 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMIC: Towards A Compact Image Captioning Model with Attention
Mar 16, 2019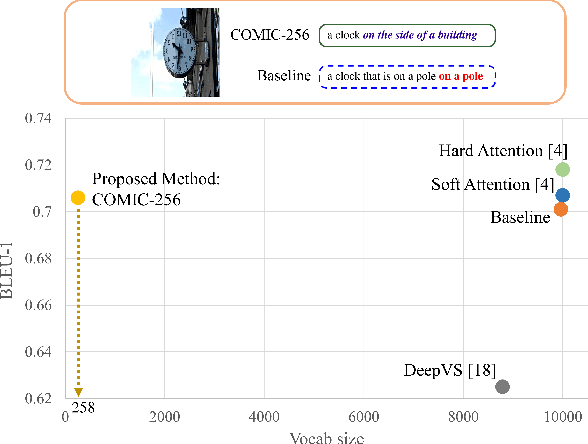


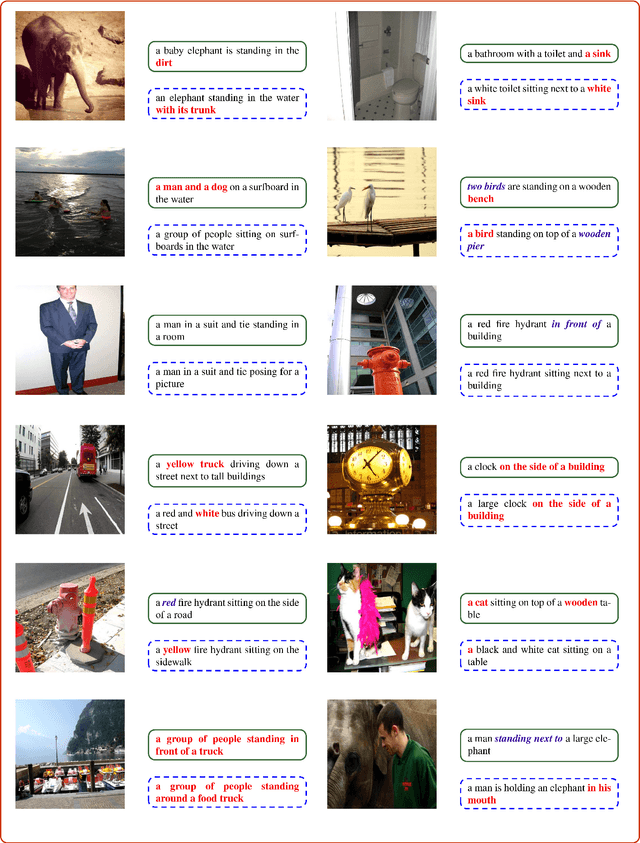
Recent works in image captioning have shown very promising raw performance. However, we realize that most of these encoder-decoder style networks with attention do not scale naturally to large vocabulary size, making them difficult to be deployed on embedded system with limited hardware resources. This is because the size of word and output embedding matrices grow proportionally with the size of vocabulary, adversely affecting the compactness of these networks. To address this limitation, this paper introduces a brand new idea in the domain of image captioning. That is, we tackle the problem of compactness of image captioning models which is hitherto unexplored. We showed that, our proposed model, named COMIC for COMpact Image Captioning, achieves comparable results in five common evaluation metrics with state-of-the-art approaches on both MS-COCO and InstaPIC-1.1M datasets despite having an embedding vocabulary size that is 39x - 99x smaller
A Universal Logic Operator for Interpretable Deep Convolution Networks
Jan 20, 2019
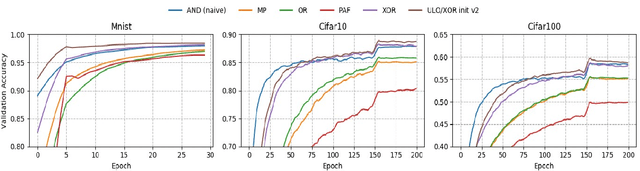
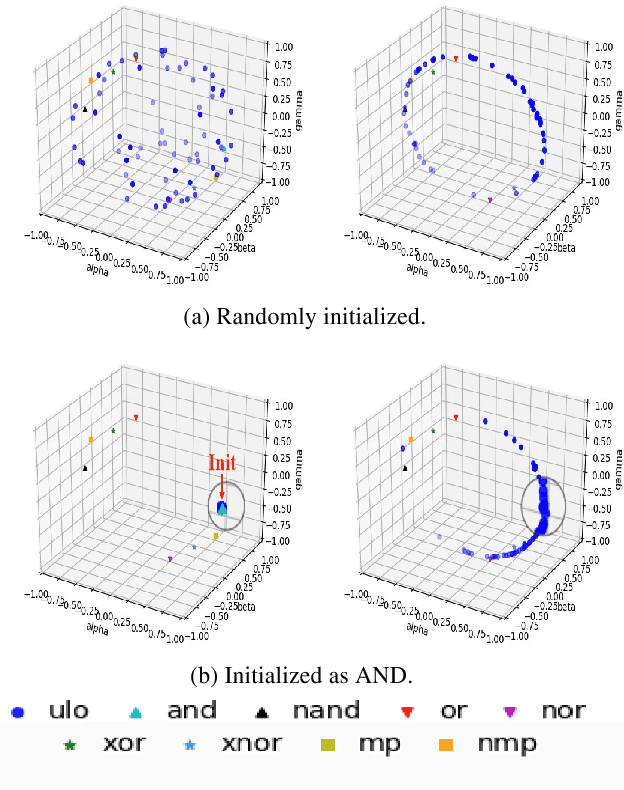
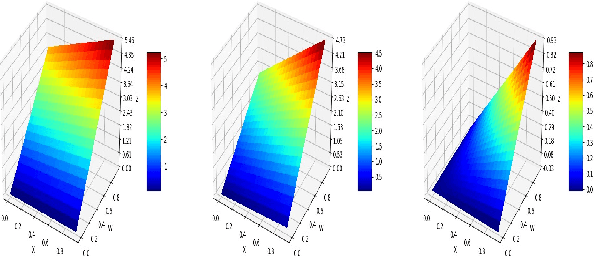
Explaining neural network computation in terms of probabilistic/fuzzy logical operations has attracted much attention due to its simplicity and high interpretability. Different choices of logical operators such as AND, OR and XOR give rise to another dimension for network optimization, and in this paper, we study the open problem of learning a universal logical operator without prescribing to any logical operations manually. Insightful observations along this exploration furnish deep convolution networks with a novel logical interpretation.
Improved ArtGAN for Conditional Synthesis of Natural Image and Artwork
