 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSDA: Federated Stain Distribution Alignment for Non-IID Histopathological Image Classification
Nov 15, 2025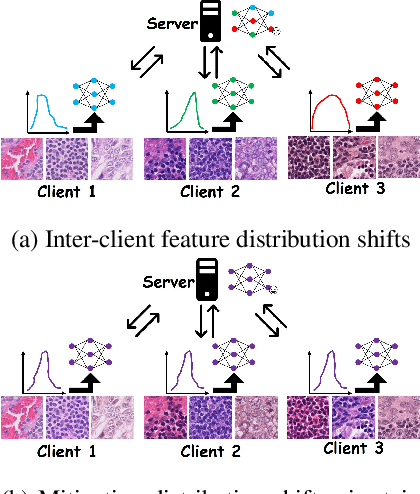

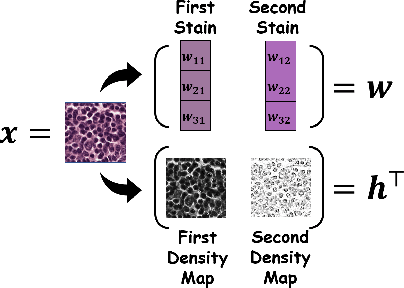
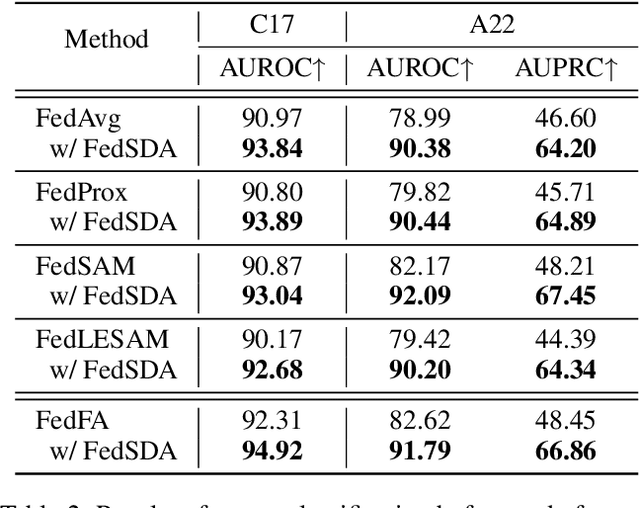
Federated learning (FL) has shown success in collaboratively training a model among decentralized data resources without directly sharing privacy-sensitive training data. Despite recent advances, non-IID (non-independent and identically distributed) data poses an inevitable challenge that hinders the use of FL. In this work, we address the issue of non-IID histopathological images with feature distribution shifts from an intuitive perspective that has only received limited attention. Specifically, we address this issue from the perspective of data distribution by solely adjusting the data distributions of all clients. Building on the success of diffusion models in fitting data distributions and leveraging stain separation to extract the pivotal features that are closely related to the non-IID properties of histopathological images, we propose a Federated Stain Distribution Alignment (FedSDA) method. FedSDA aligns the stain distribution of each client with a target distribution in an FL framework to mitigate distribution shifts among clients. Furthermore, considering that training diffusion models on raw data in FL has been shown to be susceptible to privacy leakage risks, we circumvent this problem while still effectively achieving alignment. Extensive experimental results show that FedSDA is not only effective in improving baselines that focus on mitigating disparities across clients' model updates but also outperforms baselines that address the non-IID data issues from the perspective of data distribution. We show that FedSDA provides valuable and practical insights for the computational pathology community.
Adversarial Robustness Overestimation and Instability in TRADES
Oct 10, 2024



This paper examines the phenomenon of probabilistic robustness overestimation in TRADES, a prominent adversarial training method. Our study reveals that TRADES sometimes yields disproportionately high PGD validation accuracy compared to the AutoAttack testing accuracy in the multiclass classification task. This discrepancy highlights a significant overestimation of robustness for these instances, potentially linked to gradient masking. We further analyze the parameters contributing to unstable models that lead to overestimation. Our findings indicate that smaller batch sizes, lower beta values (which control the weight of the robust loss term in TRADES), larger learning rates, and higher class complexity (e.g., CIFAR-100 versus CIFAR-10) are associated with an increased likelihood of robustness overestimation. By examining metrics such as the First-Order Stationary Condition (FOSC), inner-maximization, and gradient information, we identify the underlying cause of this phenomenon as gradient masking and provide insights into it. Furthermore, our experiments show that certain unstable training instances may return to a state without robust overestimation, inspiring our attempts at a solution. In addition to adjusting parameter settings to reduce instability or retraining when overestimation occurs, we recommend incorporating Gaussian noise in inputs when the FOSC score exceed the threshold. This method aims to mitigate robustness overestimation of TRADES and other similar methods at its source, ensuring more reliable representation of adversarial robustness during evaluation.
Exploring Robustness of Visual State Space model against Backdoor Attacks
Aug 22, 2024



Visual State Space Model (VSS) has demonstrated remarkable performance in various computer vision tasks. However, in the process of development, backdoor attacks have brought severe challenges to security. Such attacks cause an infected model to predict target labels when a specific trigger is activated, while the model behaves normally on benign samples. In this paper, we conduct systematic experiments to comprehend on robustness of VSS through the lens of backdoor attacks, specifically how the state space model (SSM) mechanism affects robustness. We first investigate the vulnerability of VSS to different backdoor triggers and reveal that the SSM mechanism, which captures contextual information within patches, makes the VSS model more susceptible to backdoor triggers compared to models without SSM. Furthermore, we analyze the sensitivity of the VSS model to patch processing techniques and discover that these triggers are effectively disrupted. Based on these observations, we consider an effective backdoor for the VSS model that recurs in each patch to resist patch perturbations. Extensive experiments across three datasets and various backdoor attacks reveal that the VSS model performs comparably to Transformers (ViTs) but is less robust than the Gated CNNs, which comprise only stacked Gated CNN blocks without SSM.