 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure and Parameter Learning for Causal Independence and Causal Interaction Models
May 16, 2015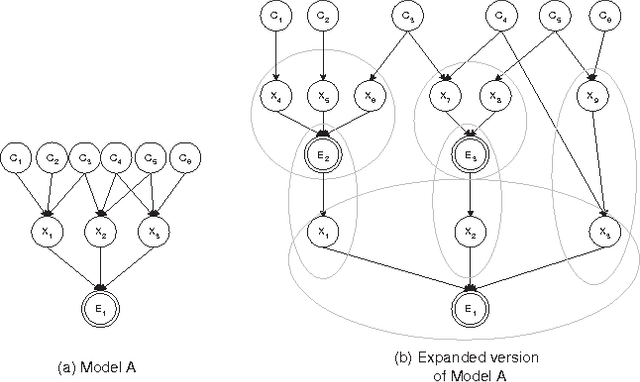
This paper discusses causal independence models and a generalization of these models called causal interaction models. Causal interaction models are models that have independent mechanisms where a mechanism can have several causes. In addition to introducing several particular types of causal interaction models, we show how we can apply the Bayesian approach to learning causal interaction models obtaining approximate posterior distributions for the models and obtain MAP and ML estimates for the parameters. We illustrate the approach with a simulation study of learning model posteriors.
A Bayesian Approach to Learning Bayesian Networks with Local Structure
May 16, 2015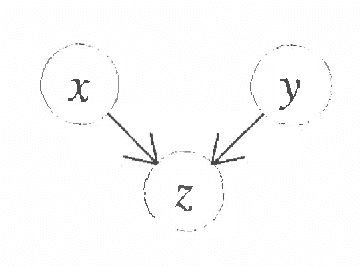
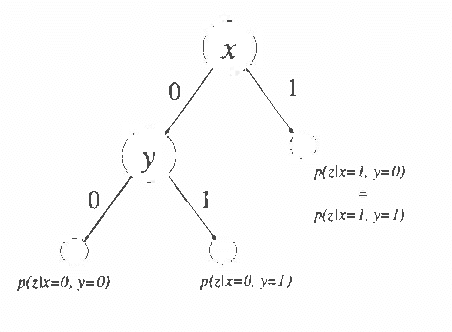
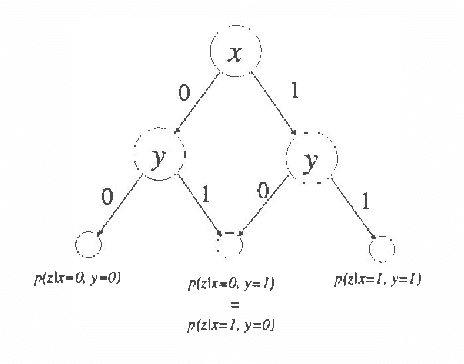
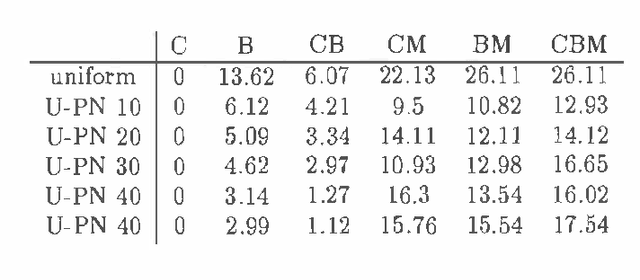
Recently several researchers have investigated techniques for using data to learn Bayesian networks containing compact representations for the conditional probability distributions (CPDs) stored at each node. The majority of this work has concentrated on using decision-tree representations for the CPDs. In addition, researchers typically apply non-Bayesian (or asymptotically Bayesian) scoring functions such as MDL to evaluate the goodness-of-fit of networks to the data. In this paper we investigate a Bayesian approach to learning Bayesian networks that contain the more general decision-graph representations of the CPDs. First, we describe how to evaluate the posterior probability that is, the Bayesian score of such a network, given a database of observed cases. Second, we describe various search spaces that can be used, in conjunction with a scoring function and a search procedure, to identify one or more high-scoring networks. Finally, we present an experimental evaluation of the search spaces, using a greedy algorithm and a Bayesian scoring function.