Aug 23, 2018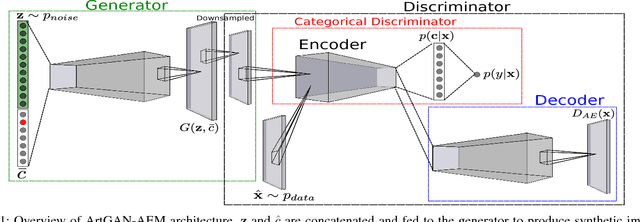


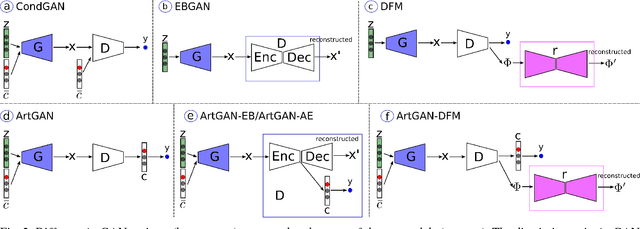
This paper proposes a series of new approaches to improve Generative Adversarial Network (GAN) for conditional image synthesis and we name the proposed model as ArtGAN. One of the key innovation of ArtGAN is that, the gradient of the loss function w.r.t. the label (randomly assigned to each generated image) is back-propagated from the categorical discriminator to the generator. With the feedback from the label information, the generator is able to learn more efficiently and generate image with better quality. Inspired by recent works, an autoencoder is incorporated into the categorical discriminator for additional complementary information. Last but not least, we introduce a novel strategy to improve the image quality. In the experiments, we evaluate ArtGAN on CIFAR-10 and STL-10 via ablation studies. The empirical results showed that our proposed model outperforms the state-of-the-art results on CIFAR-10 in terms of Inception score. Qualitatively, we demonstrate that ArtGAN is able to generate plausible-looking images on Oxford-102 and CUB-200, as well as able to draw realistic artworks based on style, artist, and genre. The source code and models are available at: https://github.com/cs-chan/ArtGAN
Getting to Know Low-light Images with The Exclusively Dark Dataset
May 29, 2018
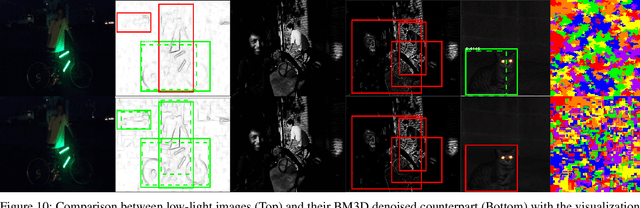
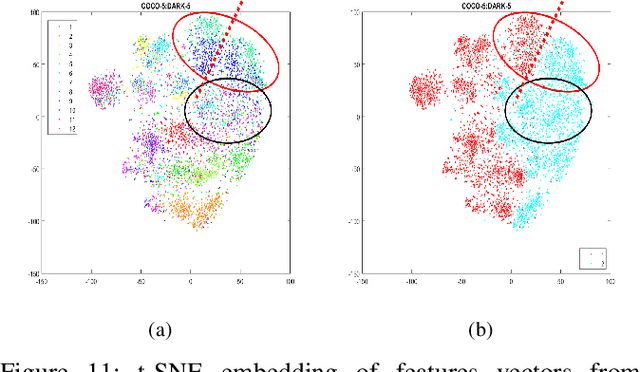
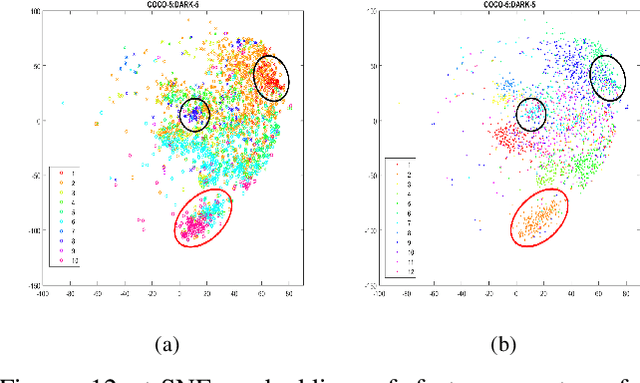
Low-light is an inescapable element of our daily surroundings that greatly affects the efficiency of our vision. Research works on low-light has seen a steady growth, particularly in the field of image enhancement, but there is still a lack of a go-to database as benchmark. Besides, research fields that may assist us in low-light environments, such as object detection, has glossed over this aspect even though breakthroughs-after-breakthroughs