 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying language changes surrounding mental health on Twitter
Jun 02, 2021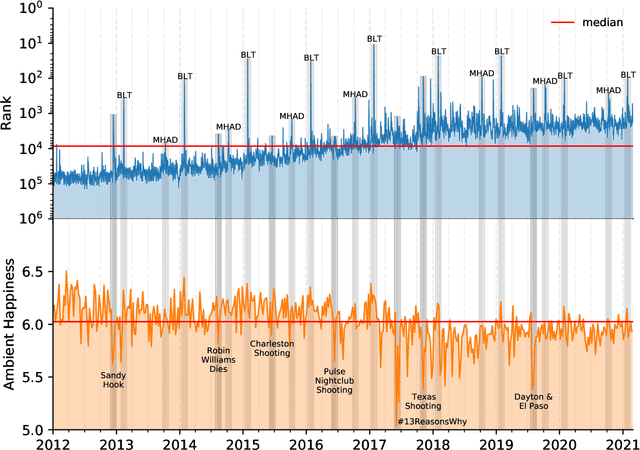
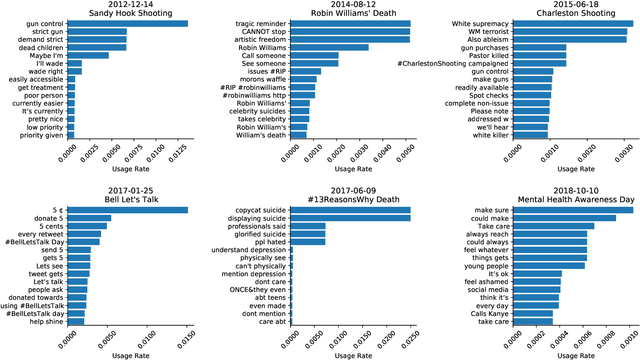
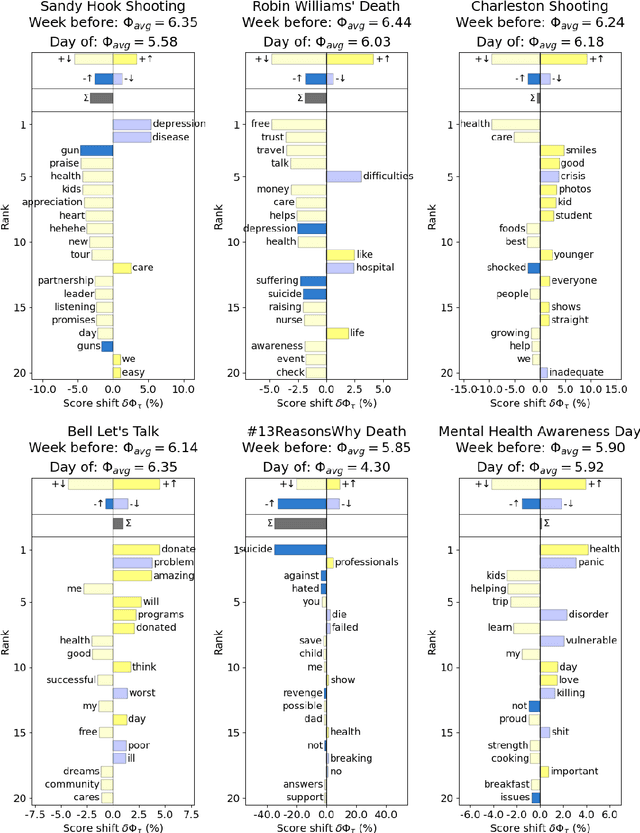
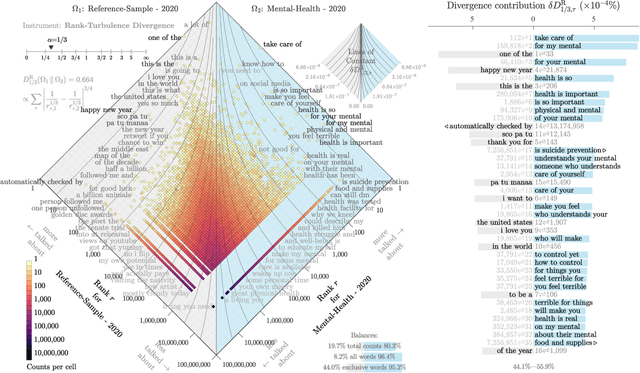
Mental health challenges are thought to afflict around 10% of the global population each year, with many going untreated due to stigma and limited access to services. Here, we explore trends in words and phrases related to mental health through a collection of 1- , 2-, and 3-grams parsed from a data stream of roughly 10% of all English tweets since 2012. We examine temporal dynamics of mental health language, finding that the popularity of the phrase 'mental health' increased by nearly two orders of magnitude between 2012 and 2018. We observe that mentions of 'mental health' spike annually and reliably due to mental health awareness campaigns, as well as unpredictably in response to mass shootings, celebrities dying by suicide, and popular fictional stories portraying suicide. We find that the level of positivity of messages containing 'mental health', while stable through the growth period, has declined recently. Finally, we use the ratio of original tweets to retweets to quantify the fraction of appearances of mental health language due to social amplification. Since 2015, mentions of mental health have become increasingly due to retweets, suggesting that stigma associated with discussion of mental health on Twitter has diminished with time.
