 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile and Robust Transient Stability Assessment via Instance Transfer Learning
Feb 20, 2021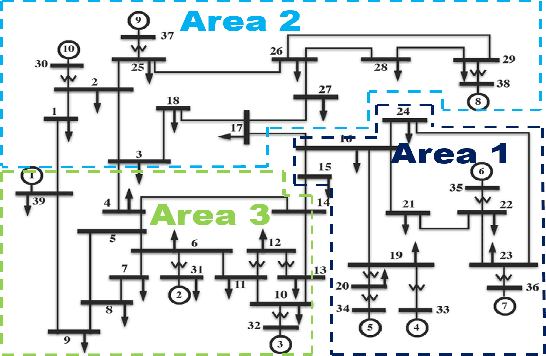
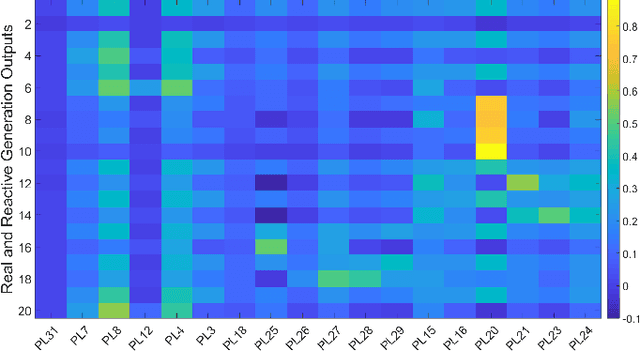
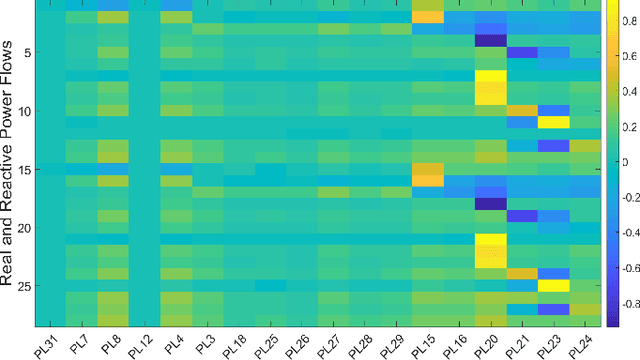
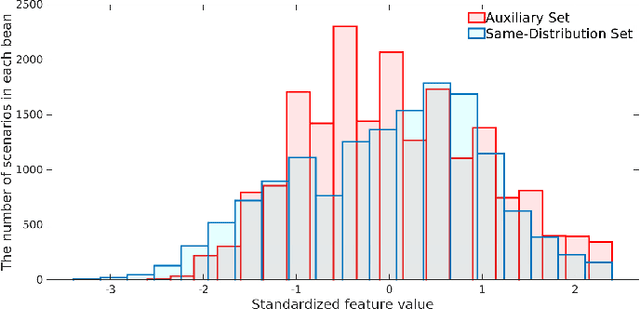
To support N-1 pre-fault transient stability assessment, this paper introduces a new data collection method in a data-driven algorithm incorporating the knowledge of power system dynamics. The domain knowledge on how the disturbance effect will propagate from the fault location to the rest of the network is leveraged to recognise the dominant conditions that determine the stability of a system. Accordingly, we introduce a new concept called Fault-Affected Area, which provides crucial information regarding the unstable region of operation. This information is embedded in an augmented dataset to train an ensemble model using an instance transfer learning framework. The test results on the IEEE 39-bus system verify that this model can accurately predict the stability of previously unseen operational scenarios while reducing the risk of false prediction of unstable instances compared to standard approaches.
