 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Means: A Dynamic Framework for Predicting Customer Satisfaction
Nov 18, 2025Online ratings influence customer decision-making, yet standard aggregation methods, such as the sample mean, fail to adapt to quality changes over time and ignore review heterogeneity (e.g., review sentiment, a review's helpfulness). To address these challenges, we demonstrate the value of using the Gaussian process (GP) framework for rating aggregation. Specifically, we present a tailored GP model that captures the dynamics of ratings over time while additionally accounting for review heterogeneity. Based on 121,123 ratings from Yelp, we compare the predictive power of different rating aggregation methods in predicting future ratings, thereby finding that the GP model is considerably more accurate and reduces the mean absolute error by 10.2% compared to the sample mean. Our findings have important implications for marketing practitioners and customers. By moving beyond means, designers of online reputation systems can display more informative and adaptive aggregated rating scores that are accurate signals of expected customer satisfaction.
Data-driven subgrouping of patient trajectories with chronic diseases: Evidence from low back pain
Apr 16, 2024Clinical data informs the personalization of health care with a potential for more effective disease management. In practice, this is achieved by subgrouping, whereby clusters with similar patient characteristics are identified and then receive customized treatment plans with the goal of targeting subgroup-specific disease dynamics. In this paper, we propose a novel mixture hidden Markov model for subgrouping patient trajectories from chronic diseases. Our model is probabilistic and carefully designed to capture different trajectory phases of chronic diseases (i.e., "severe", "moderate", and "mild") through tailored latent states. We demonstrate our subgrouping framework based on a longitudinal study across 847 patients with non-specific low back pain. Here, our subgrouping framework identifies 8 subgroups. Further, we show that our subgrouping framework outperforms common baselines in terms of cluster validity indices. Finally, we discuss the applicability of the model to other chronic and long-lasting diseases.
Web Mining to Inform Locations of Charging Stations for Electric Vehicles
Mar 10, 2022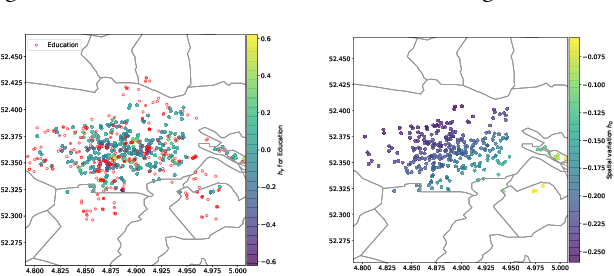
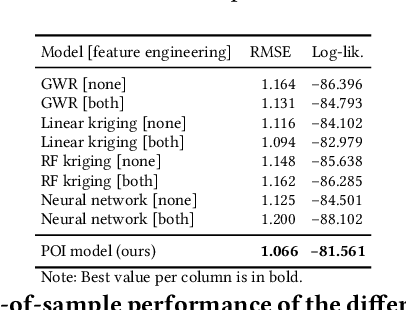
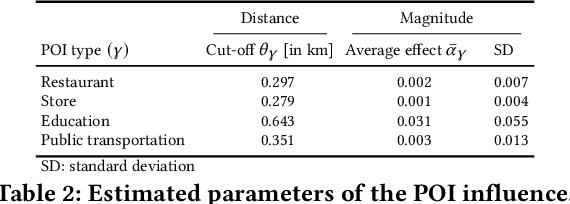

The availability of charging stations is an important factor for promoting electric vehicles (EVs) as a carbon-friendly way of transportation. Hence, for city planners, the crucial question is where to place charging stations so that they reach a large utilization. Here, we hypothesize that the utilization of EV charging stations is driven by the proximity to points-of-interest (POIs), as EV owners have a certain limited willingness to walk between charging stations and POIs. To address our research question, we propose the use of web mining: we characterize the influence of different POIs from OpenStreetMap on the utilization of charging stations. For this, we present a tailored interpretable model that takes into account the full spatial distributions of both the POIs and the charging stations. This allows us then to estimate the distance and magnitude of the influence of different POI types. We evaluate our model with data from approx. 300 charging stations and 4,000 POIs in Amsterdam, Netherlands. Our model achieves a superior performance over state-of-the-art baselines and, on top of that, is able to offer an unmatched level of interpretability. To the best of our knowledge, no previous paper has quantified the POI influence on charging station utilization from real-world usage data by estimating the spatial proximity in which POIs are relevant. As such, our findings help city planners in identifying effective locations for charging stations.