 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Stochastic Optimization in Separable Learning Environments
Aug 21, 2021
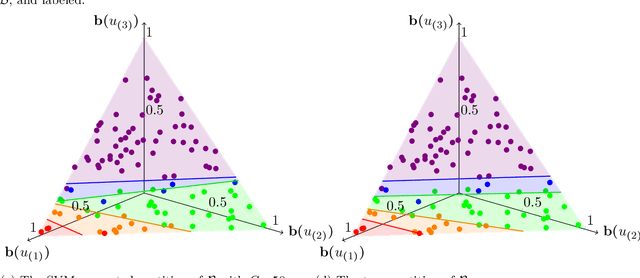

We consider a class of sequential decision-making problems under uncertainty that can encompass various types of supervised learning concepts. These problems have a completely observed state process and a partially observed modulation process, where the state process is affected by the modulation process only through an observation process, the observation process only observes the modulation process, and the modulation process is exogenous to control. We model this broad class of problems as a partially observed Markov decision process (POMDP). The belief function for the modulation process is control invariant, thus separating the estimation of the modulation process from the control of the state process. We call this specially structured POMDP the separable POMDP, or SEP-POMDP, and show it (i) can serve as a model for a broad class of application areas, e.g., inventory control, finance, healthcare systems, (ii) inherits value function and optimal policy structure from a set of completely observed MDPs, (iii) can serve as a bridge between classical models of sequential decision making under uncertainty having fully specified model artifacts and such models that are not fully specified and require the use of predictive methods from statistics and machine learning, and (iv) allows for specialized approximate solution procedures.
Partially Observed, Multi-objective Markov Games
Apr 16, 2014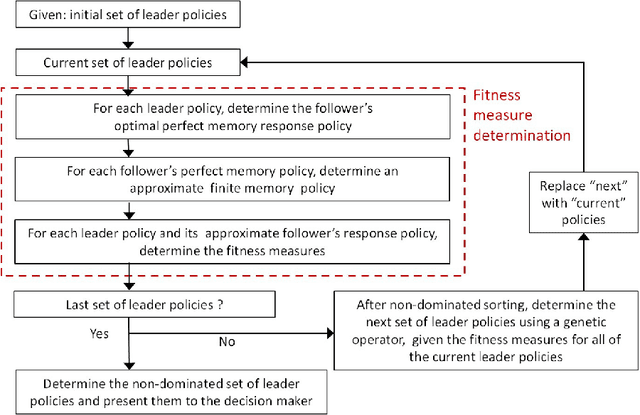
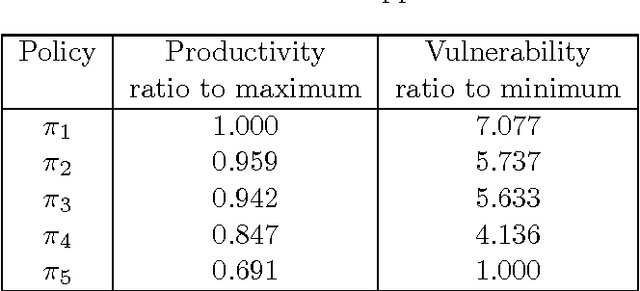
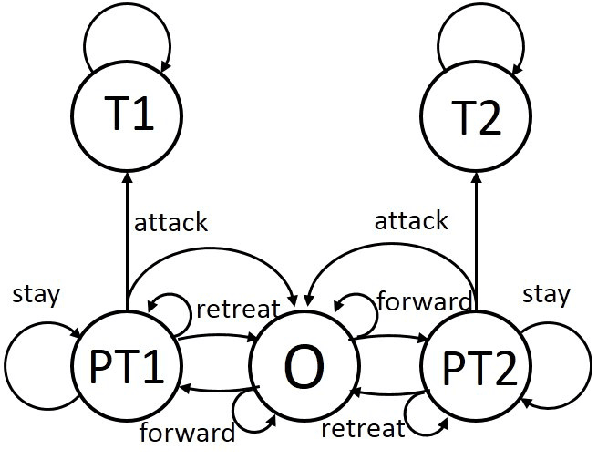
The intent of this research is to generate a set of non-dominated policies from which one of two agents (the leader) can select a most preferred policy to control a dynamic system that is also affected by the control decisions of the other agent (the follower). The problem is described by an infinite horizon, partially observed Markov game (POMG). At each decision epoch, each agent knows: its past and present states, its past actions, and noise corrupted observations of the other agent's past and present states. The actions of each agent are determined at each decision epoch based on these data. The leader considers multiple objectives in selecting its policy. The follower considers a single objective in selecting its policy with complete knowledge of and in response to the policy selected by the leader. This leader-follower assumption allows the POMG to be transformed into a specially structured, partially observed Markov decision process (POMDP). This POMDP is used to determine the follower's best response policy. A multi-objective genetic algorithm (MOGA) is used to create the next generation of leader policies based on the fitness measures of each leader policy in the current generation. Computing a fitness measure for a leader policy requires a value determination calculation, given the leader policy and the follower's best response policy. The policies from which the leader can select a most preferred policy are the non-dominated policies of the final generation of leader policies created by the MOGA. An example is presented that illustrates how these results can be used to support a manager of a liquid egg production process (the leader) in selecting a sequence of actions to best control this process over time, given that there is an attacker (the follower) who seeks to contaminate the liquid egg production process with a chemical or biological toxin.