SQAPlanner: Generating Data-InformedSoftware Quality Improvement Plans
Feb 19, 2021
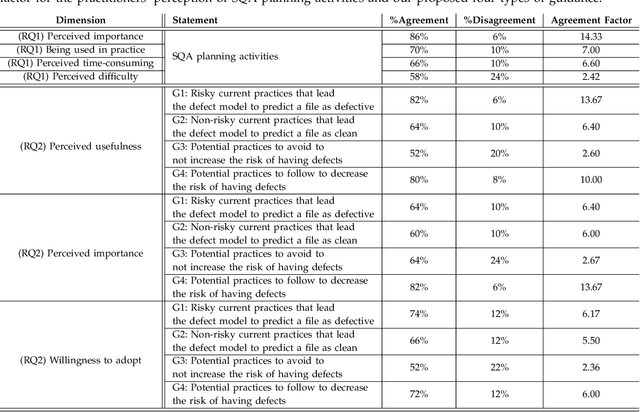
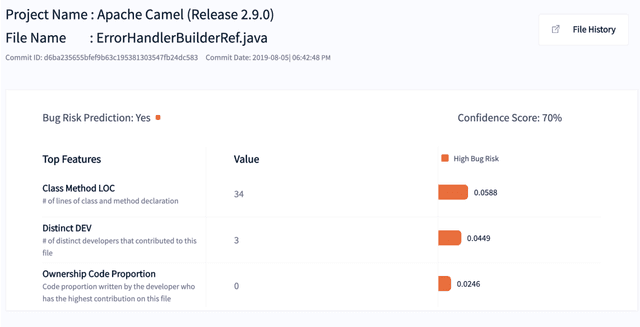
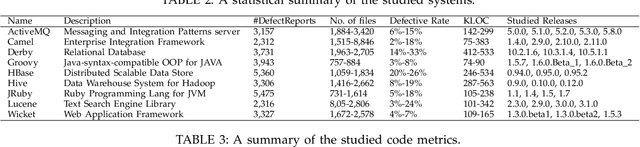
Software Quality Assurance (SQA) planning aims to define proactive plans, such as defining maximum file size, to prevent the occurrence of software defects in future releases. To aid this, defect prediction models have been proposed to generate insights as the most important factors that are associated with software quality. Such insights that are derived from traditional defect models are far from actionable-i.e., practitioners still do not know what they should do or avoid to decrease the risk of having defects, and what is the risk threshold for each metric. A lack of actionable guidance and risk threshold can lead to inefficient and ineffective SQA planning processes. In this paper, we investigate the practitioners' perceptions of current SQA planning activities, current challenges of such SQA planning activities, and propose four types of guidance to support SQA planning. We then propose and evaluate our AI-Driven SQAPlanner approach, a novel approach for generating four types of guidance and their associated risk thresholds in the form of rule-based explanations for the predictions of defect prediction models. Finally, we develop and evaluate an information visualization for our SQAPlanner approach. Through the use of qualitative survey and empirical evaluation, our results lead us to conclude that SQAPlanner is needed, effective, stable, and practically applicable. We also find that 80% of our survey respondents perceived that our visualization is more actionable. Thus, our SQAPlanner paves a way for novel research in actionable software analytics-i.e., generating actionable guidance on what should practitioners do and not do to decrease the risk of having defects to support SQA planning.
