 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstruction and Evaluation of a Self-Attention Model for Semantic Understanding of Sentence-Final Particles
Oct 01, 2022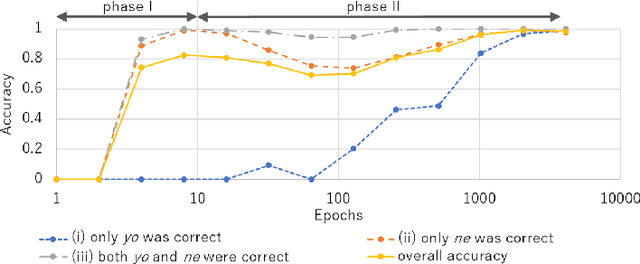
Sentence-final particles serve an essential role in spoken Japanese because they express the speaker's mental attitudes toward a proposition and/or an interlocutor. They are acquired at early ages and occur very frequently in everyday conversation. However, there has been little proposal for a computational model of acquiring sentence-final particles. This paper proposes Subjective BERT, a self-attention model that takes various subjective senses in addition to language and images as input and learns the relationship between words and subjective senses. An evaluation experiment revealed that the model understands the usage of "yo", which expresses the speaker's intention to communicate new information, and that of "ne", which denotes the speaker's desire to confirm that some information is shared.
Stepwise Acquisition of Dialogue Act Through Human-Robot Interaction
Oct 23, 2018
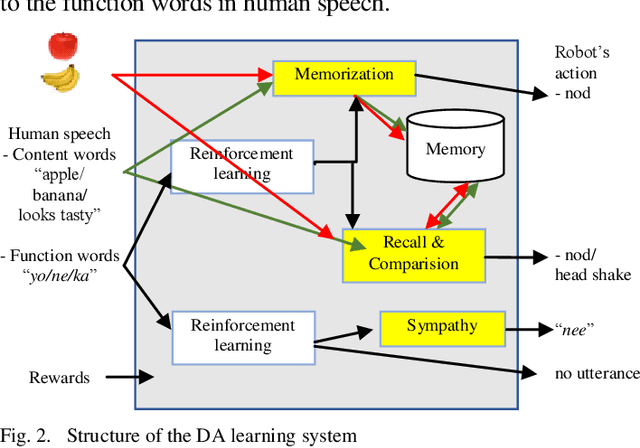
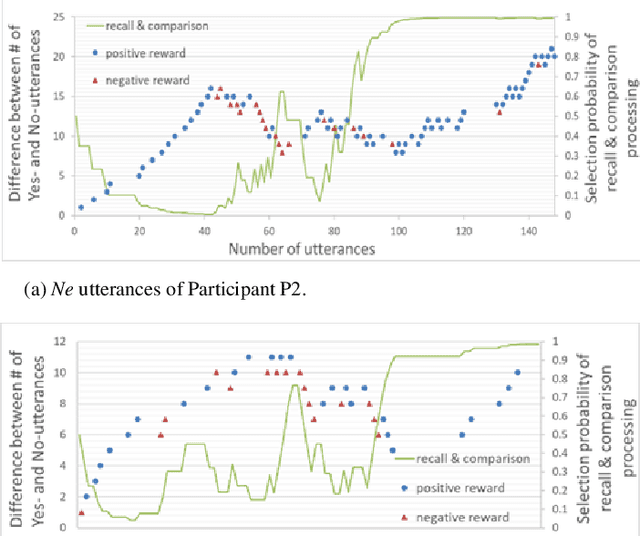

A dialogue act (DA) represents the meaning of an utterance at the illocutionary force level (Austin 1962) such as questions, requests, and greetings. Since DAs take charge of the most fundamental part of communication, we believe that the elucidation of DA learning mechanism is important for cognitive science and artificial intelligence. The purpose of this study is to verify that scaffolding takes place when a human teaches a robot, and to let a robot learn to estimate DAs and to make a response based on them step by step utilizing scaffolding provided by a human. To realize that, it is necessary for the robot to detect changes in utterance and rewards given by the partner and continue learning accordingly. Experimental results demonstrated that participants who continued interaction for a sufficiently long time often gave scaffolding for the robot. Although the number of experiments is still insufficient to obtain a definite conclusion, we observed that 1) the robot quickly learned to respond to DAs in most cases if the participants only spoke utterances that match the situation, 2) in the case of participants who builds scaffolding differently from what we assumed, learning did not proceed quickly, and 3) the robot could learn to estimate DAs almost exactly if the participants kept interaction for a sufficiently long time even if the scaffolding was unexpected.