 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAUD: Integrating Large Language Models with Active Learning for Unlabeled Data
Paper and Code
Nov 18, 2025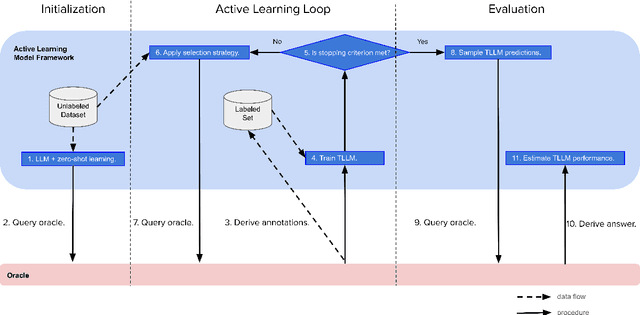
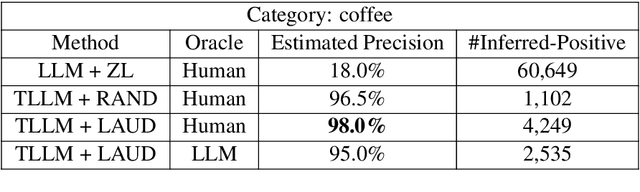
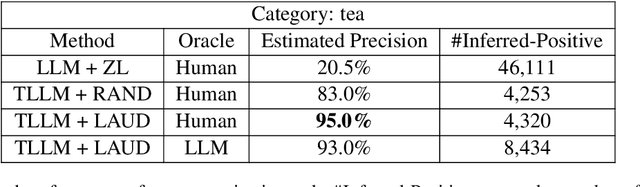
Large language models (LLMs) have shown a remarkable ability to generalize beyond their pre-training data, and fine-tuning LLMs can elevate performance to human-level and beyond. However, in real-world scenarios, lacking labeled data often prevents practitioners from obtaining well-performing models, thereby forcing practitioners to highly rely on prompt-based approaches that are often tedious, inefficient, and driven by trial and error. To alleviate this issue of lacking labeled data, we present a learning framework integrating LLMs with active learning for unlabeled dataset (LAUD). LAUD mitigates the cold-start problem by constructing an initial label set with zero-shot learning. Experimental results show that LLMs derived from LAUD outperform LLMs with zero-shot or few-shot learning on commodity name classification tasks, demonstrating the effectiveness of LAUD.