Learning Mixtures of DAG Models
May 16, 2015
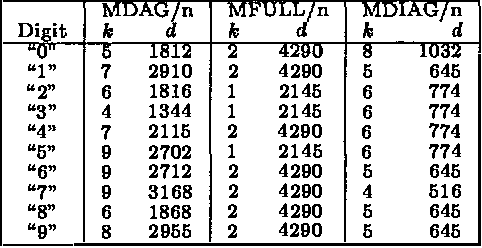
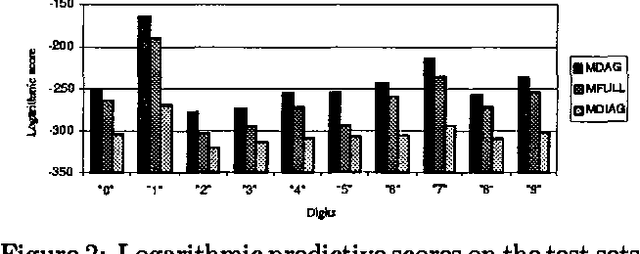
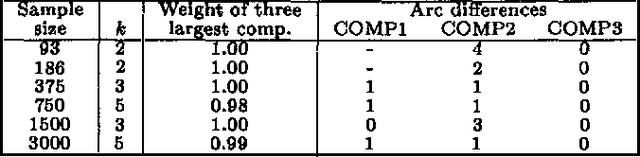
We describe computationally efficient methods for learning mixtures in which each component is a directed acyclic graphical model (mixtures of DAGs or MDAGs). We argue that simple search-and-score algorithms are infeasible for a variety of problems, and introduce a feasible approach in which parameter and structure search is interleaved and expected data is treated as real data. Our approach can be viewed as a combination of (1) the Cheeseman--Stutz asymptotic approximation for model posterior probability and (2) the Expectation--Maximization algorithm. We evaluate our procedure for selecting among MDAGs on synthetic and real examples.
CFW: A Collaborative Filtering System Using Posteriors Over Weights Of Evidence
May 16, 2015
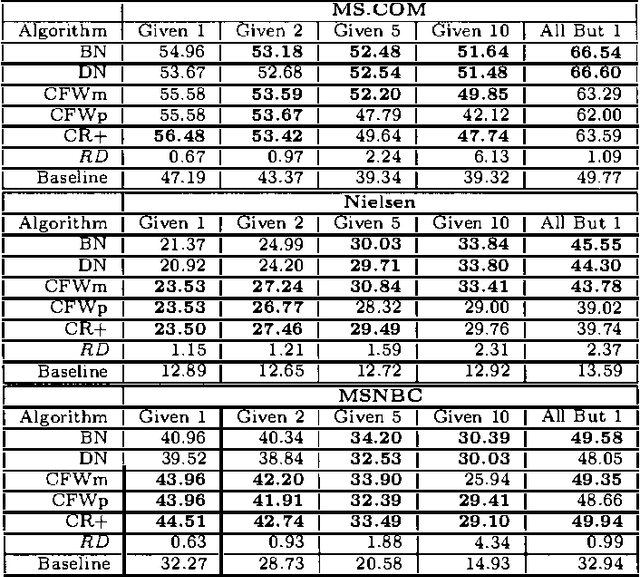
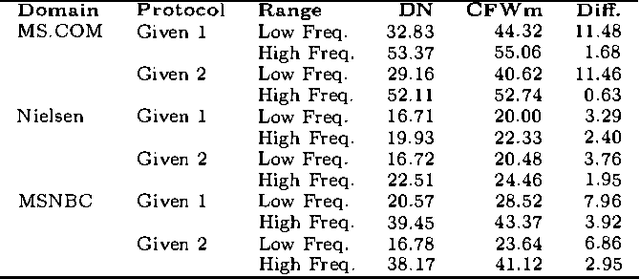
We describe CFW, a computationally efficient algorithm for collaborative filtering that uses posteriors over weights of evidence. In experiments on real data, we show that this method predicts as well or better than other methods in situations where the size of the user query is small. The new approach works particularly well when the user s query CONTAINS low frequency(unpopular) items.The approach complements that OF dependency networks which perform well WHEN the size OF the query IS large.Also IN this paper, we argue that the USE OF posteriors OVER weights OF evidence IS a natural way TO recommend similar items collaborative - filtering task.