had been achieved in recent years, most noticeably from the lack of low-light data (less than 2% of the total images) in successful public benchmark dataset such as PASCAL VOC, ImageNet, and Microsoft COCO. Thus, we propose the Exclusively Dark dataset to elevate this data drought, consisting exclusively of ten different types of low-light images (i.e. low, ambient, object, single, weak, strong, screen, window, shadow and twilight) captured in visible light only with image and object level annotations. Moreover, we share insightful findings in regards to the effects of low-light on the object detection task by analyzing visualizations of both hand-crafted and learned features. Most importantly, we found that the effects of low-light reaches far deeper into the features than can be solved by simple "illumination invariance'". It is our hope that this analysis and the Exclusively Dark dataset can encourage the growth in low-light domain researches on different fields. The Exclusively Dark dataset with its annotation is available at https://github.com/cs-chan/Exclusively-Dark-Image-Dataset
Phrase-based Image Captioning with Hierarchical LSTM Model
Nov 11, 2017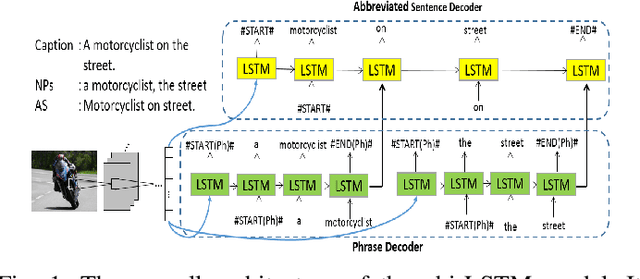



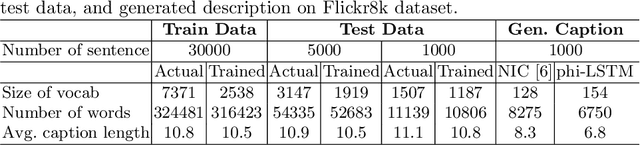
Automatic generation of caption to describe the content of an image has been gaining a lot of research interests recently, where most of the existing works treat the image caption as pure sequential data. Natural language, however possess a temporal hierarchy structure, with complex dependencies between each subsequence. In this paper, we propose a phrase-based hierarchical Long Short-Term Memory (phi-LSTM) model to generate image description. In contrast to the conventional solutions that generate caption in a pure sequential manner, our proposed model decodes image caption from phrase to sentence. It consists of a phrase decoder at the bottom hierarchy to decode noun phrases of variable length, and