 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing voices at the National Library -- a speech corpus and acoustic model for the Swedish language
May 19, 2022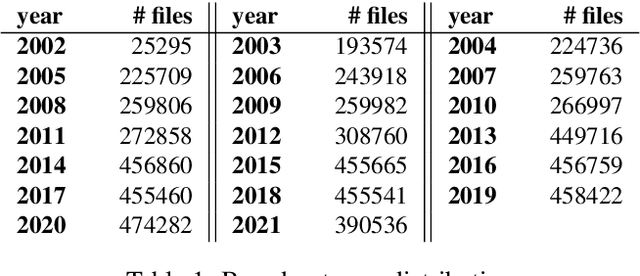
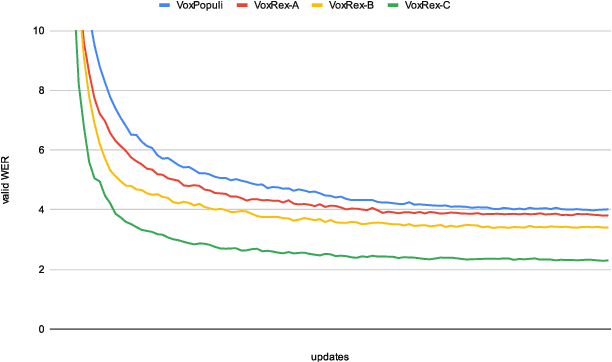
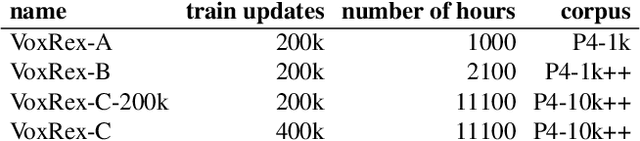
This paper explains our work in developing new acoustic models for automated speech recognition (ASR) at KBLab, the infrastructure for data-driven research at the National Library of Sweden (KB). We evaluate different approaches for a viable speech-to-text pipeline for audiovisual resources in Swedish, using the wav2vec 2.0 architecture in combination with speech corpuses created from KB's collections. These approaches include pretraining an acoustic model for Swedish from the ground up, and fine-tuning existing monolingual and multilingual models. The collections-based corpuses we use have been sampled from millions of hours of speech, with a conscious attempt to balance regional dialects to produce a more representative, and thus more democratic, model. The acoustic model this enabled, "VoxRex", outperforms existing models for Swedish ASR. We also evaluate combining this model with various pretrained language models, which further enhanced performance. We conclude by highlighting the potential of such technology for cultural heritage institutions with vast collections of previously unlabelled audiovisual data. Our models are released for further exploration and research here: https://huggingface.co/KBLab.
Playing with Words at the National Library of Sweden -- Making a Swedish BERT
Jul 03, 2020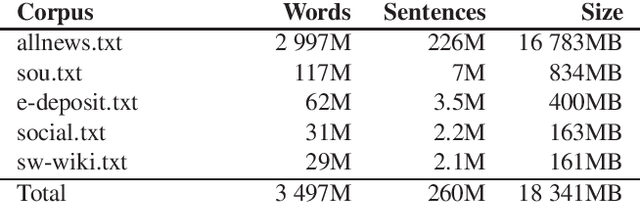
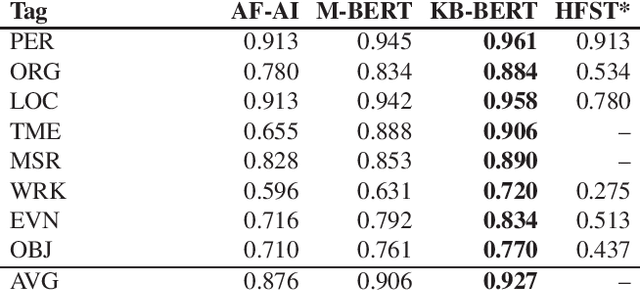
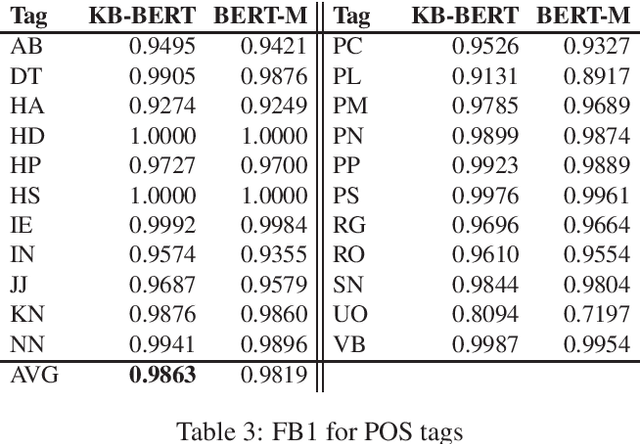
This paper introduces the Swedish BERT ("KB-BERT") developed by the KBLab for data-driven research at the National Library of Sweden (KB). Building on recent efforts to create transformer-based BERT models for languages other than English, we explain how we used KB's collections to create and train a new language-specific BERT model for Swedish. We also present the results of our model in comparison with existing models - chiefly that produced by the Swedish Public Employment Service, Arbetsf\"ormedlingen, and Google's multilingual M-BERT - where we demonstrate that KB-BERT outperforms these in a range of NLP tasks from named entity recognition (NER) to part-of-speech tagging (POS). Our discussion highlights the difficulties that continue to exist given the lack of training data and testbeds for smaller languages like Swedish. We release our model for further exploration and research here: https://github.com/Kungbib/swedish-bert-models .