The incel lexicon: Deciphering the emergent cryptolect of a global misogynistic community
May 25, 2021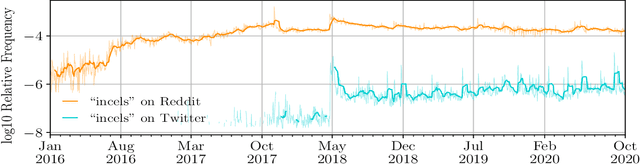
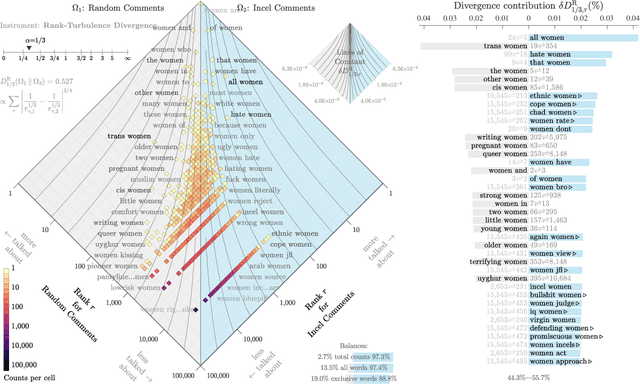
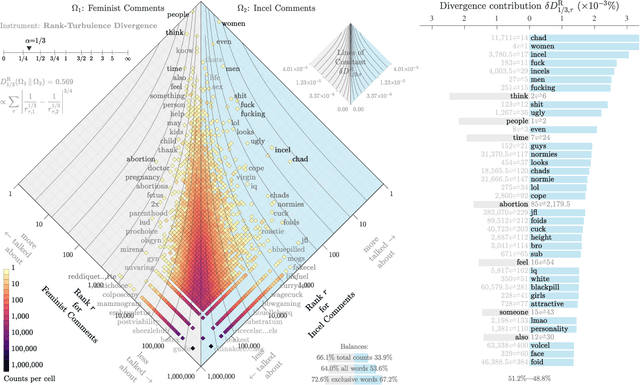
Evolving out of a gender-neutral framing of an involuntary celibate identity, the concept of `incels' has come to refer to an online community of men who bear antipathy towards themselves, women, and society-at-large for their perceived inability to find and maintain sexual relationships. By exploring incel language use on Reddit, a global online message board, we contextualize the incel community's online expressions of misogyny and real-world acts of violence perpetrated against women. After assembling around three million comments from incel-themed Reddit channels, we analyze the temporal dynamics of a data driven rank ordering of the glossary of phrases belonging to an emergent incel lexicon. Our study reveals the generation and normalization of an extensive coded misogynist vocabulary in service of the group's identity.
Interpretable bias mitigation for textual data: Reducing gender bias in patient notes while maintaining classification performance
Mar 10, 2021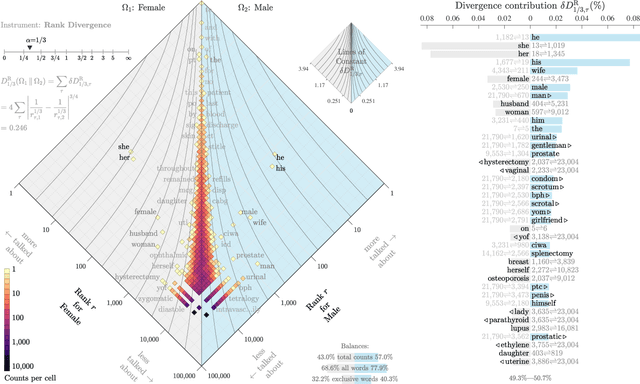
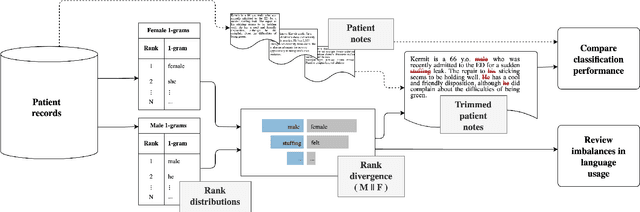
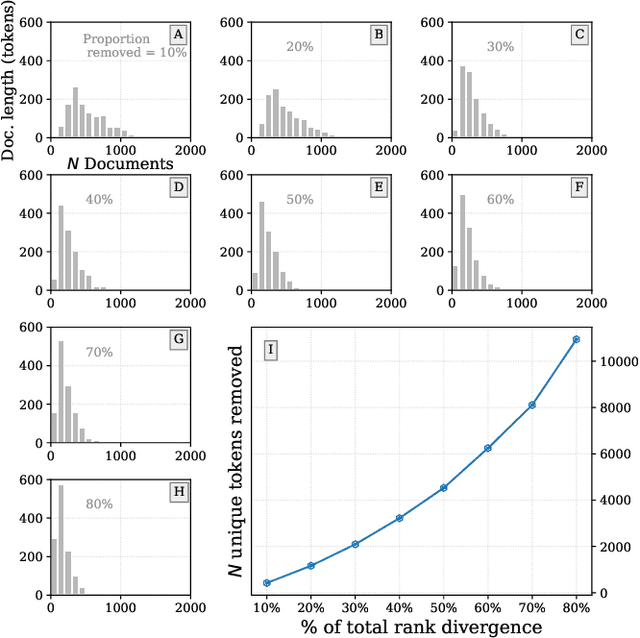
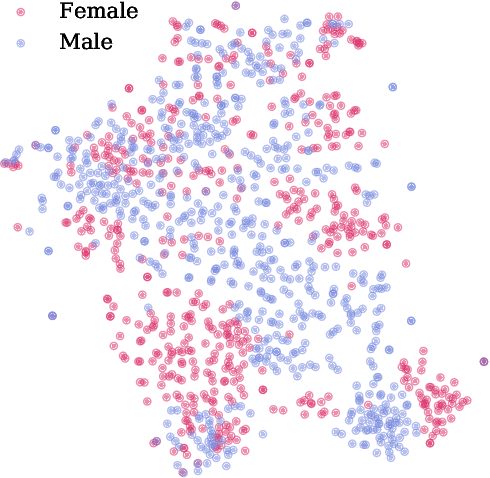
Medical systems in general, and patient treatment decisions and outcomes in particular, are affected by bias based on gender and other demographic elements. As language models are increasingly applied to medicine, there is a growing interest in building algorithmic fairness into processes impacting patient care. Much of the work addressing this question has focused on biases encoded in language models -- statistical estimates of the relationships between concepts derived from distant reading of corpora. Building on this work, we investigate how word choices made by healthcare practitioners and language models interact with regards to bias. We identify and remove gendered language from two clinical-note datasets and describe a new debiasing procedure using BERT-based gender classifiers. We show minimal degradation in health condition classification tasks for low- to medium-levels of bias removal via data augmentation. Finally, we compare the bias semantically encoded in the language models with the bias empirically observed in health records. This work outlines an interpretable approach for using data augmentation to identify and reduce the potential for bias in natural language processing pipelines.