Regularized Minimax Conditional Entropy for Crowdsourcing
Mar 25, 2015

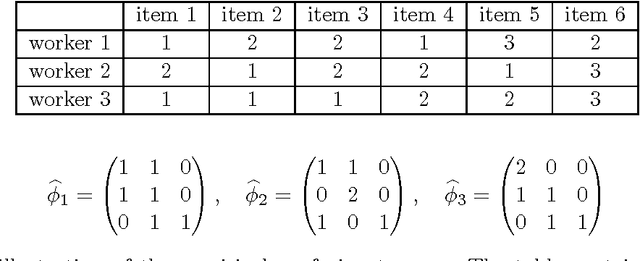
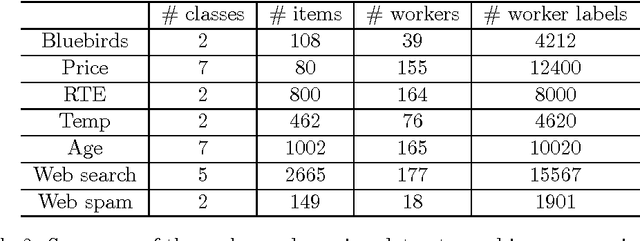
There is a rapidly increasing interest in crowdsourcing for data labeling. By crowdsourcing, a large number of labels can be often quickly gathered at low cost. However, the labels provided by the crowdsourcing workers are usually not of high quality. In this paper, we propose a minimax conditional entropy principle to infer ground truth from noisy crowdsourced labels. Under this principle, we derive a unique probabilistic labeling model jointly parameterized by worker ability and item difficulty. We also propose an objective measurement principle, and show that our method is the only method which satisfies this objective measurement principle. We validate our method through a variety of real crowdsourcing datasets with binary, multiclass or ordinal labels.
Proceedings of the Nineteenth Conference on Uncertainty in Artificial Intelligence (2003)
Aug 28, 2014This is the Proceedings of the Nineteenth Conference on Uncertainty in Artificial Intelligence, which was held in Acapulco, Mexico, August 7-10 2003
Causal Inference in the Presence of Latent Variables and Selection Bias
Feb 20, 2013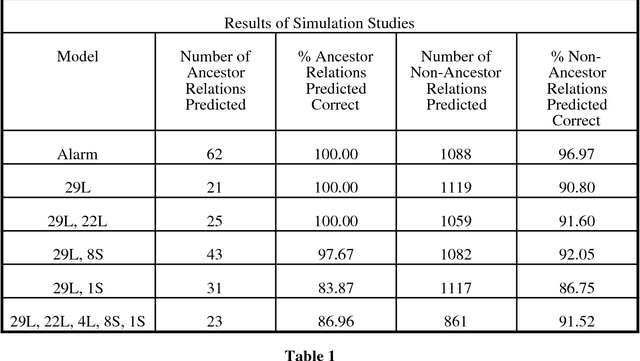
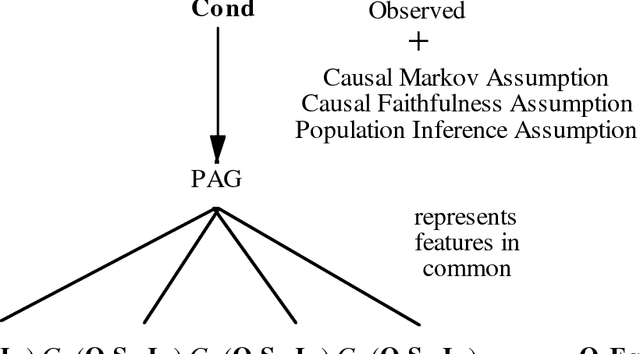
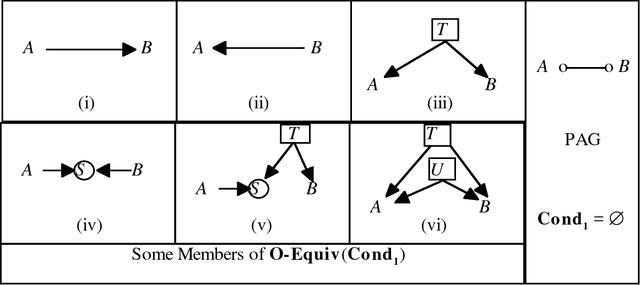
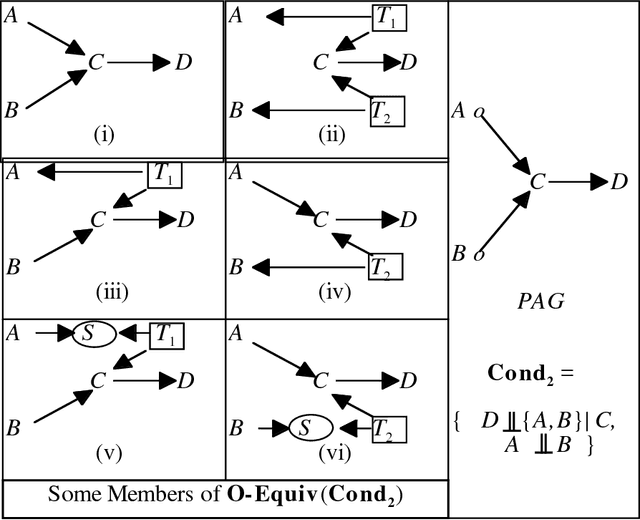
We show that there is a general, informative and reliable procedure for discovering causal relations when, for all the investigator knows, both latent variables and selection bias may be at work. Given information about conditional independence and dependence relations between measured variables, even when latent variables and selection bias may be present, there are sufficient conditions for reliably concluding that there is a causal path from one variable to another, and sufficient conditions for reliably concluding when no such causal path exists.
Strong Completeness and Faithfulness in Bayesian Networks
Feb 20, 2013
