 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in Neural Networks: A Broad Survey
Sep 04, 2022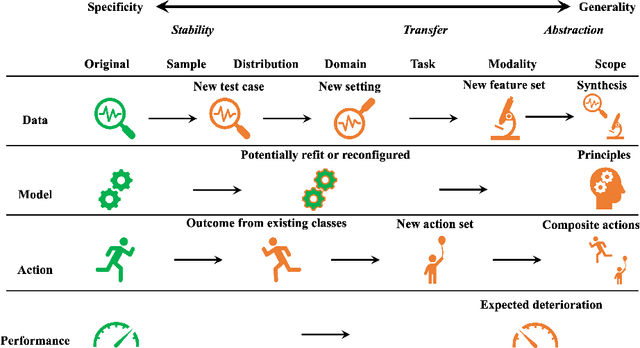
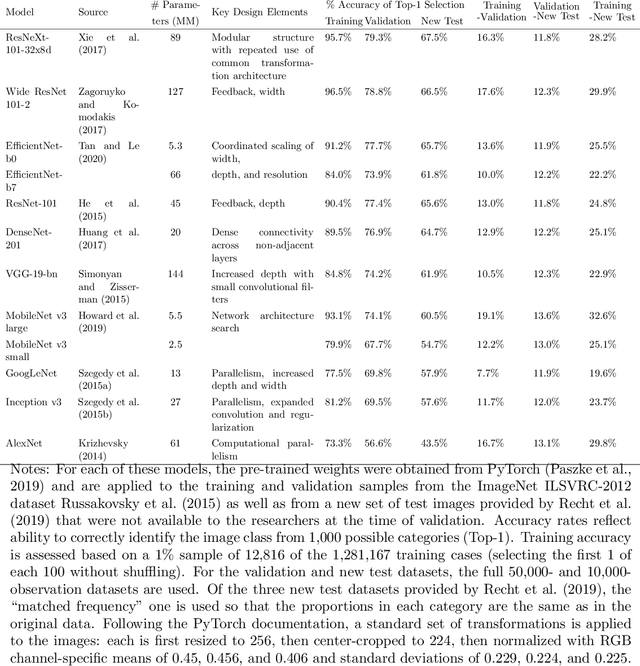
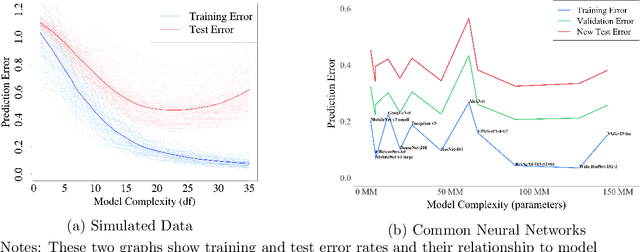
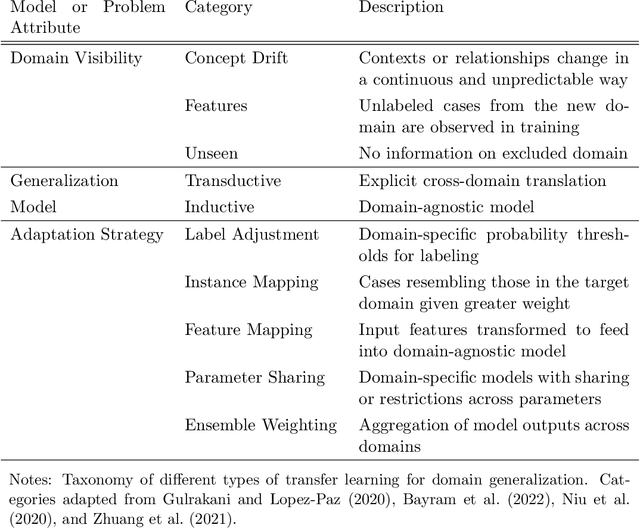
This paper reviews concepts, modeling approaches, and recent findings along a spectrum of different levels of abstraction of neural network models including generalization across (1) Samples, (2) Distributions, (3) Domains, (4) Tasks, (5) Modalities, and (6) Scopes. Results on (1) sample generalization show that, in the case of ImageNet, nearly all the recent improvements reduced training error while overfitting stayed flat; with nearly all the training error eliminated, future progress will require a focus on reducing overfitting. Perspectives from statistics highlight how (2) distribution generalization can be viewed alternately as a change in sample weights or a change in the input-output relationship. Transfer learning approaches to (3) domain generalization are summarized, as are recent advances and the wealth of domain adaptation benchmark datasets available. Recent breakthroughs surveyed in (4) task generalization include few-shot meta-learning approaches and the BERT NLP engine, and recent (5) modality generalization studies are discussed that integrate image and text data and that apply a biologically-inspired network across olfactory, visual, and auditory modalities. Recent (6) scope generalization results are reviewed that embed knowledge graphs into deep NLP approaches. Additionally, concepts from neuroscience are discussed on the modular architecture of brains and the steps by which dopamine-driven conditioning leads to abstract thinking.