MultiRocket: Effective summary statistics for convolutional outputs in time series classification
Jan 31, 2021
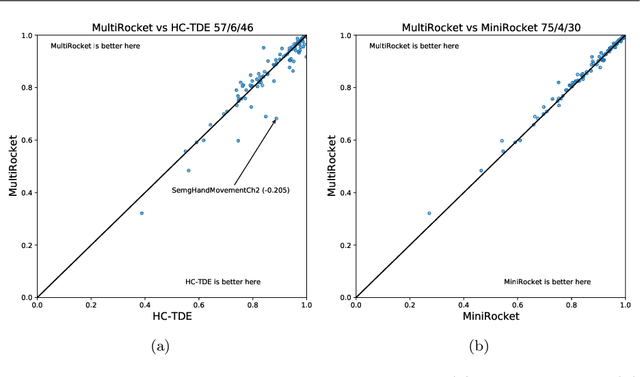

Rocket and MiniRocket, while two of the fastest methods for time series classification, are both somewhat less accurate than the current most accurate methods (namely, HIVE-COTE and its variants). We show that it is possible to significantly improve the accuracy of MiniRocket (and Rocket), with some additional computational expense, by expanding the set of features produced by the transform, making MultiRocket (for MiniRocket with Multiple Features) overall the single most accurate method on the datasets in the UCR archive, while still being orders of magnitude faster than any algorithm of comparable accuracy other than its precursors
Ensembles of Localised Models for Time Series Forecasting
Dec 30, 2020

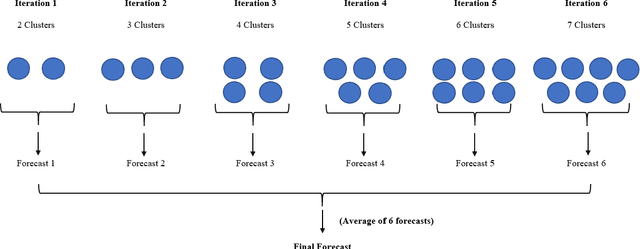
With large quantities of data typically available nowadays, forecasting models that are trained across sets of time series, known as Global Forecasting Models (GFM), are regularly outperforming traditional univariate forecasting models that work on isolated series. As GFMs usually share the same set of parameters across all time series, they often have the problem of not being localised enough to a particular series, especially in situations where datasets are heterogeneous. We study how ensembling techniques can be used with generic GFMs and univariate models to solve this issue. Our work systematises and compares relevant current approaches, namely clustering series and training separate submodels per cluster, the so-called ensemble of specialists approach, and building heterogeneous ensembles of global and local models. We fill some gaps in the approaches and generalise them to different underlying GFM model types. We then propose a new methodology of clustered ensembles where we train multiple GFMs on different clusters of series, obtained by changing the number of clusters and cluster seeds. Using Feed-forward Neural Networks, Recurrent Neural Networks, and Pooled Regression models as the underlying GFMs, in our evaluation on six publicly available datasets, the proposed models are able to achieve significantly higher accuracy than baseline GFM models and univariate forecasting methods.