Generalized Word Shift Graphs: A Method for Visualizing and Explaining Pairwise Comparisons Between Texts
Aug 05, 2020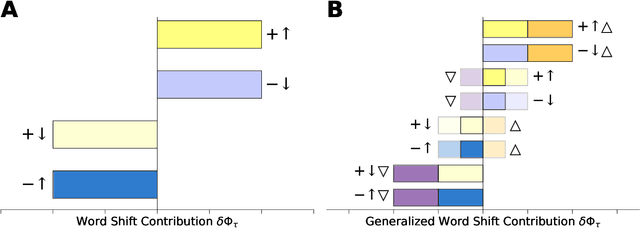
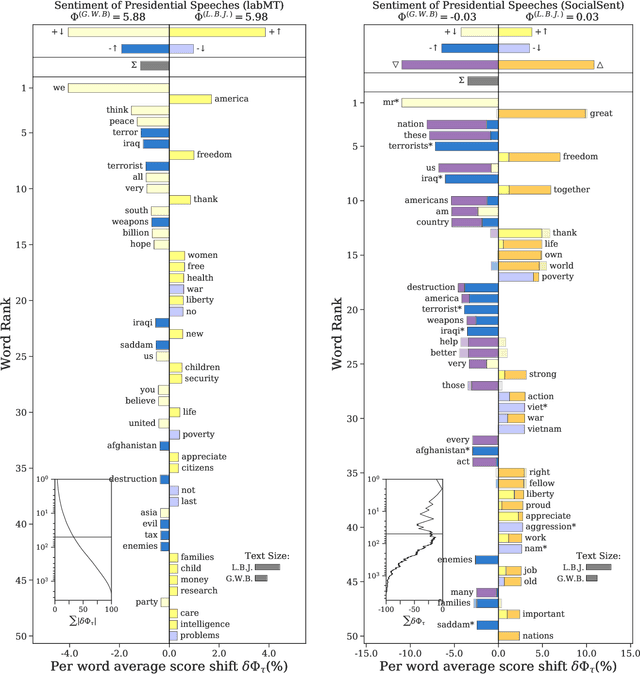
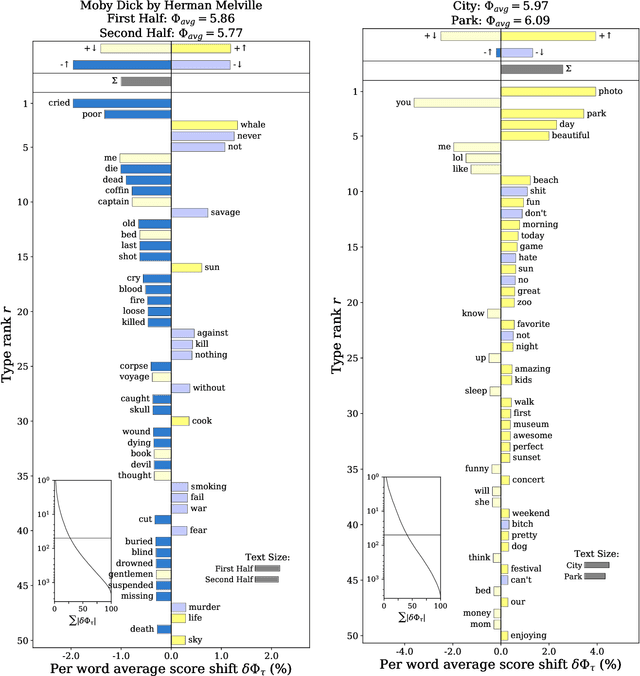
A common task in computational text analyses is to quantify how two corpora differ according to a measurement like word frequency, sentiment, or information content. However, collapsing the texts' rich stories into a single number is often conceptually perilous, and it is difficult to confidently interpret interesting or unexpected textual patterns without looming concerns about data artifacts or measurement validity. To better capture fine-grained differences between texts, we introduce generalized word shift graphs, visualizations which yield a meaningful and interpretable summary of how individual words contribute to the variation between two texts for any measure that can be formulated as a weighted average. We show that this framework naturally encompasses many of the most commonly used approaches for comparing texts, including relative frequencies, dictionary scores, and entropy-based measures like the Kullback-Leibler and Jensen-Shannon divergences. Through several case studies, we demonstrate how generalized word shift graphs can be flexibly applied across domains for diagnostic investigation, hypothesis generation, and substantive interpretation. By providing a detailed lens into textual shifts between corpora, generalized word shift graphs help computational social scientists, digital humanists, and other text analysis practitioners fashion more robust scientific narratives.
