 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Graph Few-Shot Learning via In-Context Learning
May 23, 2026Graph few-shot learning, which aims to classify nodes from novel classes with only a few labeled examples, is a widely studied problem in graph learning. However, existing methods often face two key limitations. First, the predominant graph few-shot learning paradigm relies on supervised tasks, failing to leverage the vast number of unlabeled nodes in the graph. Second, many approaches require complex task adaptation or fine-tuning during inference, limiting their efficiency and applicability. Inspired by the powerful in-context learning capabilities of large language models, we propose a novel model named VISION for adVancIng graph few-Shot learning via In-cOntext LearNing to address these challenges. Our model reframes graph few-shot learning as a fine-tuning-free sequence reasoning problem. At its core is a context-aware network that initializes nodes with role embeddings and employs a dual-context fusion module to synergistically integrate local topological structures and global task-level dependencies. This allows our model to dynamically generate class-aware representations for the query set conditioned on the support set context in a single forward pass. To effectively train our model, we introduce an unsupervised task generator that creates structure-adaptive features and constructs diverse pseudo-tasks from abundant unlabeled data. Our method unifies unsupervised meta-learning with graph in-context learning, achieving efficient inference. Extensive experiments on multiple benchmark datasets demonstrate the superiority of our model. Our public code can be found
Sample Distortion for Compressed Imaging
Jul 29, 2013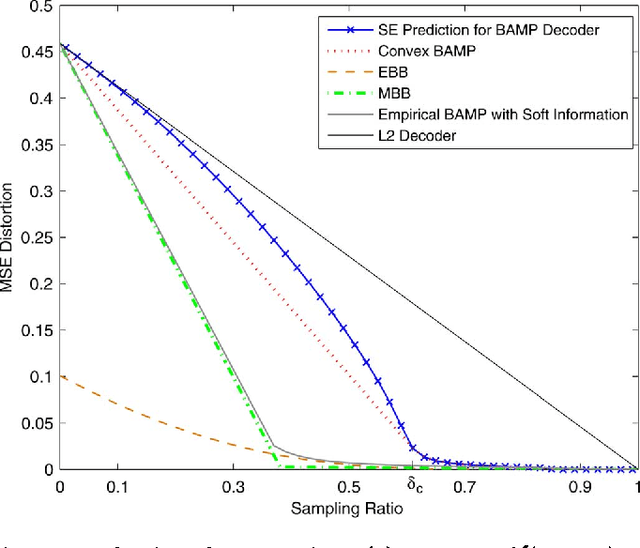

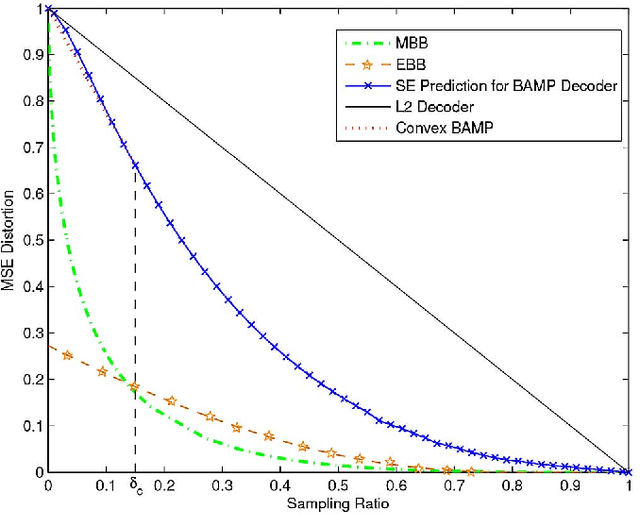
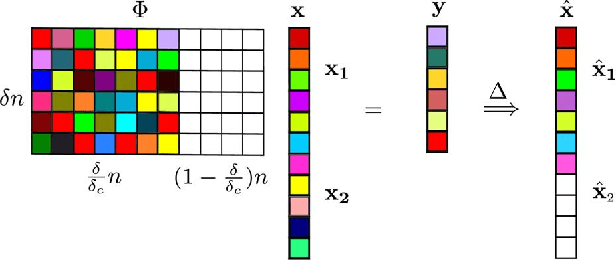
We propose the notion of a sample distortion (SD) function for independent and identically distributed (i.i.d) compressive distributions to fundamentally quantify the achievable reconstruction performance of compressed sensing for certain encoder-decoder pairs at a given sampling ratio. Two lower bounds on the achievable performance and the intrinsic convexity property is derived. A zeroing procedure is then introduced to improve non convex SD functions. The SD framework is then applied to analyse compressed imaging with a multi-resolution statistical image model using both the generalized Gaussian distribution and the two-state Gaussian mixture distribution. We subsequently focus on the Gaussian encoder-Bayesian optimal approximate message passing (AMP) decoder pair, whose theoretical SD function is provided by the rigorous analysis of the AMP algorithm. Given the image statistics, analytic bandwise sample allocation for bandwise independent model is derived as a reverse water-filling scheme. Som and Schniter's turbo message passing approach is further deployed to integrate the bandwise sampling with the exploitation of the hidden Markov tree structure of wavelet coefficients. Natural image simulations confirm that with oracle image statistics, the SD function associated with the optimized sample allocation can accurately predict the possible compressed sensing gains. Finally, a general sample allocation profile based on average image statistics not only illustrates preferable performance but also makes the scheme practical.