Global Models for Time Series Forecasting: A Simulation Study
Dec 23, 2020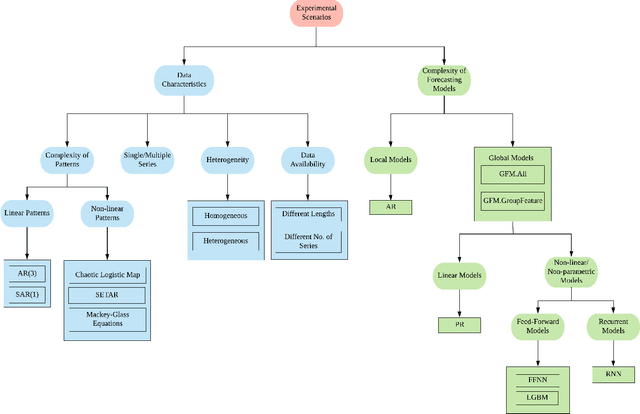
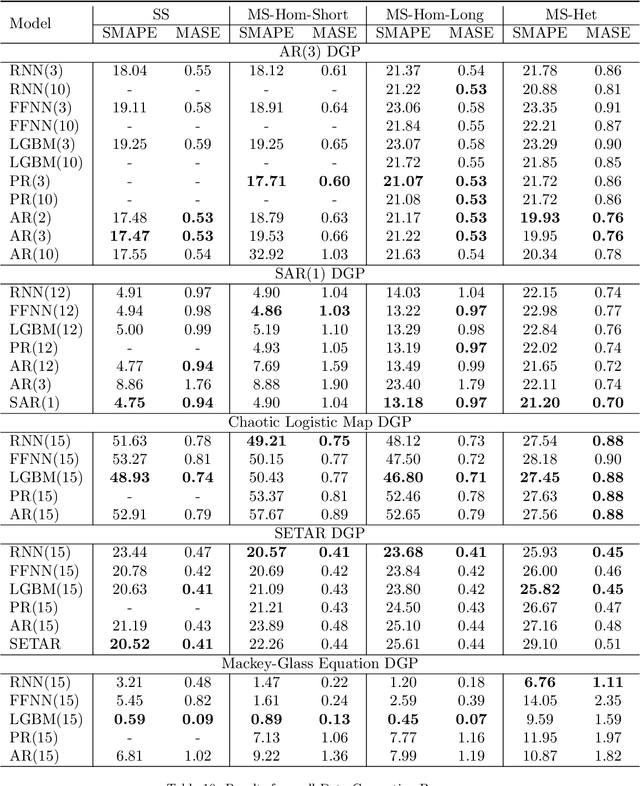
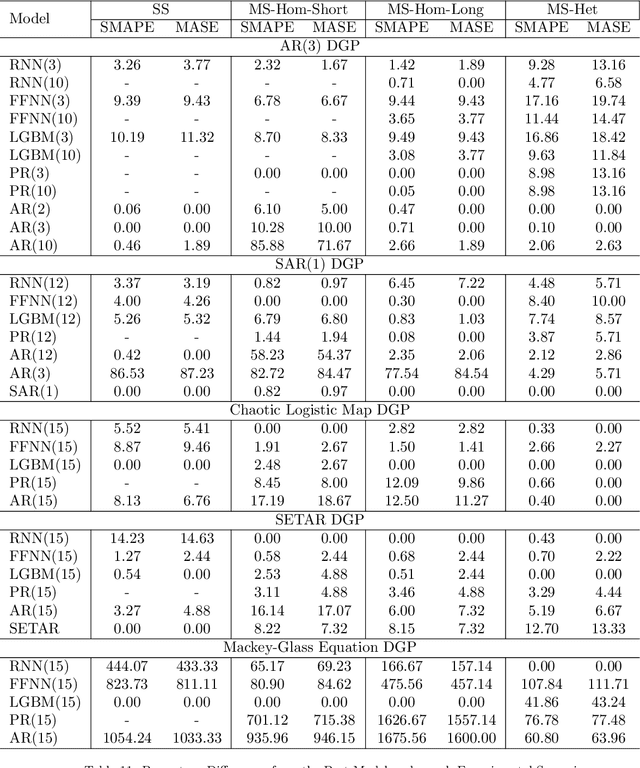
In the current context of Big Data, the nature of many forecasting problems has changed from predicting isolated time series to predicting many time series from similar sources. This has opened up the opportunity to develop competitive global forecasting models that simultaneously learn from many time series. But, it still remains unclear when global forecasting models can outperform the univariate benchmarks, especially along the dimensions of the homogeneity/heterogeneity of series, the complexity of patterns in the series, the complexity of forecasting models, and the lengths/number of series. Our study attempts to address this problem through investigating the effect from these factors, by simulating a number of datasets that have controllable time series characteristics. Specifically, we simulate time series from simple data generating processes (DGP), such as Auto Regressive (AR) and Seasonal AR, to complex DGPs, such as Chaotic Logistic Map, Self-Exciting Threshold Auto-Regressive, and Mackey-Glass Equations. The data heterogeneity is introduced by mixing time series generated from several DGPs into a single dataset. The lengths and the number of series in the dataset are varied in different scenarios. We perform experiments on these datasets using global forecasting models including Recurrent Neural Networks (RNN), Feed-Forward Neural Networks, Pooled Regression (PR) models and Light Gradient Boosting Models (LGBM), and compare their performance against standard statistical univariate forecasting techniques. Our experiments demonstrate that when trained as global forecasting models, techniques such as RNNs and LGBMs, which have complex non-linear modelling capabilities, are competitive methods in general under challenging forecasting scenarios such as series having short lengths, datasets with heterogeneous series and having minimal prior knowledge of the patterns of the series.