Problem-dependent attention and effort in neural networks with an application to image resolution
Jan 05, 2022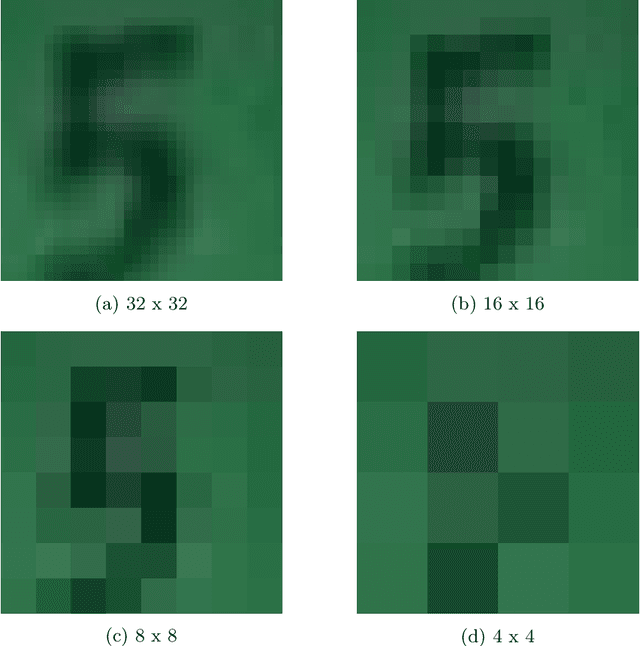
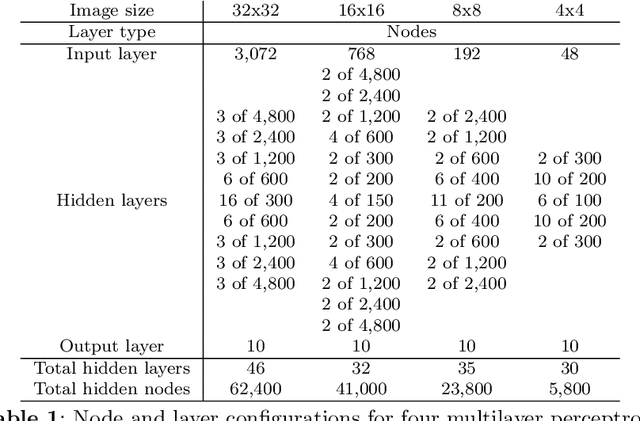
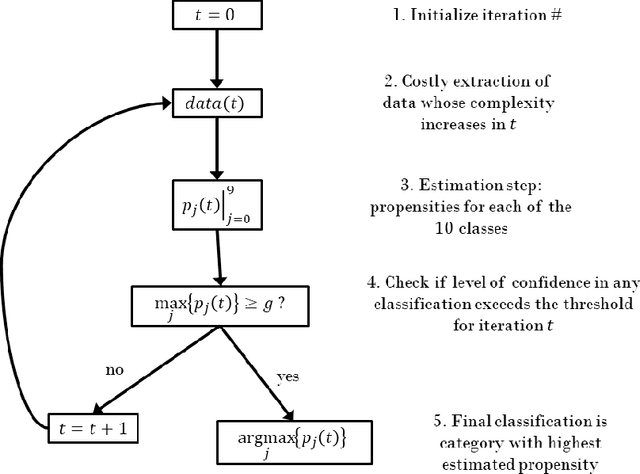
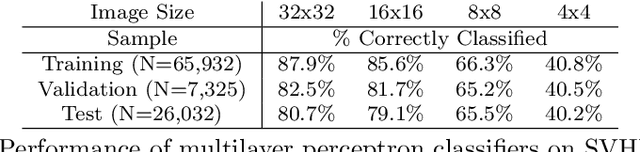
This paper introduces a new neural network-based estimation approach that is inspired by the biological phenomenon whereby humans and animals vary the levels of attention and effort that they dedicate to a problem depending upon its difficulty. The proposed approach leverages alternate models' internal levels of confidence in their own projections. If the least costly model is confident in its classification, then that is the classification used; if not, the model with the next lowest cost of implementation is run, and so on. This use of successively more complex models -- together with the models' internal propensity scores to evaluate their likelihood of being correct -- makes it possible to substantially reduce resource use while maintaining high standards for classification accuracy. The approach is applied to the digit recognition problem from Google's Street View House Numbers dataset, using Multilayer Perceptron (MLP) neural networks trained on high- and low-resolution versions of the digit images. The algorithm examines the low-resolution images first, only moving to higher resolution images if the classification from the initial low-resolution pass does not have a high degree of confidence. For the MLPs considered here, this sequential approach enables a reduction in resource usage of more than 50\% without any sacrifice in classification accuracy.