 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViCocktail: Automated Multi-Modal Data Collection for Vietnamese Audio-Visual Speech Recognition
Jun 05, 2025Audio-Visual Speech Recognition (AVSR) has gained significant attention recently due to its robustness against noise, which often challenges conventional speech recognition systems that rely solely on audio features. Despite this advantage, AVSR models remain limited by the scarcity of extensive datasets, especially for most languages beyond English. Automated data collection offers a promising solution. This work presents a practical approach to generate AVSR datasets from raw video, refining existing techniques for improved efficiency and accessibility. We demonstrate its broad applicability by developing a baseline AVSR model for Vietnamese. Experiments show the automatically collected dataset enables a strong baseline, achieving competitive performance with robust ASR in clean conditions and significantly outperforming them in noisy environments like cocktail parties. This efficient method provides a pathway to expand AVSR to more languages, particularly under-resourced ones.
Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models
Oct 01, 2020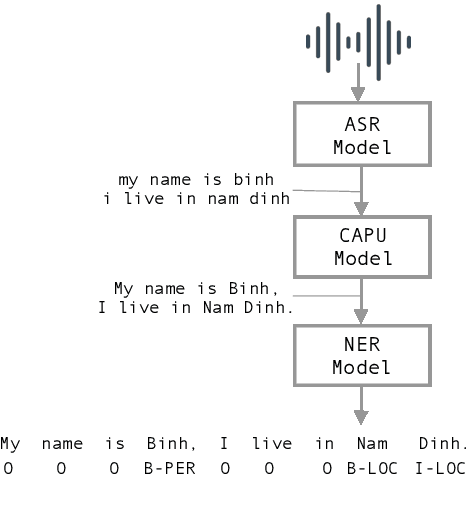

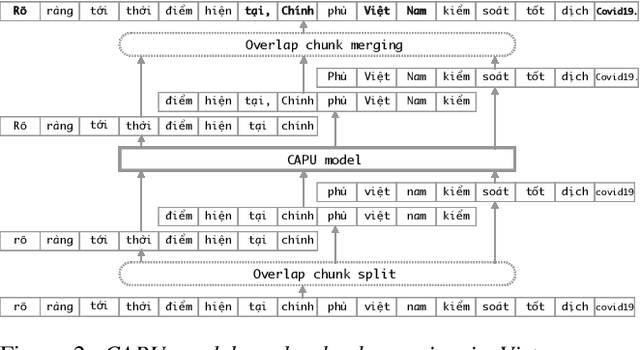
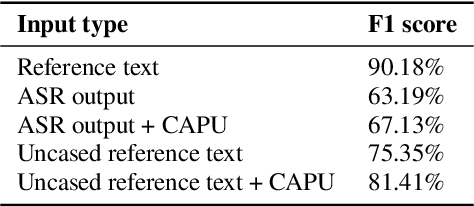
Studies on the Named Entity Recognition (NER) task have shown outstanding results that reach human parity on input texts with correct text formattings, such as with proper punctuation and capitalization. However, such conditions are not available in applications where the input is speech, because the text is generated from a speech recognition system (ASR), and that the system does not consider the text formatting. In this paper, we (1) presented the first Vietnamese speech dataset for NER task, and (2) the first pre-trained public large-scale monolingual language model for Vietnamese that achieved the new state-of-the-art for the Vietnamese NER task by 1.3% absolute F1 score comparing to the latest study. And finally, (3) we proposed a new pipeline for NER task from speech that overcomes the text formatting problem by introducing a text capitalization and punctuation recovery model (CaPu) into the pipeline. The model takes input text from an ASR system and performs two tasks at the same time, producing proper text formatting that helps to improve NER performance. Experimental results indicated that the CaPu model helps to improve by nearly 4% of F1-score.