Storywrangler: A massive exploratorium for sociolinguistic, cultural, socioeconomic, and political timelines using Twitter
Jul 25, 2020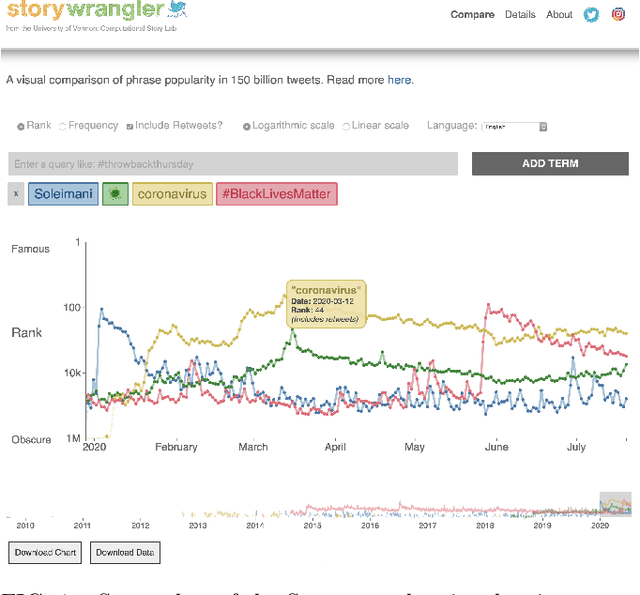
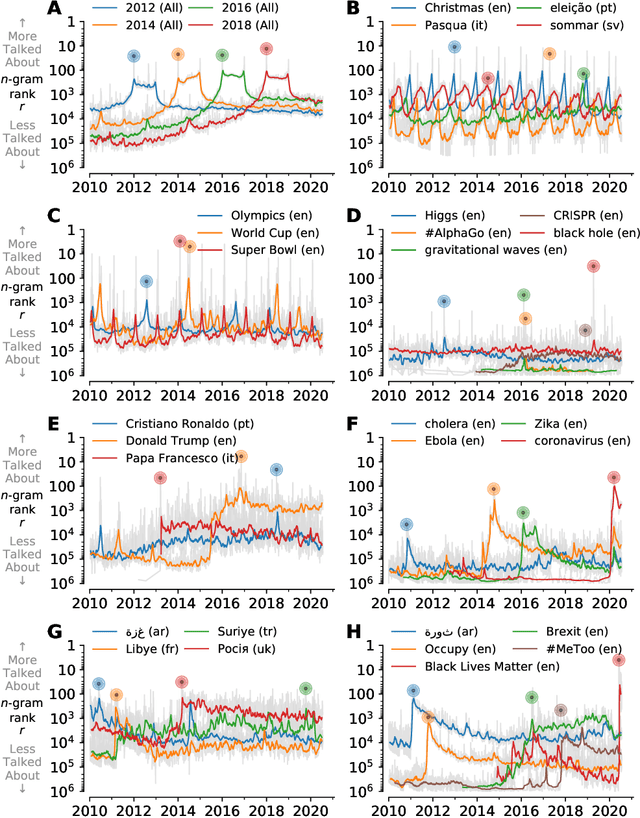
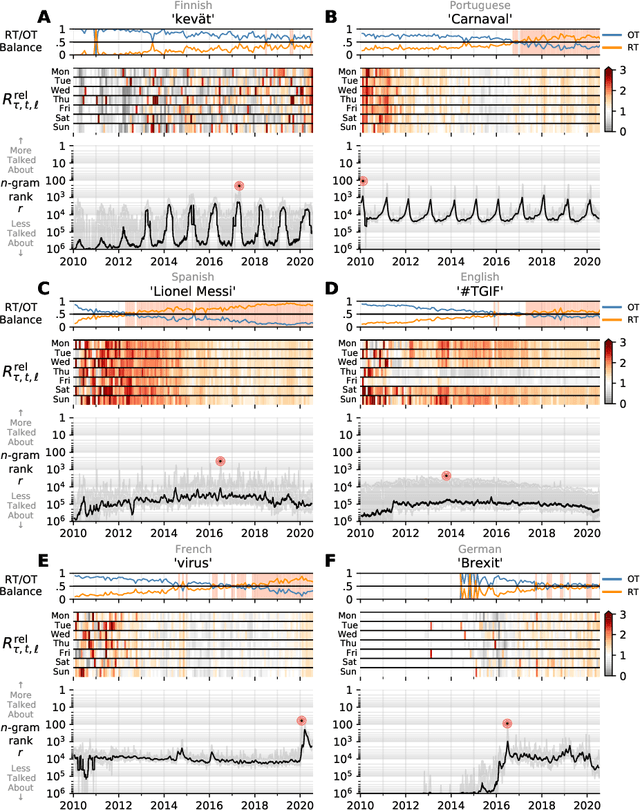
In real-time, Twitter strongly imprints world events, popular culture, and the day-to-day; Twitter records an ever growing compendium of language use and change; and Twitter has been shown to enable certain kinds of prediction. Vitally, and absent from many standard corpora such as books and news archives, Twitter also encodes popularity and spreading through retweets. Here, we describe Storywrangler, an ongoing, day-scale curation of over 100 billion tweets containing around 1 trillion 1-grams from 2008 to 2020. For each day, we break tweets into 1-, 2-, and 3-grams across 150+ languages, record usage frequencies, and generate Zipf distributions. We make the data set available through an interactive time series viewer, and as downloadable time series and daily distributions. We showcase a few examples of the many possible avenues of study we aim to enable including how social amplification can be visualized through 'contagiograms'.