Model selection in reconciling hierarchical time series
Oct 29, 2020
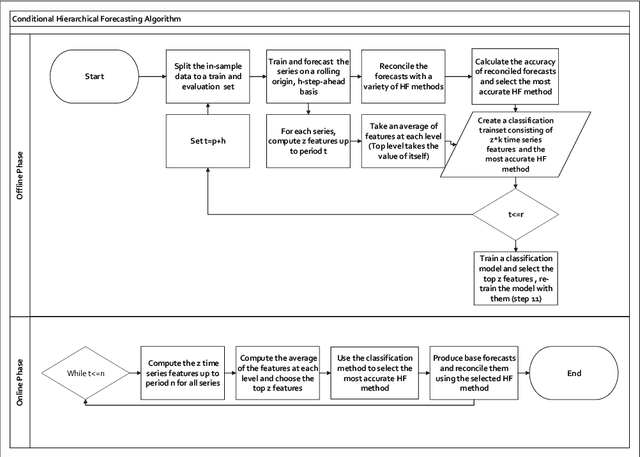
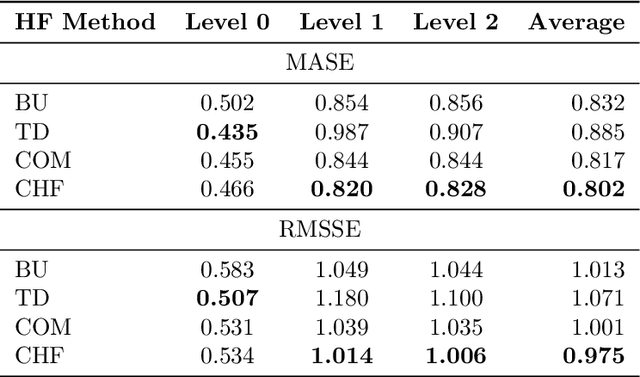
Model selection has been proven an effective strategy for improving accuracy in time series forecasting applications. However, when dealing with hierarchical time series, apart from selecting the most appropriate forecasting model, forecasters have also to select a suitable method for reconciling the base forecasts produced for each series to make sure they are coherent. Although some hierarchical forecasting methods like minimum trace are strongly supported both theoretically and empirically for reconciling the base forecasts, there are still circumstances under which they might not produce the most accurate results, being outperformed by other methods. In this paper we propose an approach for dynamically selecting the most appropriate hierarchical forecasting method and succeeding better forecasting accuracy along with coherence. The approach, to be called conditional hierarchical forecasting, is based on Machine Learning classification methods and uses time series features as leading indicators for performing the selection for each hierarchy examined considering a variety of alternatives. Our results suggest that conditional hierarchical forecasting leads to significantly more accurate forecasts than standard approaches, especially at lower hierarchical levels.