A completeness result for d-separation applied to discrete Bayesian networks is presented and it is shown that in a strong measure-theoretic sense almost all discrete distributions for a given network structure are faithful; i.e. the independence facts true of the distribution are all and only those entailed by the network structure.
Causal Inference and Causal Explanation with Background Knowledge
Feb 20, 2013This paper presents correct algorithms for answering the following two questions; (i) Does there exist a causal explanation consistent with a set of background knowledge which explains all of the observed independence facts in a sample? (ii) Given that there is such a causal explanation what are the causal relationships common to every such causal explanation?
Models and Selection Criteria for Regression and Classification
Feb 06, 2013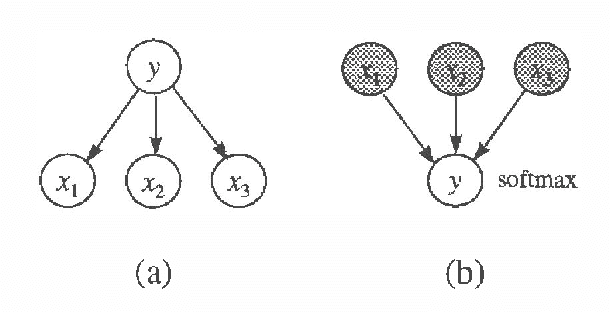
When performing regression or classification, we are interested in the conditional probability distribution for an outcome or class variable Y given a set of explanatoryor input variables X. We consider Bayesian models for this task. In particular, we examine a special class of models, which we call Bayesian regression/classification (BRC) models, that can be factored into independent conditional (y|x) and input (x) models. These models are convenient, because the conditional model (the portion of the full model that we care about) can be analyzed by itself. We examine the practice of transforming arbitrary Bayesian models to BRC models, and argue that this practice is often inappropriate because it ignores prior knowledge that may be important for learning. In addition, we examine Bayesian methods for learning models from data. We discuss two criteria for Bayesian model selection that are appropriate for repression/classification: one described by Spiegelhalter et al. (1993), and another by Buntine (1993). We contrast these two criteria using the prequential framework of Dawid (1984), and give sufficient conditions under which the criteria agree.