 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRicher Syntactic Dependencies for Structured Language Modeling
Oct 03, 2001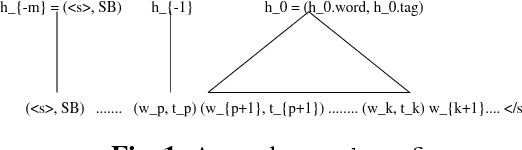
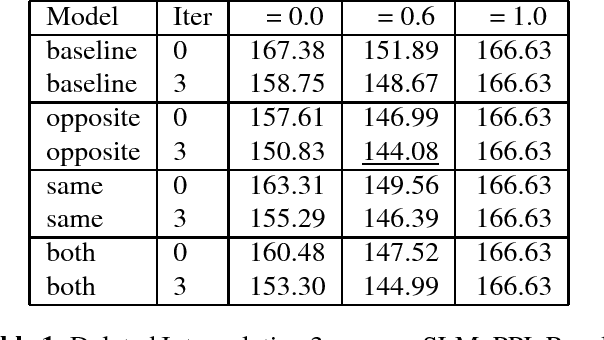
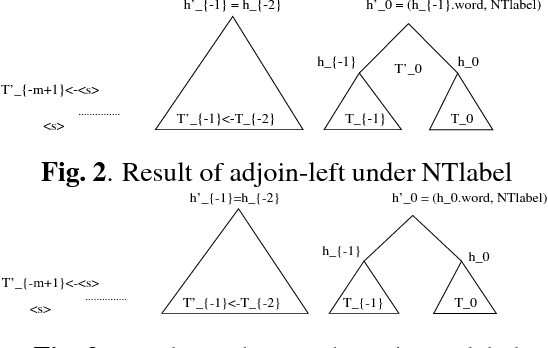
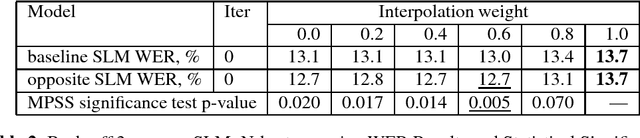
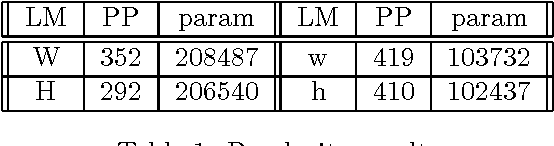
The paper investigates the use of richer syntactic dependencies in the structured language model (SLM). We present two simple methods of enriching the dependencies in the syntactic parse trees used for intializing the SLM. We evaluate the impact of both methods on the perplexity (PPL) and word-error-rate(WER, N-best rescoring) performance of the SLM. We show that the new model achieves an improvement in PPL and WER over the baseline results reported using the SLM on the UPenn Treebank and Wall Street Journal (WSJ) corpora, respectively.
Information Extraction Using the Structured Language Model
Aug 29, 2001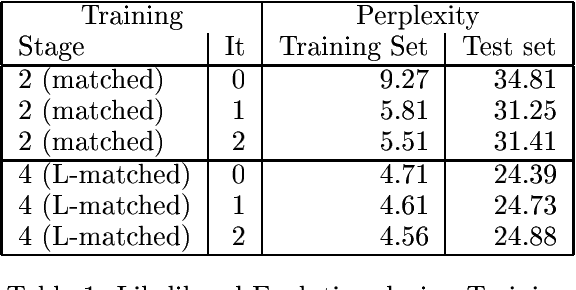
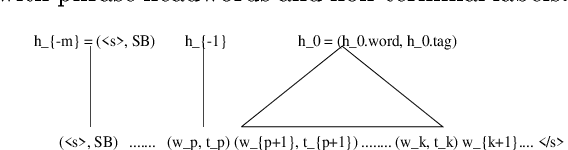
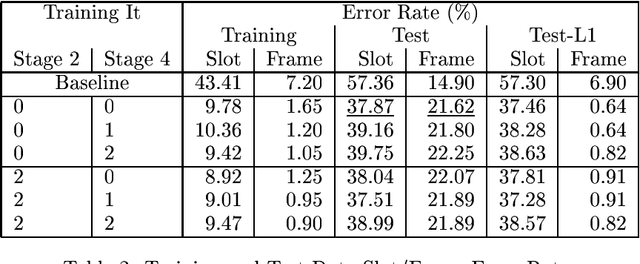
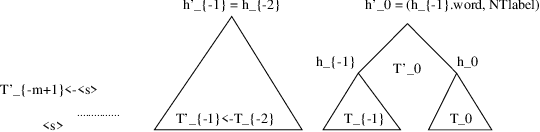
The paper presents a data-driven approach to information extraction (viewed as template filling) using the structured language model (SLM) as a statistical parser. The task of template filling is cast as constrained parsing using the SLM. The model is automatically trained from a set of sentences annotated with frame/slot labels and spans. Training proceeds in stages: first a constrained syntactic parser is trained such that the parses on training data meet the specified semantic spans, then the non-terminal labels are enriched to contain semantic information and finally a constrained syntactic+semantic parser is trained on the parse trees resulting from the previous stage. Despite the small amount of training data used, the model is shown to outperform the slot level accuracy of a simple semantic grammar authored manually for the MiPad --- personal information management --- task.
