 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHold-One-Shot-Out (HOSO) for Validation-Free Few-Shot CLIP Adapters
Mar 04, 2026In many CLIP adaptation methods, a blending ratio hyperparameter controls the trade-off between general pretrained CLIP knowledge and the limited, dataset-specific supervision from the few-shot cases. Most few-shot CLIP adaptation techniques report results by ablation of the blending ratio on the test set or require additional validation sets to select the blending ratio per dataset, and thus are not strictly few-shot. We present a simple, validation-free method for learning the blending ratio in CLIP adaptation. Hold-One-Shot-Out (HOSO) presents a novel approach for CLIP-Adapter-style methods to compete in the newly established validation-free setting. CLIP-Adapter with HOSO (HOSO-Adapter) learns the blending ratio using a one-shot, hold-out set, while the adapter trains on the remaining few-shot support examples. Under the validation-free few-shot protocol, HOSO-Adapter outperforms the CLIP-Adapter baseline by more than 4 percentage points on average across 11 standard few-shot datasets. Interestingly, in the 8- and 16-shot settings, HOSO-Adapter outperforms CLIP-Adapter even with the optimal blending ratio selected on the test set. Ablation studies validate the use of a one-shot hold-out mechanism, decoupled training, and improvements over the naively learnt blending ratio baseline. Code is released here: https://github.com/chris-vorster/HOSO-Adapter
Underrepresented in Foundation Model Pretraining Data? A One-Shot Probe
Mar 04, 2026Large-scale Vision-Language Foundation Models (VLFMs), such as CLIP, now underpin a wide range of computer vision research and applications. VLFMs are often adapted to various domain-specific tasks. However, VLFM performance on novel, specialised, or underrepresented domains remains inconsistent. Evaluating VLFMs typically requires labelled test sets, which are often unavailable for niche domains of interest, particularly those from the Global South. We address this gap by proposing a highly data-efficient method to predict a VLFM's zero-shot accuracy on a target domain using only a single labelled image per class. Our approach uses a Large Language Model to generate plausible counterfactual descriptions of a given image. By measuring the VLFM's ability to distinguish the correct description from these hard negatives, we engineer features that capture the VLFM's discriminative power in its shared embedding space. A linear regressor trained on these similarity scores estimates the VLFM's zero-shot test accuracy across various visual domains with a Pearson-r correlation of 0.96. We demonstrate our method's performance across five diverse datasets, including standard benchmark datasets and underrepresented datasets from Africa. Our work provides a low-cost, reliable tool for probing VLFMs, enabling researchers and practitioners to make informed decisions about data annotation efforts before committing significant resources. The model training code, generated captions and counterfactuals are released here: https://github.com/chris-vorster/PreLabellingProbe.
Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts
Aug 08, 2023



Contrastive pretrained large Vision-Language Models (VLMs) like CLIP have revolutionized visual representation learning by providing good performance on downstream datasets. VLMs are 0-shot adapted to a downstream dataset by designing prompts that are relevant to the dataset. Such prompt engineering makes use of domain expertise and a validation dataset. Meanwhile, recent developments in generative pretrained models like GPT-4 mean they can be used as advanced internet search tools. They can also be manipulated to provide visual information in any structure. In this work, we show that GPT-4 can be used to generate text that is visually descriptive and how this can be used to adapt CLIP to downstream tasks. We show considerable improvements in 0-shot transfer accuracy on specialized fine-grained datasets like EuroSAT (~7%), DTD (~7%), SUN397 (~4.6%), and CUB (~3.3%) when compared to CLIP's default prompt. We also design a simple few-shot adapter that learns to choose the best possible sentences to construct generalizable classifiers that outperform the recently proposed CoCoOP by ~2% on average and by over 4% on 4 specialized fine-grained datasets. The code, prompts, and auxiliary text dataset is available at https://github.com/mayug/VDT-Adapter.
A Machine Learning Approach to Digital Contact Tracing: TC4TL Challenge
Mar 08, 2022
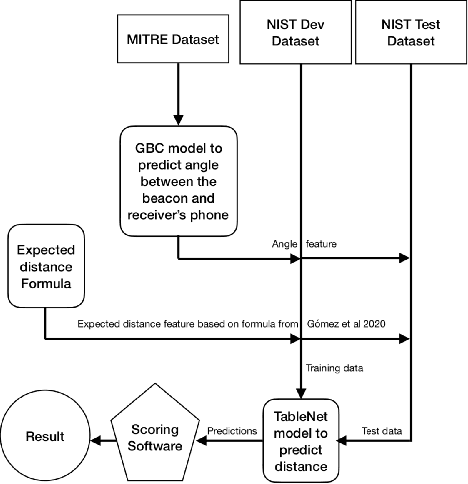
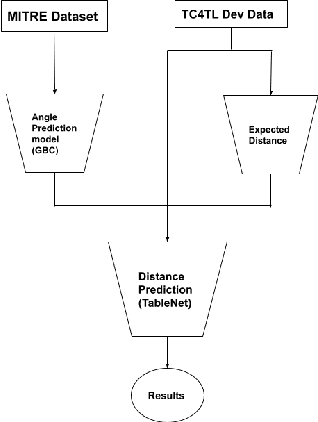
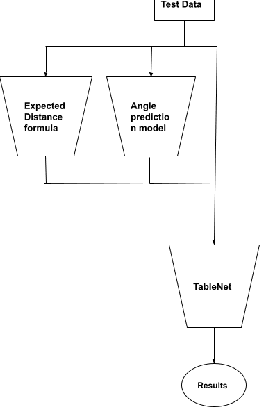
Contact tracing is a method used by public health organisations to try prevent the spread of infectious diseases in the community. Traditionally performed by manual contact tracers, more recently the use of apps have been considered utilising phone sensor data to determine the distance between two phones. In this paper, we investigate the development of machine learning approaches to determine the distance between two mobile phone devices using Bluetooth Low Energy, sensory data and meta data. We use TableNet architecture and feature engineering to improve on the existing state of the art (total nDCF 0.21 vs 2.08), significantly outperforming existing models.