 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAUD: Integrating Large Language Models with Active Learning for Unlabeled Data
Nov 18, 2025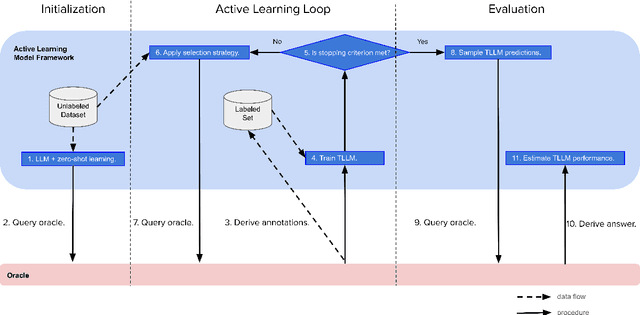
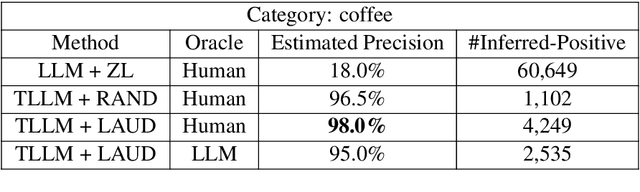
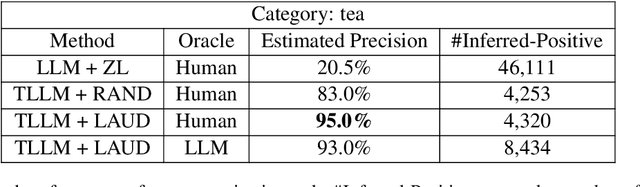
Large language models (LLMs) have shown a remarkable ability to generalize beyond their pre-training data, and fine-tuning LLMs can elevate performance to human-level and beyond. However, in real-world scenarios, lacking labeled data often prevents practitioners from obtaining well-performing models, thereby forcing practitioners to highly rely on prompt-based approaches that are often tedious, inefficient, and driven by trial and error. To alleviate this issue of lacking labeled data, we present a learning framework integrating LLMs with active learning for unlabeled dataset (LAUD). LAUD mitigates the cold-start problem by constructing an initial label set with zero-shot learning. Experimental results show that LLMs derived from LAUD outperform LLMs with zero-shot or few-shot learning on commodity name classification tasks, demonstrating the effectiveness of LAUD.
G2R Bound: A Generalization Bound for Supervised Learning from GAN-Synthetic Data
May 29, 2019
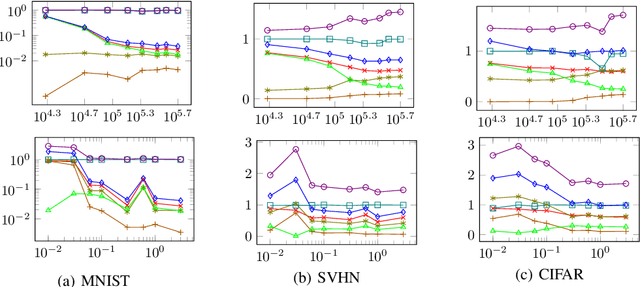
Performing supervised learning from the data synthesized by using Generative Adversarial Networks (GANs), dubbed GAN-synthetic data, has two important applications. First, GANs may generate more labeled training data, which may help improve classification accuracy. Second, in scenarios where real data cannot be released outside certain premises for privacy and/or security reasons, using GAN- synthetic data to conduct training is a plausible alternative. This paper proposes a generalization bound to guarantee the generalization capability of a classifier learning from GAN-synthetic data. This generalization bound helps developers gauge the generalization gap between learning from synthetic data and testing on real data, and can therefore provide the clues to improve the generalization capability.
Distributed Layer-Partitioned Training for Privacy-Preserved Deep Learning
Apr 12, 2019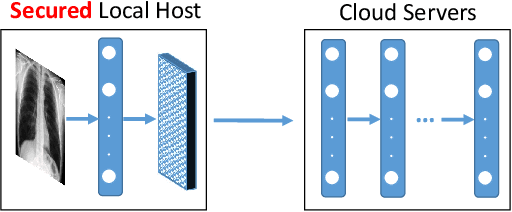

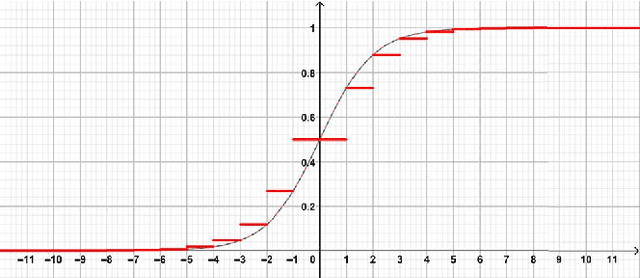
Deep Learning techniques have achieved remarkable results in many domains. Often, training deep learning models requires large datasets, which may require sensitive information to be uploaded to the cloud to accelerate training. To adequately protect sensitive information, we propose distributed layer-partitioned training with step-wise activation functions for privacy-preserving deep learning. Experimental results attest our method to be simple and effective.