* EMNLP'01, Pittsburgh; 8 pages
Portability of Syntactic Structure for Language Modeling
Aug 29, 2001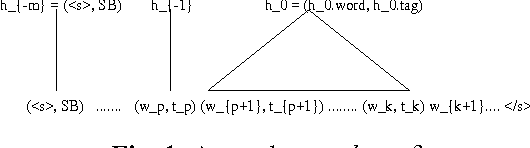
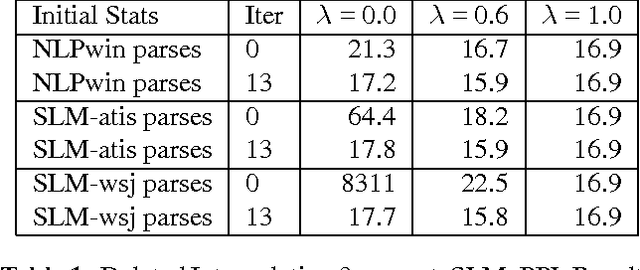
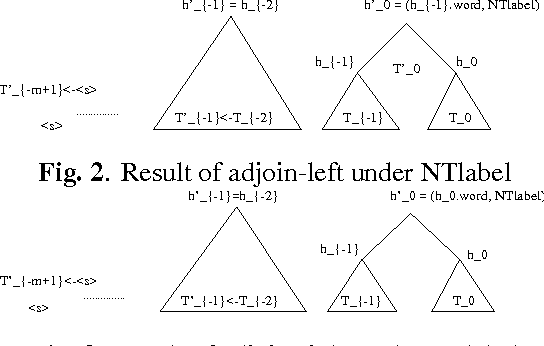
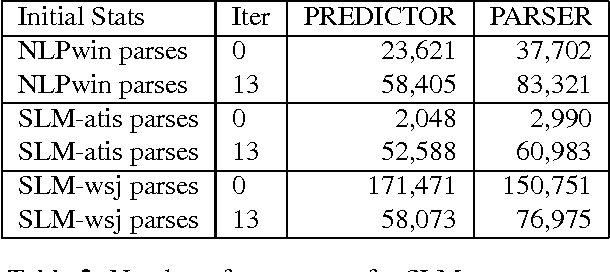
The paper presents a study on the portability of statistical syntactic knowledge in the framework of the structured language model (SLM). We investigate the impact of porting SLM statistics from the Wall Street Journal (WSJ) to the Air Travel Information System (ATIS) domain. We compare this approach to applying the Microsoft rule-based parser (NLPwin) for the ATIS data and to using a small amount of data manually parsed at UPenn for gathering the intial SLM statistics. Surprisingly, despite the fact that it performs modestly in perplexity (PPL), the model initialized on WSJ parses outperforms the other initialization methods based on in-domain annotated data, achieving a significant 0.4% absolute and 7% relative reduction in word error rate (WER) over a baseline system whose word error rate is 5.8%; the improvement measured relative to the minimum WER achievable on the N-best lists we worked with is 12%.
* ICASSP 2001, Salt Lake City; 4 pages
Structured Language Modeling for Speech Recognition
Jan 25, 2000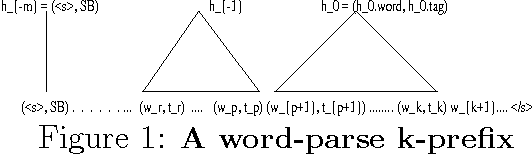

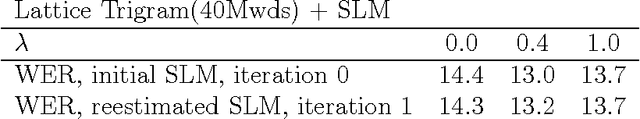
A new language model for speech recognition is presented. The model develops hidden hierarchical syntactic-like structure incrementally and uses it to extract meaningful information from the word history, thus complementing the locality of currently used trigram models. The structured language model (SLM) and its performance in a two-pass speech recognizer --- lattice decoding --- are presented. Experiments on the WSJ corpus show an improvement in both perplexity (PPL) and word error rate (WER) over conventional trigram models.