The growing echo chamber of social media: Measuring temporal and social contagion dynamics for over 150 languages on Twitter for 2009--2020
Mar 15, 2020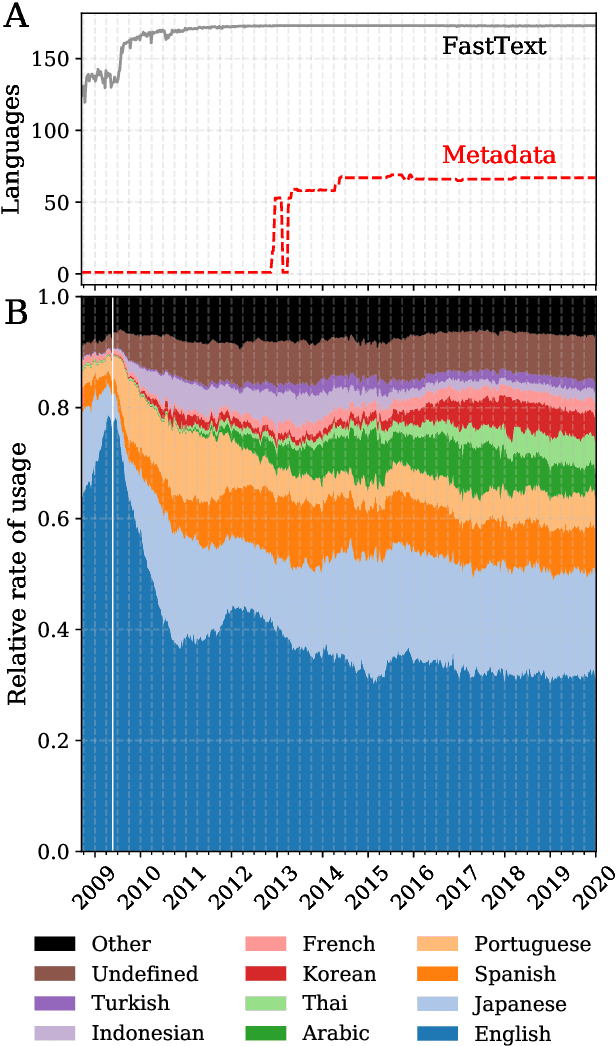
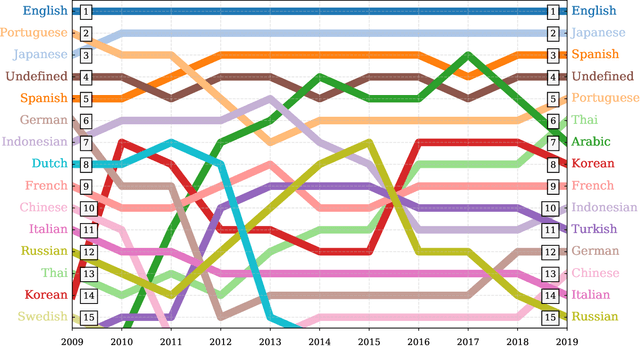
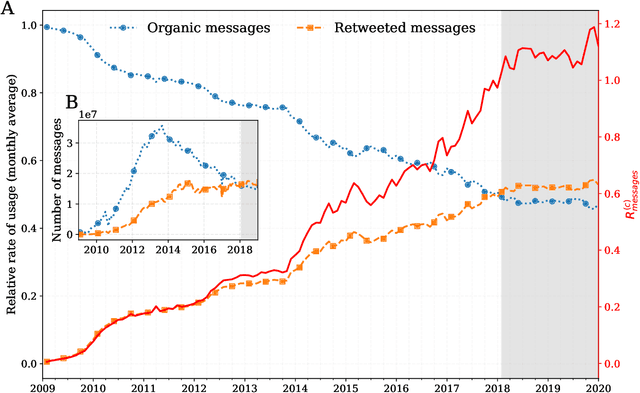
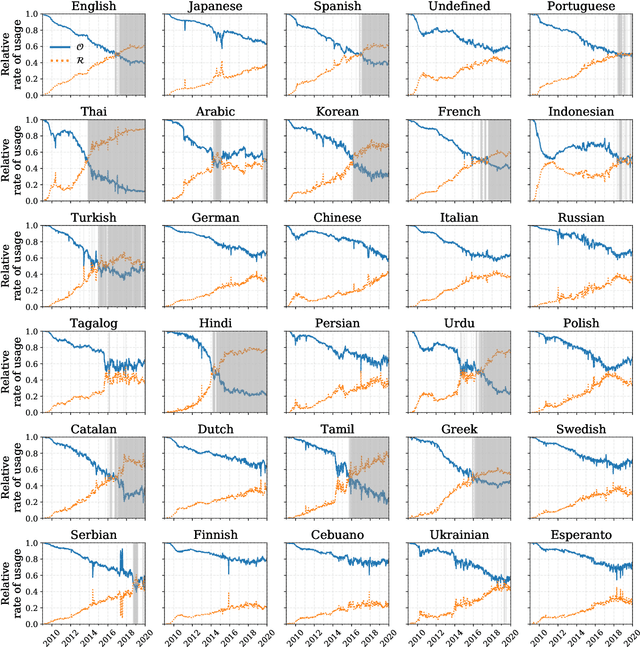
Working from a dataset of 118 billion messages running from the start of 2009 to the end of 2019, we identify and explore the relative daily use of over 150 languages on Twitter. We find that eight languages comprise 80% of all tweets, with English, Japanese, Spanish, and Portuguese being the most dominant. To quantify each language's level of being a Twitter `echo chamber' over time, we compute the `contagion ratio': the balance of retweets to organic messages. We find that for the most common languages on Twitter there is a growing tendency, though not universal, to retweet rather than share new content. By the end of 2019, the contagion ratios for half of the top 30 languages, including English and Spanish, had reached above 1---the naive contagion threshold. In 2019, the top 5 languages with the highest average daily ratios were, in order, Thai (7.3), Hindi, Tamil, Urdu, and Catalan, while the bottom 5 were Russian, Swedish, Esperanto, Cebuano, and Finnish (0.26). Further, we show that over time, the contagion ratios for most common languages are growing more strongly than those of rare languages.