BRIEF: Backward Reduction of CNNs with Information Flow Analysis
Nov 01, 2018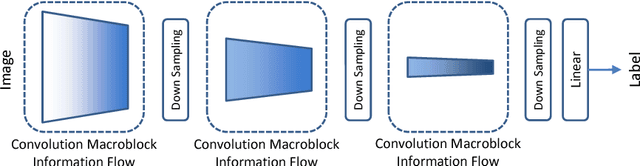
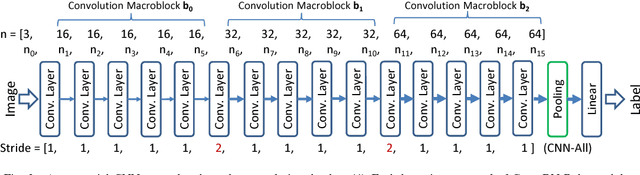
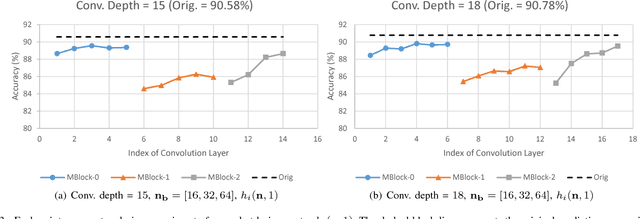
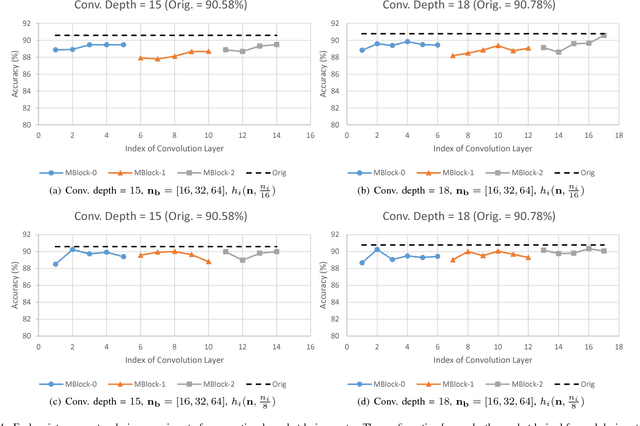
This paper proposes BRIEF, a backward reduction algorithm that explores compact CNN-model designs from the information flow perspective. This algorithm can remove substantial non-zero weighting parameters (redundant neural channels) of a network by considering its dynamic behavior, which traditional model-compaction techniques cannot achieve. With the aid of our proposed algorithm, we achieve significant model reduction on ResNet-34 in the ImageNet scale (32.3% reduction), which is 3X better than the previous result (10.8%). Even for highly optimized models such as SqueezeNet and MobileNet, we can achieve additional 10.81% and 37.56% reduction, respectively, with negligible performance degradation.
MBS: Macroblock Scaling for CNN Model Reduction
Sep 18, 2018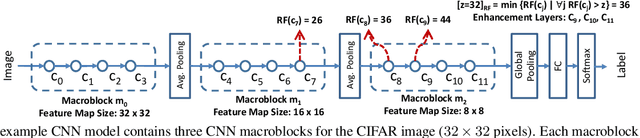
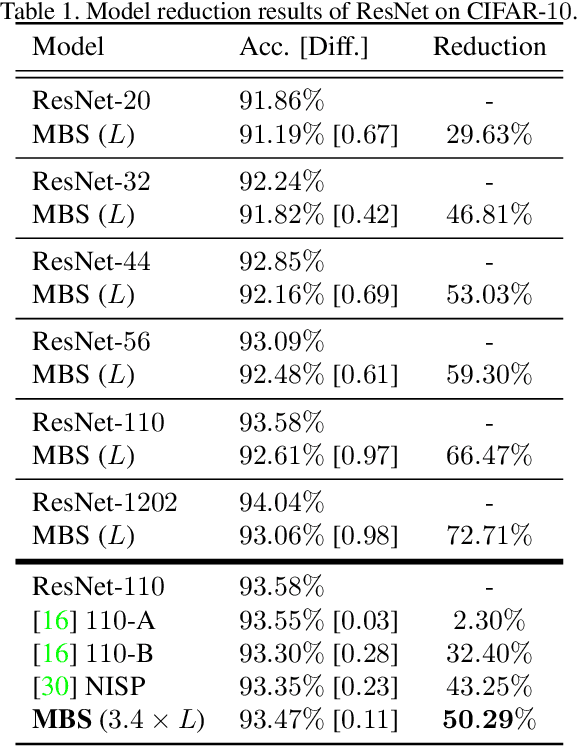
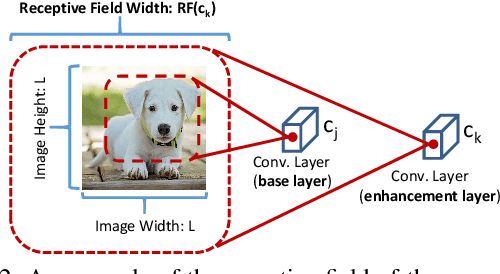
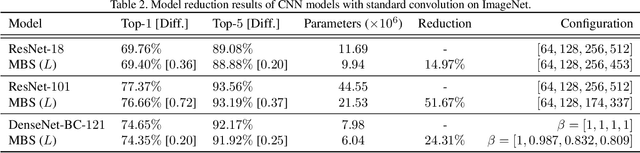
We estimate the proper channel (width) scaling of Convolution Neural Networks (CNNs) for model reduction. Unlike the traditional scaling method that reduces every CNN channel width by the same scaling factor, we address each CNN macroblock adaptively depending on its information redundancy measured by our proposed effective flops. Our proposed macroblock