A Strong Baseline for Weekly Time Series Forecasting
Oct 16, 2020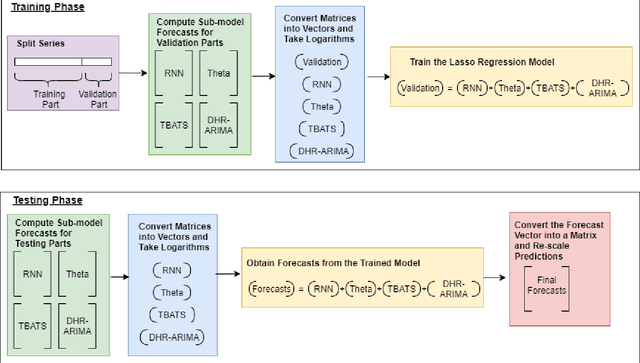

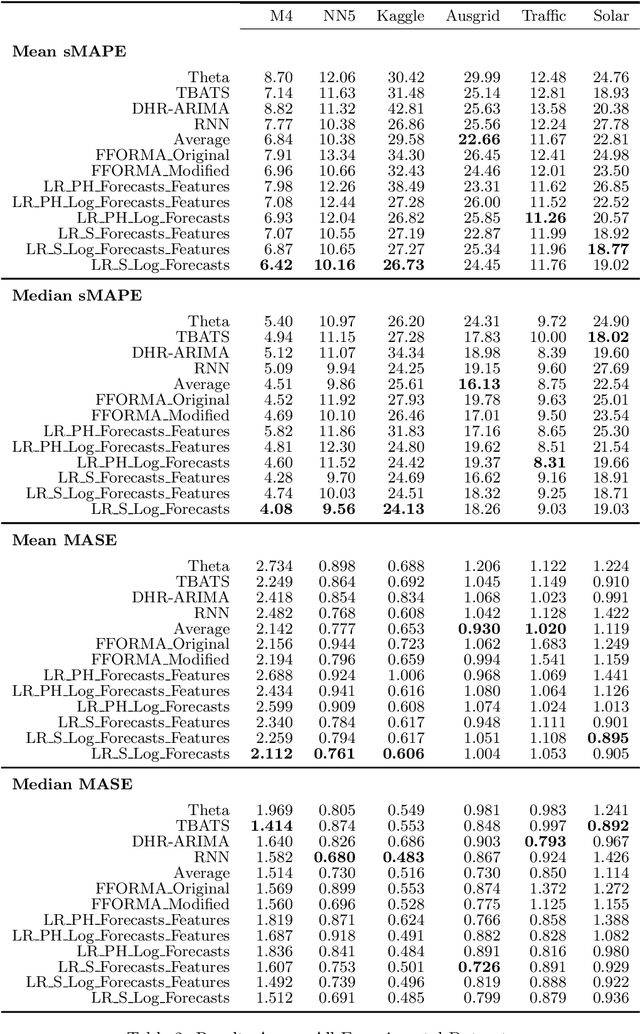
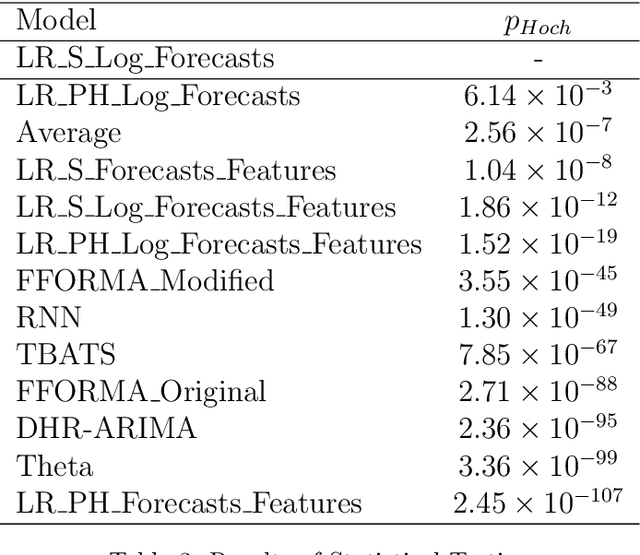
Many businesses and industries require accurate forecasts for weekly time series nowadays. The forecasting literature however does not currently provide easy-to-use, automatic, reproducible and accurate approaches dedicated to this task. We propose a forecasting method that can be used as a strong baseline in this domain, leveraging state-of-the-art forecasting techniques, forecast combination, and global modelling. Our approach uses four base forecasting models specifically suitable for forecasting weekly data: a global Recurrent Neural Network model, Theta, Trigonometric Box-Cox ARMA Trend Seasonal (TBATS), and Dynamic Harmonic Regression ARIMA (DHR-ARIMA). Those are then optimally combined using a lasso regression stacking approach. We evaluate the performance of our method against a set of state-of-the-art weekly forecasting models on six datasets. Across four evaluation metrics, we show that our method consistently outperforms the benchmark methods by a considerable margin with statistical significance. In particular, our model can produce the most accurate forecasts, in terms of mean sMAPE, for the M4 weekly dataset.