Hahahahaha, Duuuuude, Yeeessss!: A two-parameter characterization of stretchable words and the dynamics of mistypings and misspellings
Jul 09, 2019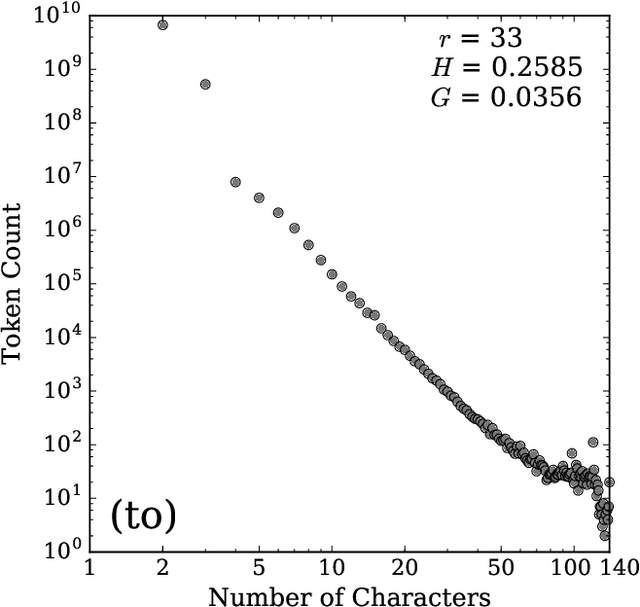

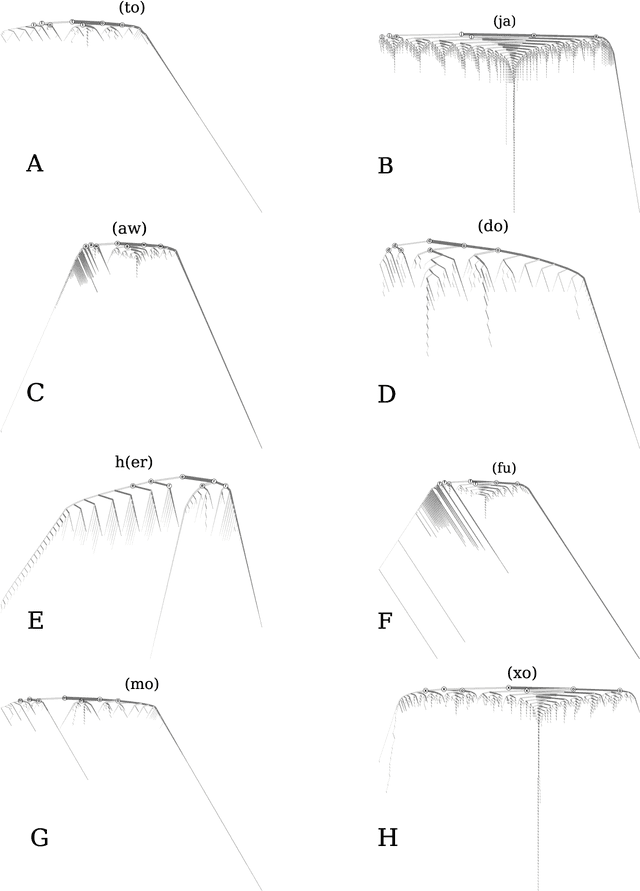
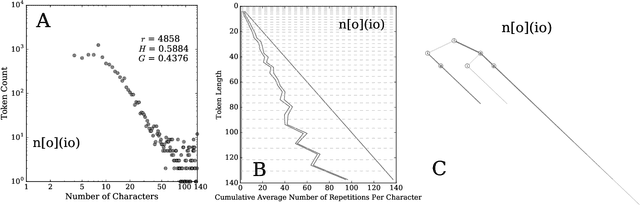
Stretched words like `heellllp' or `heyyyyy' are a regular feature of spoken language, often used to emphasize or exaggerate the underlying meaning of the root word. While stretched words are rarely found in formal written language and dictionaries, they are prevalent within social media. In this paper, we examine the frequency distributions of `stretchable words' found in roughly 100 billion tweets authored over an 8 year period. We introduce two central parameters, `balance' and `stretch', that capture their main characteristics, and explore their dynamics by creating visual tools we call `balance plots' and `spelling trees'. We discuss how the tools and methods we develop here could be used to study the statistical patterns of mistypings and misspellings, along with the potential applications in augmenting dictionaries, improving language processing, and in any area where sequence construction matters, such as genetics.