an abbreviated sentence decoder at the upper hierarchy to decode an abbreviated form of the image description. A complete image caption is formed by combining the generated phrases with sentence during the inference stage. Empirically, our proposed model shows a better or competitive result on the Flickr8k, Flickr30k and MS-COCO datasets in comparison to the state-of-the art models. We also show that our proposed model is able to generate more novel captions (not seen in the training data) which are richer in word contents in all these three datasets.
Total-Text: A Comprehensive Dataset for Scene Text Detection and Recognition
Oct 28, 2017



Text in curve orientation, despite being one of the common text orientations in real world environment, has close to zero existence in well received scene text datasets such as ICDAR2013 and MSRA-TD500. The main motivation of Total-Text is to fill this gap and facilitate a new research direction for the scene text community. On top of the conventional horizontal and multi-oriented texts, it features curved-oriented text. Total-Text is highly diversified in orientations, more than half of its images have a combination of more than two orientations. Recently, a new breed of solutions that casted text detection as a segmentation problem has demonstrated their effectiveness against multi-oriented text. In order to evaluate its robustness against curved text, we fine-tuned DeconvNet and benchmark it on Total-Text. Total-Text with its annotation is available at https://github.com/cs-chan/Total-Text-Dataset
phi-LSTM: A Phrase-based Hierarchical LSTM Model for Image Captioning
Oct 26, 2017
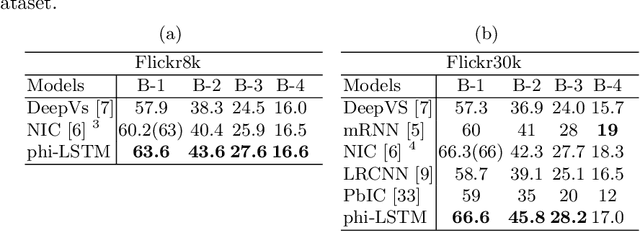
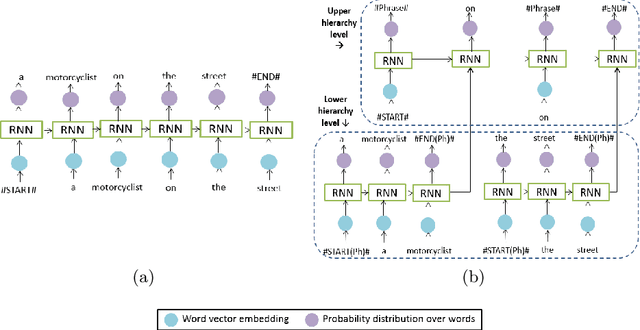
