 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Carotid Intima-Media Thickness Video Interpretation with Convolutional Neural Networks
Jun 02, 2017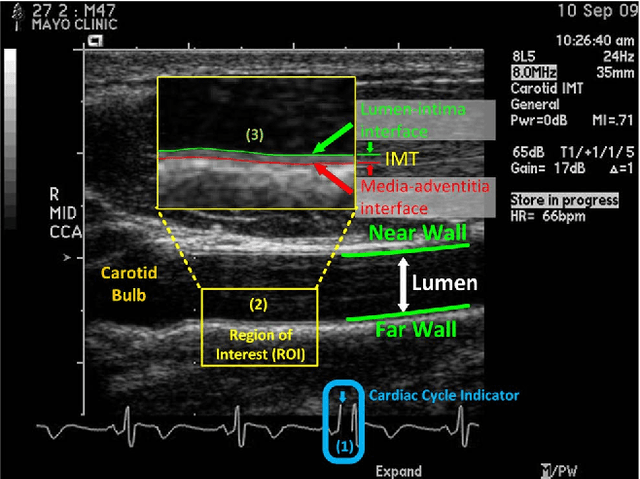
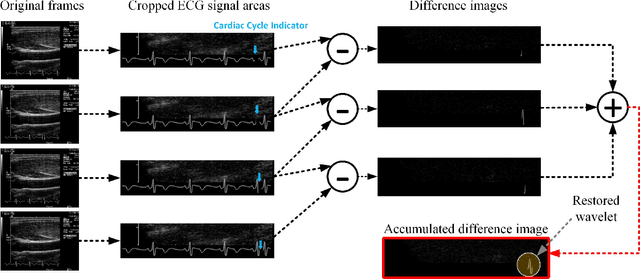
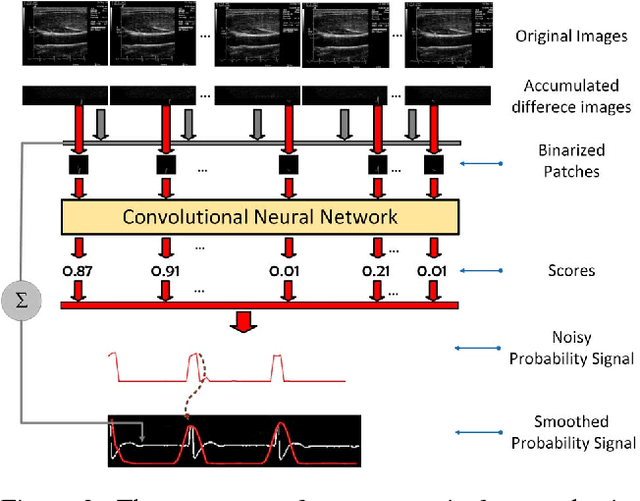
Cardiovascular disease (CVD) is the leading cause of mortality yet largely preventable, but the key to prevention is to identify at-risk individuals before adverse events. For predicting individual CVD risk, carotid intima-media thickness (CIMT), a noninvasive ultrasound method, has proven to be valuable, offering several advantages over CT coronary artery calcium score. However, each CIMT examination includes several ultrasound videos, and interpreting each of these CIMT videos involves three operations: (1) select three end-diastolic ultrasound frames (EUF) in the video, (2) localize a region of interest (ROI) in each selected frame, and (3) trace the lumen-intima interface and the media-adventitia interface in each ROI to measure CIMT. These operations are tedious, laborious, and time consuming, a serious limitation that hinders the widespread utilization of CIMT in clinical practice. To overcome this limitation, this paper presents a new system to automate CIMT video interpretation. Our extensive experiments demonstrate that the suggested system significantly outperforms the state-of-the-art methods. The superior performance is attributable to our unified framework based on convolutional neural networks (CNNs) coupled with our informative image representation and effective post-processing of the CNN outputs, which are uniquely designed for each of the above three operations.
Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning?