A Sentiment Analysis of Breast Cancer Treatment Experiences and Healthcare Perceptions Across Twitter
Oct 12, 2018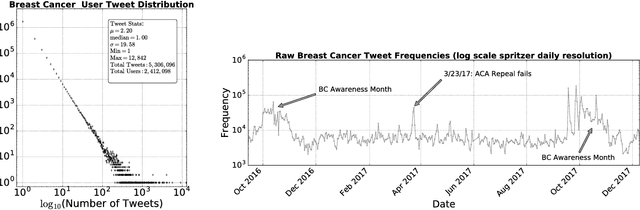
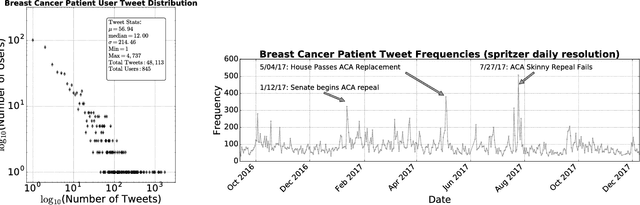
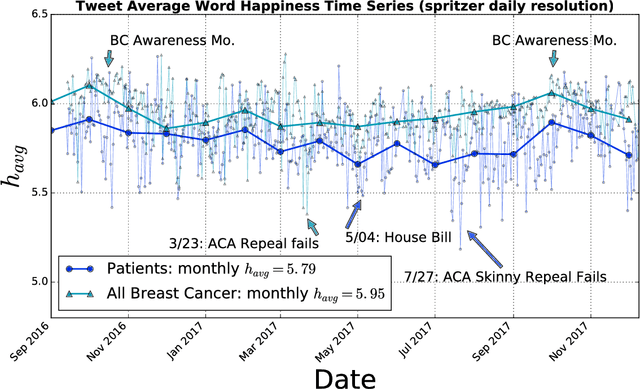
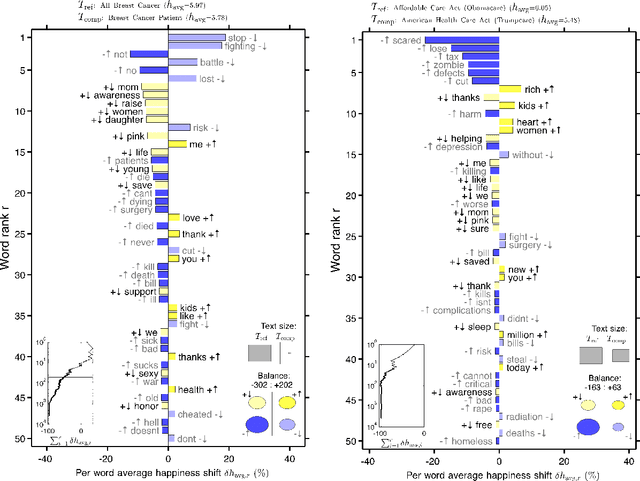
Background: Social media has the capacity to afford the healthcare industry with valuable feedback from patients who reveal and express their medical decision-making process, as well as self-reported quality of life indicators both during and post treatment. In prior work, [Crannell et. al.], we have studied an active cancer patient population on Twitter and compiled a set of tweets describing their experience with this disease. We refer to these online public testimonies as "Invisible Patient Reported Outcomes" (iPROs), because they carry relevant indicators, yet are difficult to capture by conventional means of self-report. Methods: Our present study aims to identify tweets related to the patient experience as an additional informative tool for monitoring public health. Using Twitter's public streaming API, we compiled over 5.3 million "breast cancer" related tweets spanning September 2016 until mid December 2017. We combined supervised machine learning methods with natural language processing to sift tweets relevant to breast cancer patient experiences. We analyzed a sample of 845 breast cancer patient and survivor accounts, responsible for over 48,000 posts. We investigated tweet content with a hedonometric sentiment analysis to quantitatively extract emotionally charged topics. Results: We found that positive experiences were shared regarding patient treatment, raising support, and spreading awareness. Further discussions related to healthcare were prevalent and largely negative focusing on fear of political legislation that could result in loss of coverage. Conclusions: Social media can provide a positive outlet for patients to discuss their needs and concerns regarding their healthcare coverage and treatment needs. Capturing iPROs from online communication can help inform healthcare professionals and lead to more connected and personalized treatment regimens.