A picture is worth a thousand words. Not until recently, however, we noticed some success stories in understanding of visual scenes: a model that is able to detect/name objects, describe their attributes, and recognize their relationships/interactions. In this paper, we propose a phrase-based hierarchical Long Short-Term Memory (phi-LSTM) model to generate image description. The proposed model encodes sentence as a sequence of combination of phrases and words, instead of a sequence of words alone as in those conventional solutions. The two levels of this model are dedicated to i) learn to generate image relevant noun phrases, and ii) produce appropriate image description from the phrases and other words in the corpus. Adopting a convolutional neural network to learn image features and the LSTM to learn the word sequence in a sentence, the proposed model has shown better or competitive results in comparison to the state-of-the-art models on Flickr8k and Flickr30k datasets.
Crowd Behavior Analysis: A Review where Physics meets Biology
Nov 20, 2015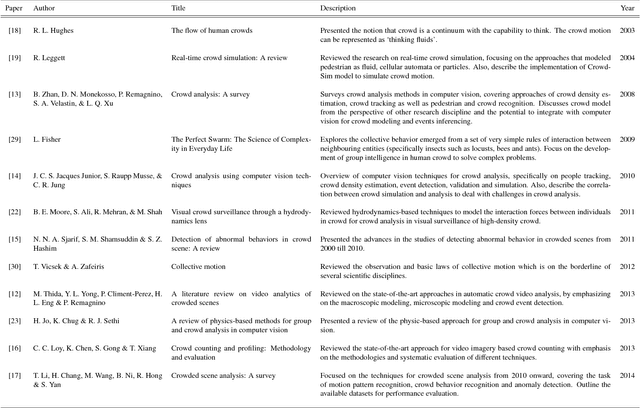
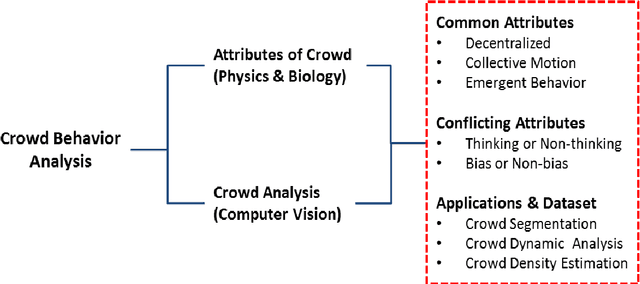
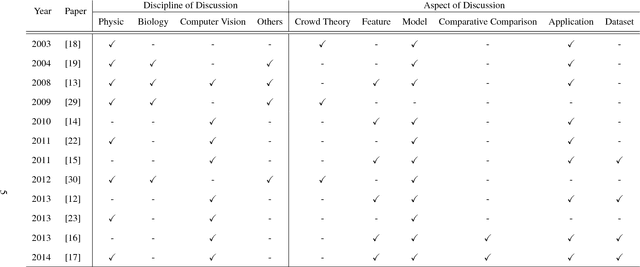

Although the traits emerged in a mass gathering are often non-deliberative, the act of mass impulse may lead to irre- vocable crowd disasters. The two-fold increase of carnage in crowd since the past two decades has spurred significant advances in the field of computer vision, towards effective and proactive crowd surveillance. Computer vision stud- ies related to crowd are observed to resonate with the understanding of the emergent behavior in physics (complex systems) and biology (animal swarm). These studies, which are inspired by biology and physics, share surprisingly common insights, and interesting contradictions. However, this aspect of discussion has not been fully explored. Therefore, this survey provides the readers with a review of the state-of-the-art methods in crowd behavior analysis from the physics and biologically inspired perspectives. We provide insights and comprehensive discussions for a broader understanding of the underlying prospect of blending physics and biology studies in computer vision.