Improving the Accuracy of Global Forecasting Models using Time Series Data Augmentation
Aug 06, 2020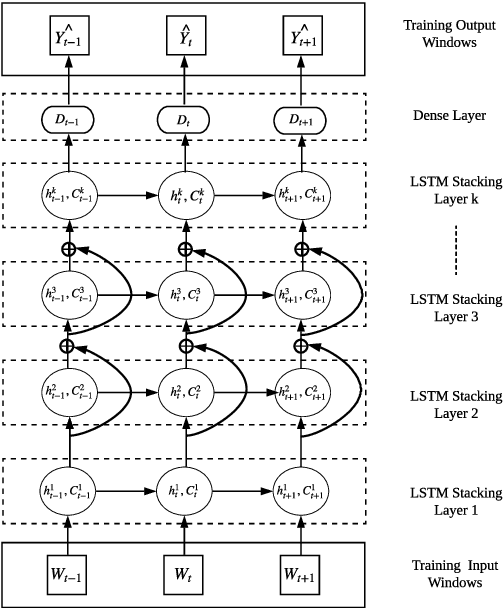
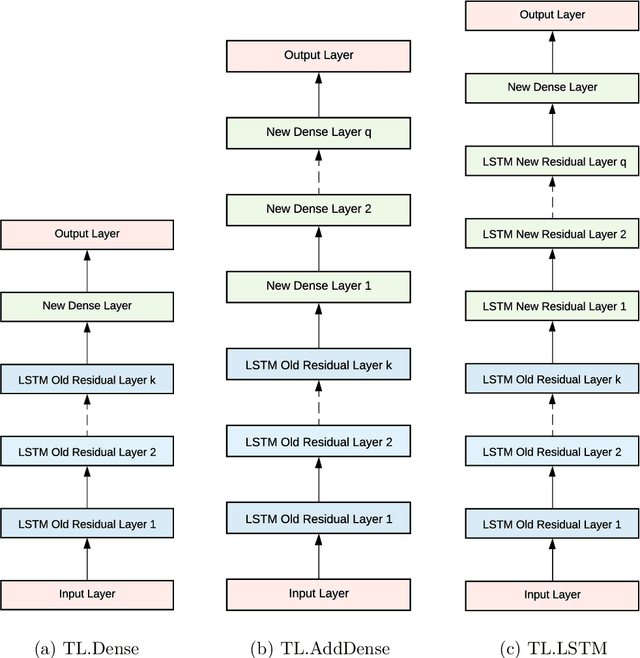
Forecasting models that are trained across sets of many time series, known as Global Forecasting Models (GFM), have shown recently promising results in forecasting competitions and real-world applications, outperforming many state-of-the-art univariate forecasting techniques. In most cases, GFMs are implemented using deep neural networks, and in particular Recurrent Neural Networks (RNN), which require a sufficient amount of time series to estimate their numerous model parameters. However, many time series databases have only a limited number of time series. In this study, we propose a novel, data augmentation based forecasting framework that is capable of improving the baseline accuracy of the GFM models in less data-abundant settings. We use three time series augmentation techniques: GRATIS, moving block bootstrap (MBB), and dynamic time warping barycentric averaging (DBA) to synthetically generate a collection of time series. The knowledge acquired from these augmented time series is then transferred to the original dataset using two different approaches: the pooled approach and the transfer learning approach. When building GFMs, in the pooled approach, we train a model on the augmented time series alongside the original time series dataset, whereas in the transfer learning approach, we adapt a pre-trained model to the new dataset. In our evaluation on competition and real-world time series datasets, our proposed variants can significantly improve the baseline accuracy of GFM models and outperform state-of-the-art univariate forecasting methods.
Seasonal Averaged One-Dependence Estimators: A Novel Algorithm to Address Seasonal Concept Drift in High-Dimensional Stream Classification
Jun 27, 2020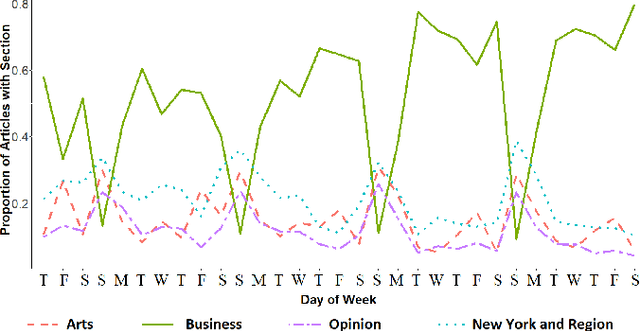
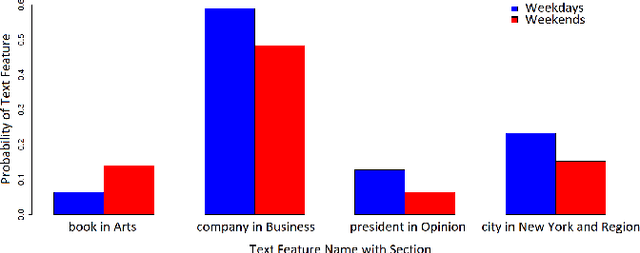
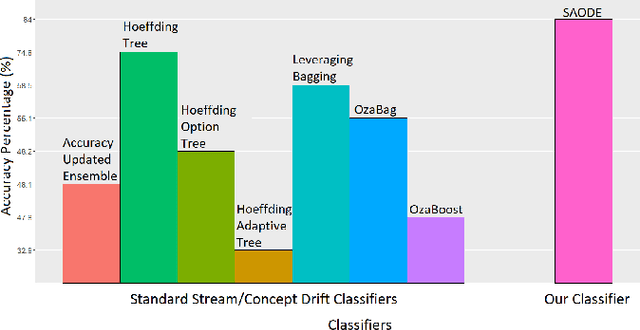

Stream classification methods classify a continuous stream of data as new labelled samples arrive. They often also have to deal with concept drift. This paper focuses on seasonal drift in stream classification, which can be found in many real-world application data sources. Traditional approaches of stream classification consider seasonal drift by including seasonal dummy/indicator variables or building separate models for each season. But these approaches have strong limitations in high-dimensional classification problems, or with complex seasonal