Exposure to urban parks improves affect and reduces negativity on Twitter
Jul 20, 2018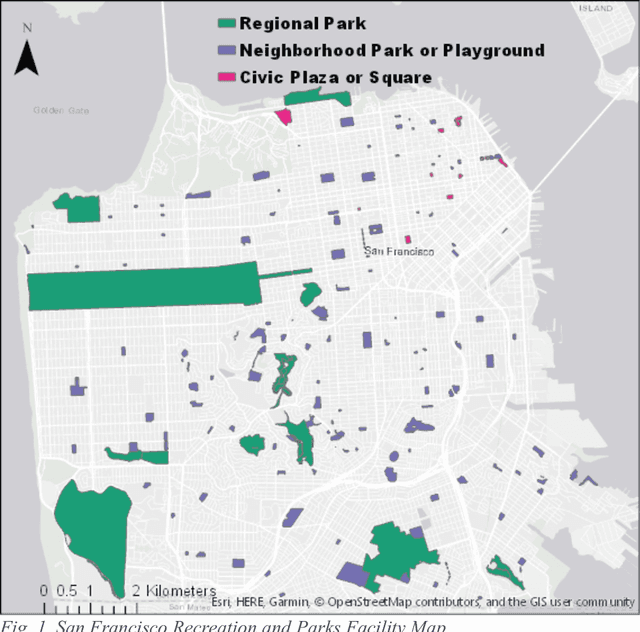
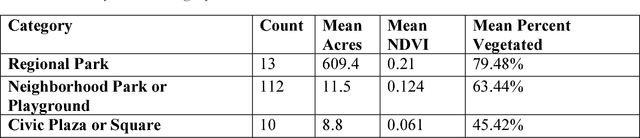
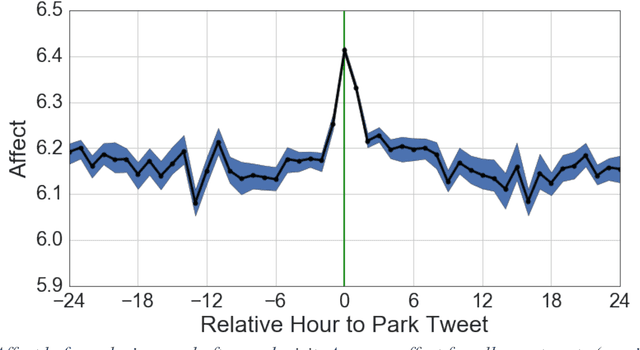
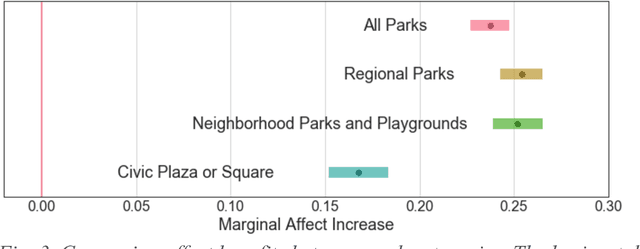
Urbanization and the decline of access to nature have coincided with a rise of mental health problems. A growing body of research has demonstrated an association between nature contact and improved mental affect (i.e., mood). However, previous approaches have been unable to quantify the benefits of urban greenspace exposure and compare how different types of outdoor public spaces impact mood. Here, we use Twitter to investigate how mental affect varies before, during, and after visits to a large urban park system. We analyze the sentiment of tweets to estimate the magnitude and duration of the affect benefit of visiting parks. We find that affect is substantially higher during park visits and remains elevated for several hours following the visit. Visits to Regional Parks, which are greener and have greater vegetative cover, result in a greater increase in affect compared to Civic Plazas and Squares. Finally, we analyze the words in tweets around park visits to explore several theorized mechanisms linking nature exposure with mental and cognitive benefits. Negation words such as "no", "not", and "don't" decrease in frequency during visits to urban parks. These results point to the most beneficial types of nature contact for mental health benefits and can be used by urban planners and public health officials to improve the well-being of growing urban populations.
English verb regularization in books and tweets
Mar 26, 2018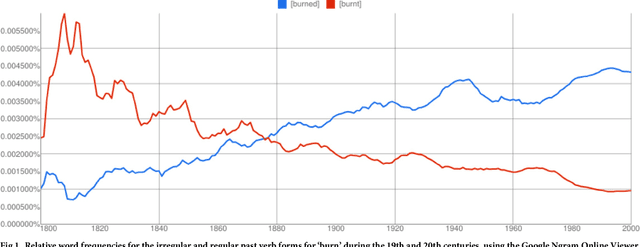
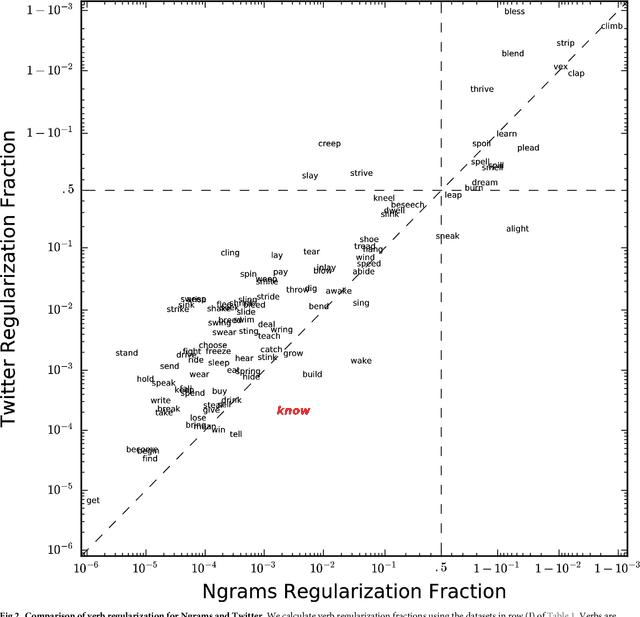

The English language has evolved dramatically throughout its lifespan, to the extent that a modern speaker of Old English would be incomprehensible without translation. One concrete indicator of this process is the movement from irregular to regular (-ed) forms for the past tense of verbs. In this study we quantify the extent of verb regularization using two vastly disparate datasets: (1) Six years of published books scanned by Google (2003--2008), and (2) A decade of social media messages posted to Twitter (2008--2017). We find that the extent of verb regularization is greater on Twitter, taken as a whole, than in English Fiction books. Regularization is also greater for tweets geotagged in the United States relative to American English books, but the opposite is true for tweets geotagged in the United Kingdom relative to British English books. We also find interesting regional variations in regularization across counties in the United States. However, once differences in population are accounted for, we do not identify strong correlations with socio-demographic variables such as education or income.