 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-ISR: A Contrastive Learning and Implicit Stance Reasoning Framework for Misleading Text Detection on Social Media
Jun 05, 2025Misleading text detection on social media platforms is a critical research area, as these texts can lead to public misunderstanding, social panic and even economic losses. This paper proposes a novel framework - CL-ISR (Contrastive Learning and Implicit Stance Reasoning), which combines contrastive learning and implicit stance reasoning, to improve the detection accuracy of misleading texts on social media. First, we use the contrastive learning algorithm to improve the model's learning ability of semantic differences between truthful and misleading texts. Contrastive learning could help the model to better capture the distinguishing features between different categories by constructing positive and negative sample pairs. This approach enables the model to capture distinguishing features more effectively, particularly in linguistically complicated situations. Second, we introduce the implicit stance reasoning module, to explore the potential stance tendencies in the text and their relationships with related topics. This method is effective for identifying content that misleads through stance shifting or emotional manipulation, because it can capture the implicit information behind the text. Finally, we integrate these two algorithms together to form a new framework, CL-ISR, which leverages the discriminative power of contrastive learning and the interpretive depth of stance reasoning to significantly improve detection effect.
Identifying Exoplanets with Machine Learning Methods: A Preliminary Study
Apr 01, 2022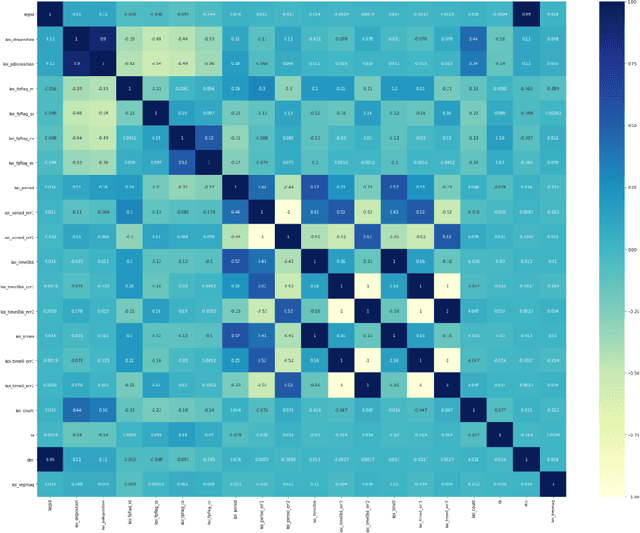

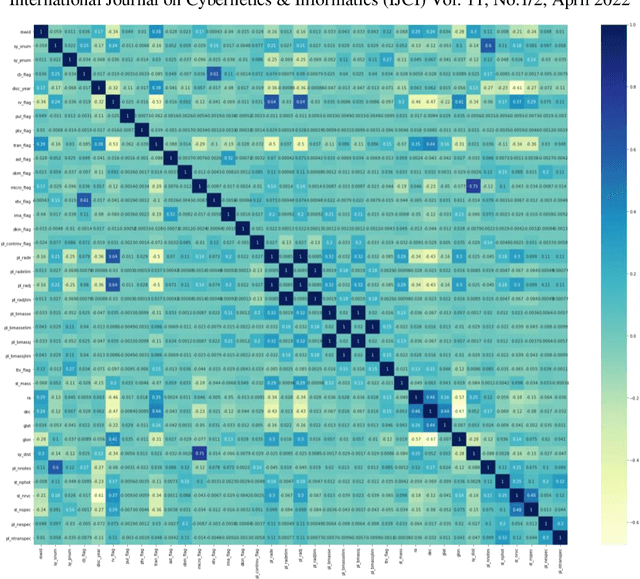
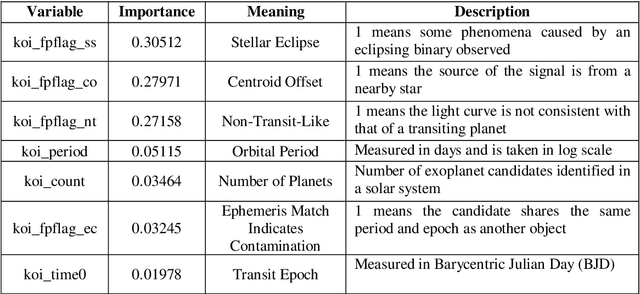
The discovery of habitable exoplanets has long been a heated topic in astronomy. Traditional methods for exoplanet identification include the wobble method, direct imaging, gravitational microlensing, etc., which not only require a considerable investment of manpower, time, and money, but also are limited by the performance of astronomical telescopes. In this study, we proposed the idea of using machine learning methods to identify exoplanets. We used the Kepler dataset collected by NASA from the Kepler Space Observatory to conduct supervised learning, which predicts the existence of exoplanet candidates as a three-categorical classification task, using decision tree, random forest, na\"ive Bayes, and neural network; we used another NASA dataset consisted of the confirmed exoplanets data to conduct unsupervised learning, which divides the confirmed exoplanets into different clusters, using k-means clustering. As a result, our models achieved accuracies of 99.06%, 92.11%, 88.50%, and 99.79%, respectively, in the supervised learning task and successfully obtained reasonable clusters in the unsupervised learning task.
* 12 pages with 9 figures and 2 tables