patterns. This paper explores how to best handle seasonal drift in the specific context of news article categorization (or classification/tagging), where seasonal drift is overwhelmingly the main type of drift present in the data, and for which the data are high-dimensional. We introduce a novel classifier named Seasonal Averaged One-Dependence Estimators (SAODE), which extends the AODE classifier to handle seasonal drift by including time as a super parent. We assess our SAODE model using two large real-world text mining related datasets each comprising approximately a million records, against nine state-of-the-art stream and concept drift classification models, with and without seasonal indicators and with separate models built for each season. Across five different evaluation techniques, we show that our model consistently outperforms other methods by a large margin where the results are statistically significant.
Simulation and Optimisation of Air Conditioning Systems using Machine Learning
Jun 27, 2020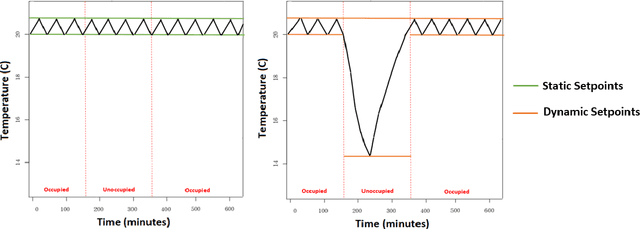
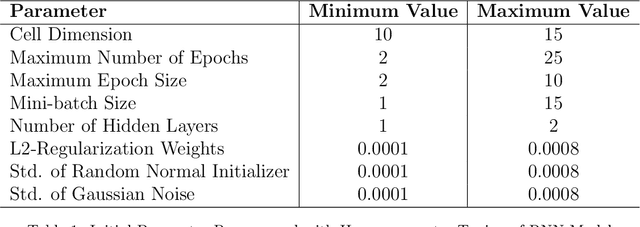


In building management, usually static thermal setpoints are used to maintain the inside temperature of a building at a comfortable level irrespective of its occupancy. This strategy can cause a massive amount of energy wastage and therewith increase energy related expenses. This paper explores how to optimise the setpoints used in a particular room during its unoccupied periods using machine learning approaches. We introduce a deep-learning model based on Recurrent Neural Networks (RNN) that can predict the temperatures of a future period directly where a particular room is unoccupied and by using these predicted temperatures, we define the optimal thermal setpoints to be used inside the room during the unoccupied period. We show that RNNs are particularly suitable for this learning task as they enable us to learn across many relatively short series, which is necessary to focus on particular operation modes of the air conditioning (AC) system. We evaluate the prediction accuracy of our RNN model against a set of state-of-the-art models and are able to outperform those by a large margin. We furthermore analyse the usage of our RNN model in optimising the energy consumption of an AC system in a real-world scenario using the temperature data from a university lecture theatre. Based on the simulations, we show that our RNN model can lead to savings around 20% compared with the traditional temperature controlling model that does not use optimisation techniques.