* 4 pages + 2 pages of ERRATA
A Structured Language Model
Jan 25, 2000
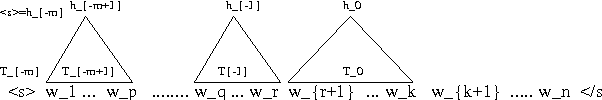
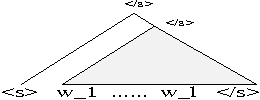
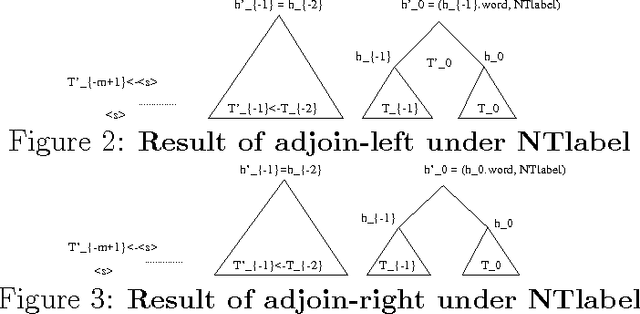
The paper presents a language model that develops syntactic structure and uses it to extract meaningful information from the word history, thus enabling the use of long distance dependencies. The model assigns probability to every joint sequence of words - binary-parse-structure with headword annotation. The model, its probabilistic parametrization, and a set of experiments meant to evaluate its predictive power are presented.
Expoiting Syntactic Structure for Language Modeling
Jan 25, 2000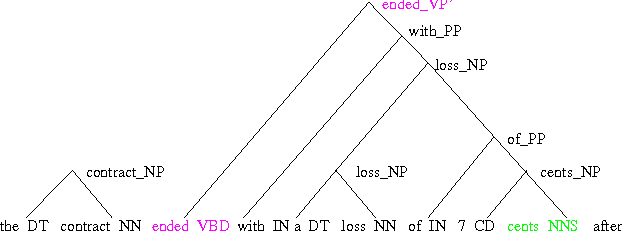
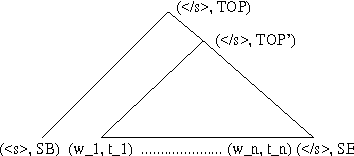

The paper presents a language model that develops syntactic structure and uses it to extract meaningful information from the word history, thus enabling the use of long distance dependencies. The model assigns probability to every joint sequence of words--binary-parse-structure with headword annotation and operates in a left-to-right manner --- therefore usable for automatic speech recognition. The model, its probabilistic parameterization, and a set of experiments meant to evaluate its predictive power are presented; an improvement over standard trigram modeling is achieved.
* changed ACM-class membership and buggy author names
Recognition Performance of a Structured Language Model
Jan 24, 2000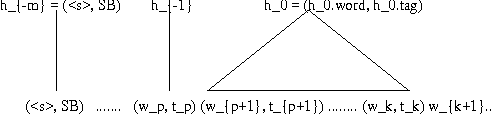
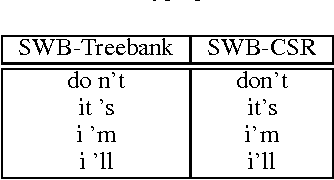
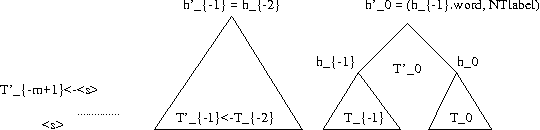

A new language model for speech recognition inspired by linguistic analysis is presented. The model develops hidden hierarchical structure incrementally and uses it to extract meaningful information from the word history - thus enabling the use of extended distance dependencies - in an attempt to complement the locality of currently used trigram models. The structured language model, its probabilistic parameterization and performance in a two-pass speech recognizer are presented. Experiments on the SWITCHBOARD corpus show an improvement in both perplexity and word error rate over conventional trigram models.