scaling (MBS) algorithm can be applied to various CNN architectures to reduce their model size. These applicable models range from compact CNN models such as MobileNet (25.53% reduction, ImageNet) and ShuffleNet (20.74% reduction, ImageNet) to ultra-deep ones such as ResNet-101 (51.67% reduction, ImageNet) and ResNet-1202 (72.71% reduction, CIFAR-10) with negligible accuracy degradation. MBS also performs better reduction at a much lower cost than does the state-of-the-art optimization-based method. MBS's simplicity and efficiency, its flexibility to work with any CNN model, and its scalability to work with models of any depth makes it an attractive choice for CNN model size reduction.
BDA-PCH: Block-Diagonal Approximation of Positive-Curvature Hessian for Training Neural Networks
Feb 20, 2018
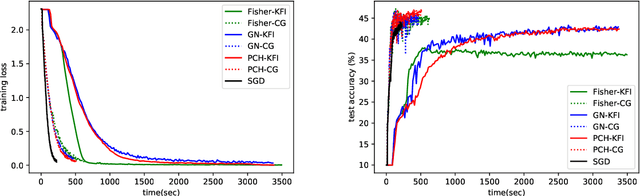
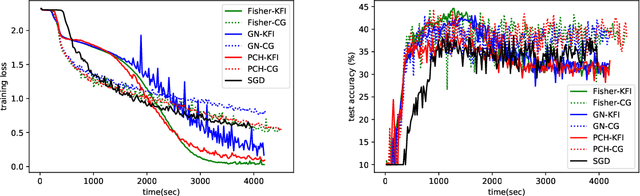
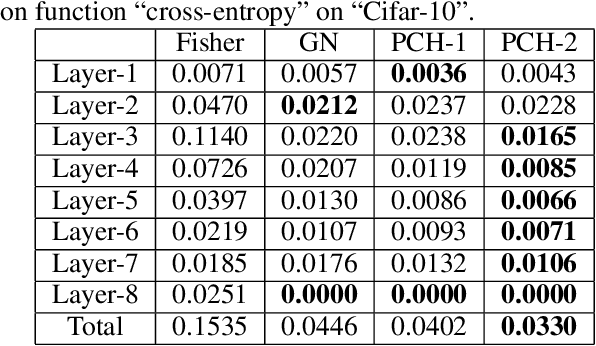
We propose a block-diagonal approximation of the positive-curvature Hessian (BDA-PCH) matrix to measure curvature. Our proposed BDAPCH matrix is memory efficient and can be applied to any fully-connected neural networks where the activation and criterion functions are twice differentiable. Particularly, our BDA-PCH matrix can handle non-convex criterion functions. We devise an efficient scheme utilizing the conjugate gradient method to derive Newton directions for mini-batch setting. Empirical studies show that our method outperforms the competing second-order methods in convergence speed.
