 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Path-Following Guidance via Nonlinear Model Predictive Control for Fixed-Wing Small UAS
Dec 30, 2025This paper presents the design, implementation, and flight test results of two novel 3D path-following guidance algorithms based on nonlinear model predictive control (MPC), with specific application to fixed-wing small uncrewed aircraft systems. To enable MPC, control-augmented modelling and system identification of the RAAVEN small uncrewed aircraft is presented. Two formulations of MPC are then showcased. The first schedules a static reference path rate over the MPC horizon, incentivizing a constant inertial speed. The second, with inspiration from model predictive contouring control, dynamically optimizes for the reference path rate over the controller horizon as the system operates. This allows for a weighted tradeoff between path progression and distance from path, two competing objectives in path-following guidance. Both controllers are formulated to operate over general smooth 3D arc-length parameterized curves. The MPC guidance algorithms are flown over several high-curvature test paths, with comparison to a baseline lookahead guidance law. The results showcase the real-world feasibility and superior performance of nonlinear MPC for 3D path-following guidance at ground speeds up to 36 meters per second.
A Stochastic Approach to Terrain Maps for Safe Lunar Landing
Dec 12, 2025



Safely landing on the lunar surface is a challenging task, especially in the heavily-shadowed South Pole region where traditional vision-based hazard detection methods are not reliable. The potential existence of valuable resources at the lunar South Pole has made landing in that region a high priority for many space agencies and commercial companies. However, relying on a LiDAR for hazard detection during descent is risky, as this technology is fairly untested in the lunar environment. There exists a rich log of lunar surface data from the Lunar Reconnaissance Orbiter (LRO), which could be used to create informative prior maps of the surface before descent. In this work, we propose a method for generating stochastic elevation maps from LRO data using Gaussian processes (GPs), which are a powerful Bayesian framework for non-parametric modeling that produce accompanying uncertainty estimates. In high-risk environments such as autonomous spaceflight, interpretable estimates of terrain uncertainty are critical. However, no previous approaches to stochastic elevation mapping have taken LRO Digital Elevation Model (DEM) confidence maps into account, despite this data containing key information about the quality of the DEM in different areas. To address this gap, we introduce a two-stage GP model in which a secondary GP learns spatially varying noise characteristics from DEM confidence data. This heteroscedastic information is then used to inform the noise parameters for the primary GP, which models the lunar terrain. Additionally, we use stochastic variational GPs to enable scalable training. By leveraging GPs, we are able to more accurately model the impact of heteroscedastic sensor noise on the resulting elevation map. As a result, our method produces more informative terrain uncertainty, which can be used for downstream tasks such as hazard detection and safe landing site selection.
Tree-Transformer: A Transformer-Based Method for Correction of Tree-Structured Data
Aug 01, 2019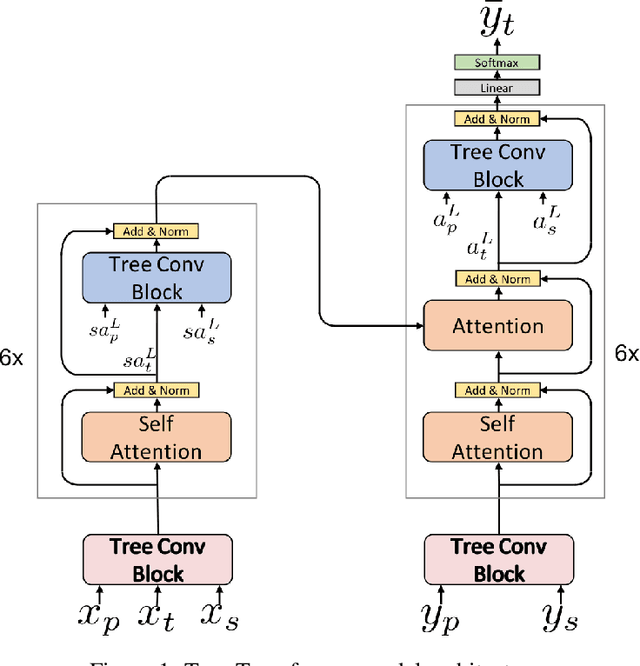
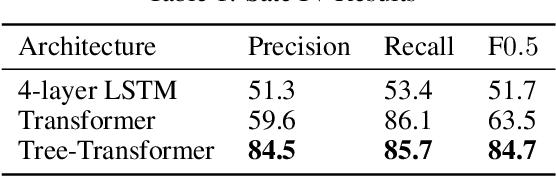
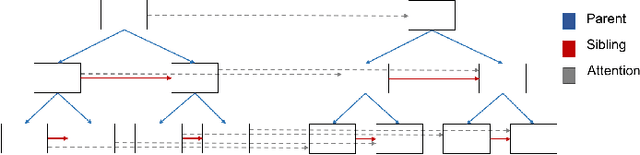
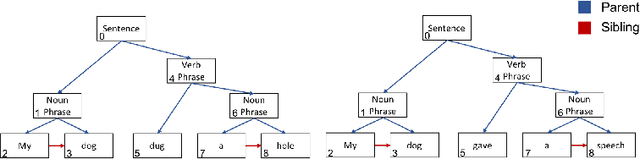
Many common sequential data sources, such as source code and natural language, have a natural tree-structured representation. These trees can be generated by fitting a sequence to a grammar, yielding a hierarchical ordering of the tokens in the sequence. This structure encodes a high degree of syntactic information, making it ideal for problems such as grammar correction. However, little work has been done to develop neural networks that can operate on and exploit tree-structured data. In this paper we present the Tree-Transformer \textemdash{} a novel neural network architecture designed to translate between arbitrary input and output trees. We applied this architecture to correction tasks in both the source code and natural language domains. On source code, our model achieved an improvement of $25\%$ $\text{F}0.5$ over the best sequential method. On natural language, we achieved comparable results to the most complex state of the art systems, obtaining a $10\%$ improvement in recall on the CoNLL 2014 benchmark and the highest to date $\text{F}0.5$ score on the AESW benchmark of $50.43$.