* 4 pages
Refinement of a Structured Language Model
Jan 24, 2000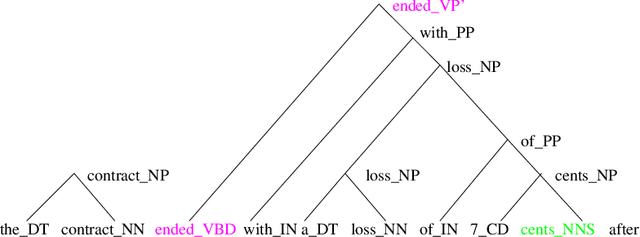
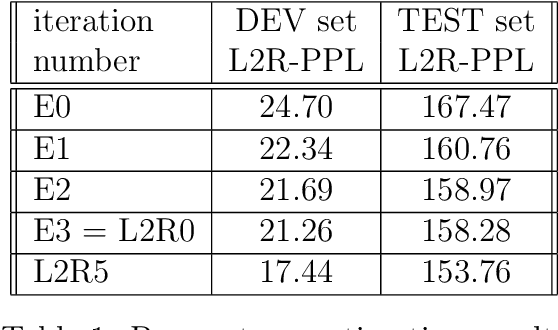
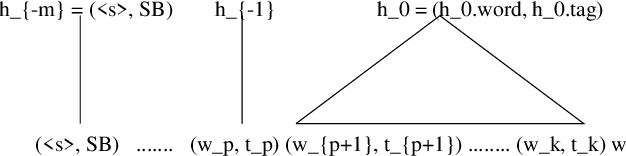
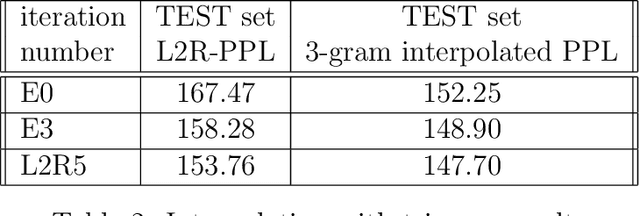
A new language model for speech recognition inspired by linguistic analysis is presented. The model develops hidden hierarchical structure incrementally and uses it to extract meaningful information from the word history - thus enabling the use of extended distance dependencies - in an attempt to complement the locality of currently used n-gram Markov models. The model, its probabilistic parametrization, a reestimation algorithm for the model parameters and a set of experiments meant to evaluate its potential for speech recognition are presented.
* 10 pages
Exploiting Syntactic Structure for Natural Language Modeling
Jan 24, 2000

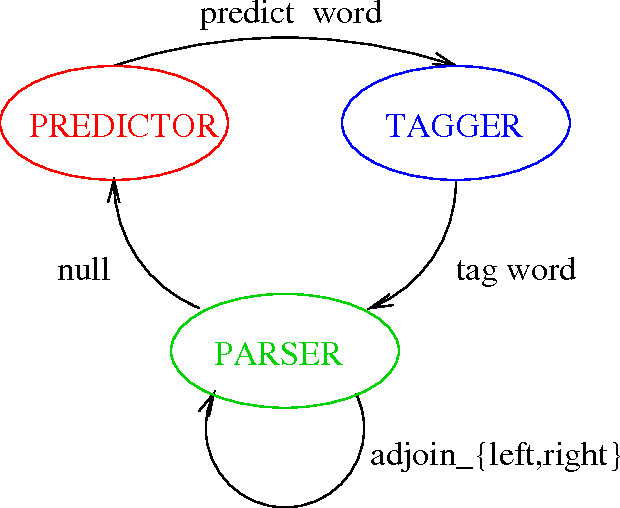
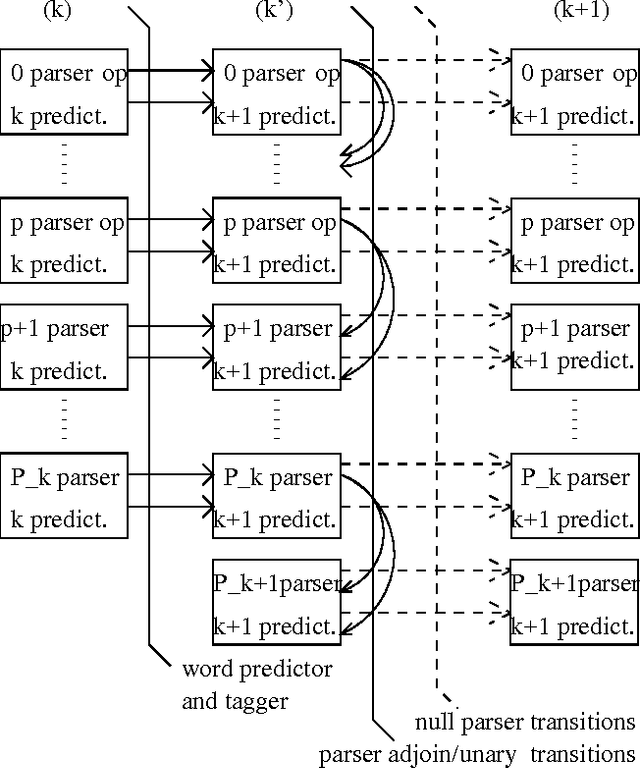
The thesis presents an attempt at using the syntactic structure in natural language for improved language models for speech recognition. The structured language model merges techniques in automatic parsing and language modeling using an original probabilistic parameterization of a shift-reduce parser. A maximum likelihood reestimation procedure belonging to the class of expectation-maximization algorithms is employed for training the model. Experiments on the Wall Street Journal, Switchboard and Broadcast News corpora show improvement in both perplexity and word error rate - word lattice rescoring - over the standard 3-gram language model. The significance of the thesis lies in presenting an original approach to language modeling that uses the hierarchical - syntactic - structure in natural language to improve on current 3-gram modeling techniques for large vocabulary speech recognition.