proper English sentences. However, we know little about the actual quality of existing comments for these use cases. Comments often contain unique structures and elements that are not seen in other types of text, and filtering or extracting information from them requires some extra care. This paper explores the contents and quality of Python comments drawn from 840 most popular open source projects from GitHub and 8422 projects from SriLab dataset, and the impact of na\"ive vs. in-depth filtering can have on the use of existing comments for training and evaluation of systems that generate comments.
Natural Language Specifications in Proof Assistants
May 16, 2022

Interactive proof assistants are computer programs carefully constructed to check a human-designed proof of a mathematical claim with high confidence in the implementation. However, this only validates truth of a formal claim, which may have been mistranslated from a claim made in natural language. This is especially problematic when using proof assistants to formally verify the correctness of software with respect to a natural language specification. The translation from informal to formal remains a challenging, time-consuming process that is difficult to audit for correctness. This paper argues that it is possible to build support for natural language specifications within existing proof assistants, in a way that complements the principles used to establish trust and auditability in proof assistants themselves.
Towards Property-Based Tests in Natural Language
Feb 08, 2022

We consider a new approach to generate tests from natural language. Rather than relying on machine learning or templated extraction from structured comments, we propose to apply classic ideas from linguistics to translate natural-language sentences into executable tests. This paper explores the application of combinatory categorial grammars (CCGs) to generating property-based tests. Our prototype is able to generate tests from English descriptions for each example in a textbook chapter on property-based testing.