Jun 02, 2017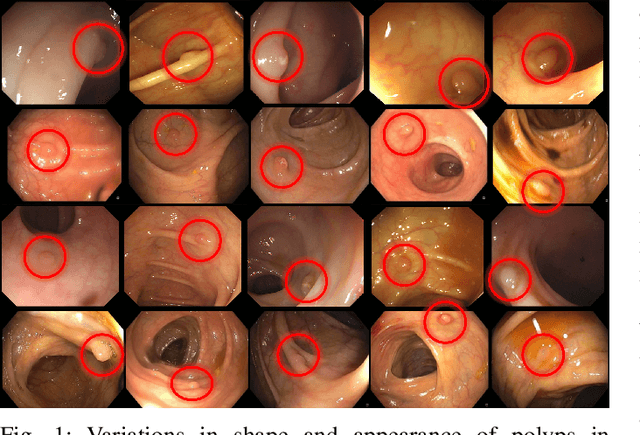
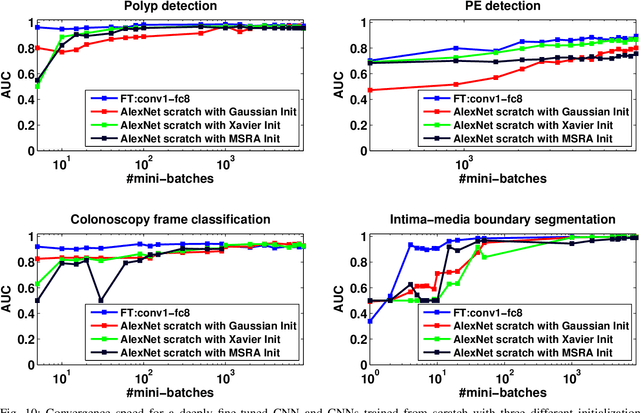
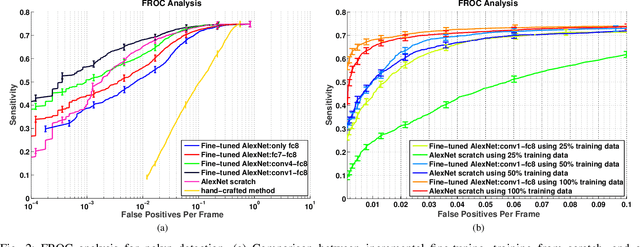
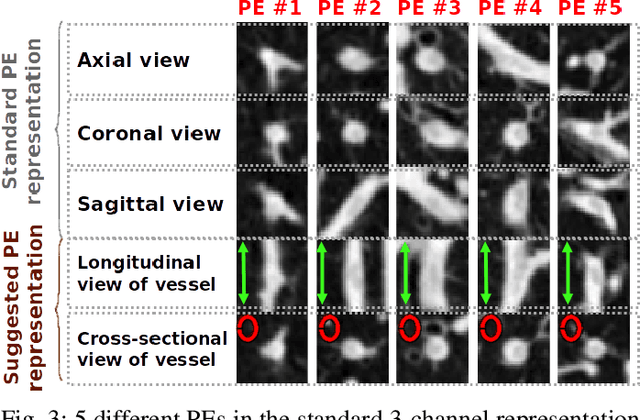
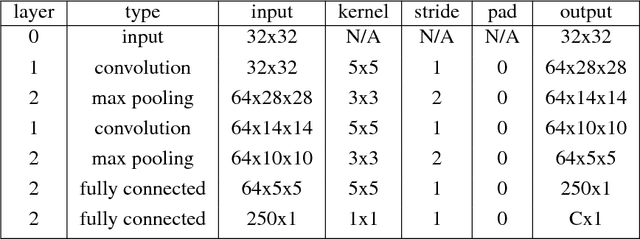
Training a deep convolutional neural network (CNN) from scratch is difficult because it requires a large amount of labeled training data and a great deal of expertise to ensure proper convergence. A promising alternative is to fine-tune a CNN that has been pre-trained using, for instance, a large set of labeled natural images. However, the substantial differences between natural and medical images may advise against such knowledge transfer. In this paper, we seek to answer the following central question in the context of medical image analysis: \emph{Can the use of pre-trained deep CNNs with sufficient fine-tuning eliminate the need for training a deep CNN from scratch?} To address this question, we considered 4 distinct medical imaging applications in 3 specialties (radiology, cardiology, and gastroenterology) involving classification, detection, and segmentation from 3 different imaging modalities, and investigated how the performance of deep CNNs trained from scratch compared with the pre-trained CNNs fine-tuned in a layer-wise manner. Our experiments consistently demonstrated that (1) the use of a pre-trained CNN with adequate fine-tuning outperformed or, in the worst case, performed as well as a CNN trained from scratch; (2) fine-tuned CNNs were more robust to the size of training sets than CNNs trained from scratch; (3) neither shallow tuning nor deep tuning was the optimal choice for a particular application; and (4) our layer-wise fine-tuning scheme could offer a practical way to reach the best performance for the application at hand based on the amount of available data.