Distributed Training Large-Scale Deep Architectures
Aug 10, 2017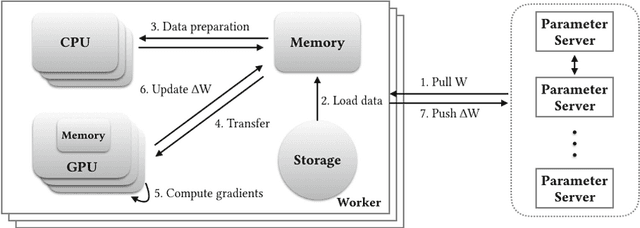
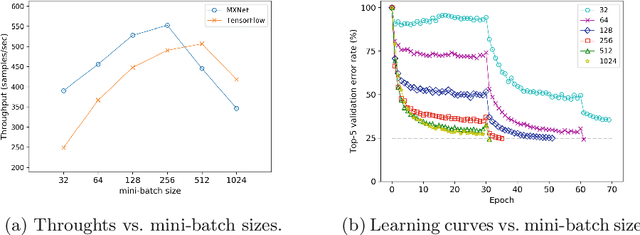
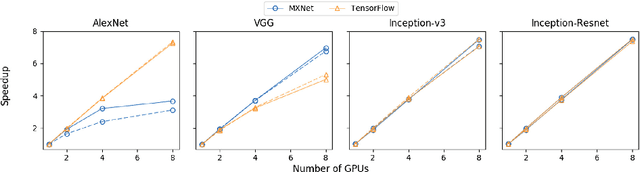
Scale of data and scale of computation infrastructures together enable the current deep learning renaissance. However, training large-scale deep architectures demands both algorithmic improvement and careful system configuration. In this paper, we focus on employing the system approach to speed up large-scale training. Via lessons learned from our routine benchmarking effort, we first identify bottlenecks and overheads that hinter data parallelism. We then devise guidelines that help practitioners to configure an effective system and fine-tune parameters to achieve desired speedup. Specifically, we develop a procedure for setting minibatch size and choosing computation algorithms. We also derive lemmas for determining the quantity of key components such as the number of GPUs and parameter servers. Experiments and examples show that these guidelines help effectively speed up large-scale deep learning training.
Representation Learning on Large and Small Data
Jul 25, 2017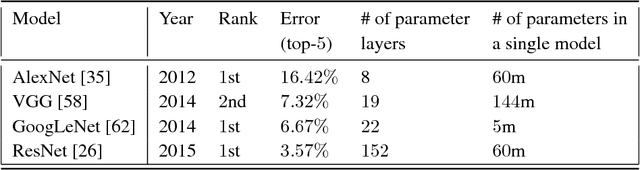
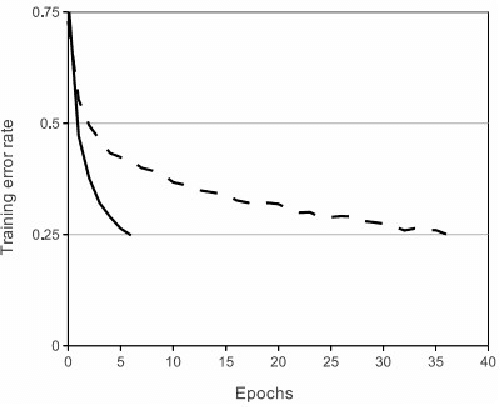
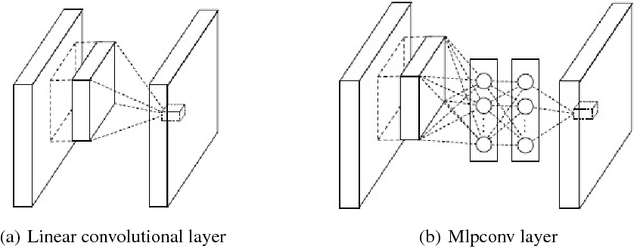
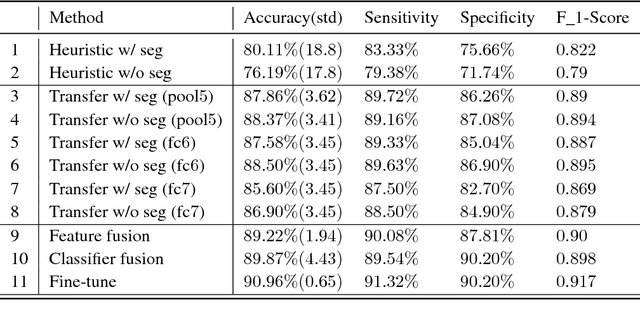
Deep learning owes its success to three key factors: scale of data, enhanced models to learn representations from data, and scale of computation. This book chapter presented the importance of the data-driven approach to learn good representations from both big data and small data. In terms of big data, it has been widely accepted in the research community that the more data the better for both representation and classification improvement. The question is then how to learn representations from big data, and how to perform representation learning when data is scarce. We addressed the first question by presenting CNN model enhancements in the aspects of representation, optimization, and generalization. To address the small data challenge, we showed transfer representation learning to be effective. Transfer representation learning transfers the learned representation from a source domain where abundant training data is available to a target domain where training data is scarce. Transfer representation learning gave the OM and melanoma diagnosis modules of our XPRIZE Tricorder device (which finished $2^{nd}$ out of $310$ competing teams) a significant boost in diagnosis accuracy.