* Accepted in Neurocomputing, 31 pages, 180 references
Deep-Plant: Plant Identification with convolutional neural networks
Jun 28, 2015
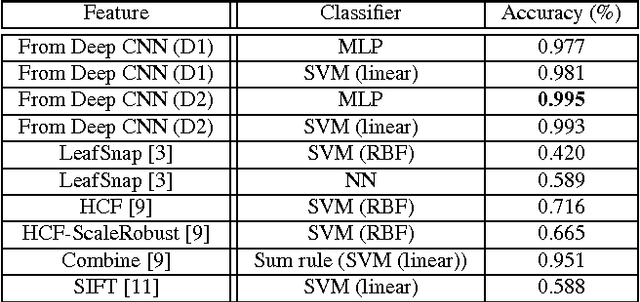

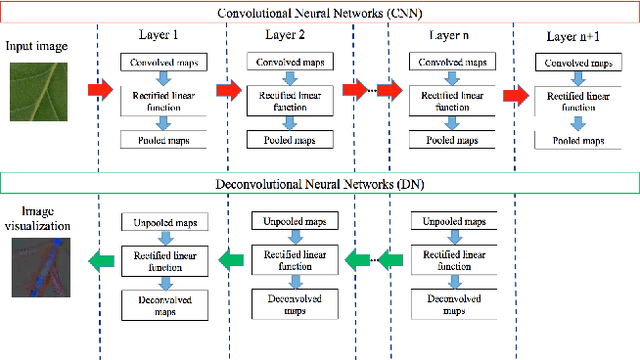
This paper studies convolutional neural networks (CNN) to learn unsupervised feature representations for 44 different plant species, collected at the Royal Botanic Gardens, Kew, England. To gain intuition on the chosen features from the CNN model (opposed to a 'black box' solution), a visualisation technique based on the deconvolutional networks (DN) is utilized. It is found that venations of different order have been chosen to uniquely represent each of the plant species. Experimental results using these CNN features with different classifiers show consistency and superiority compared to the state-of-the art solutions which rely on hand-crafted features.
Fuzzy human motion analysis: A review
Dec 02, 2014

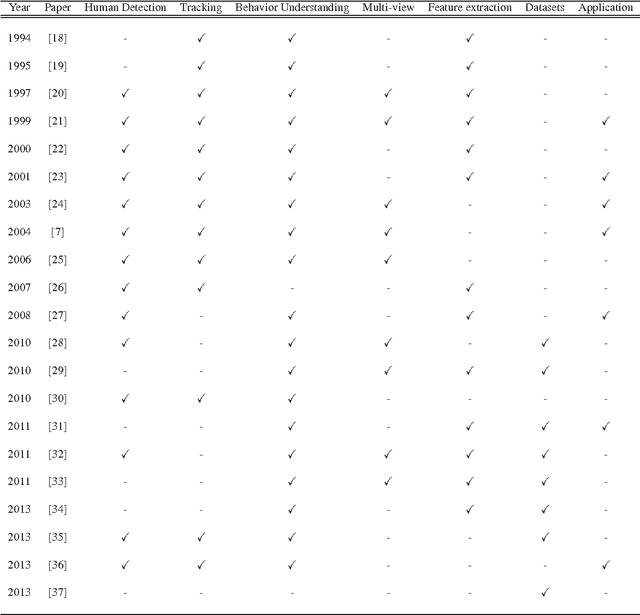
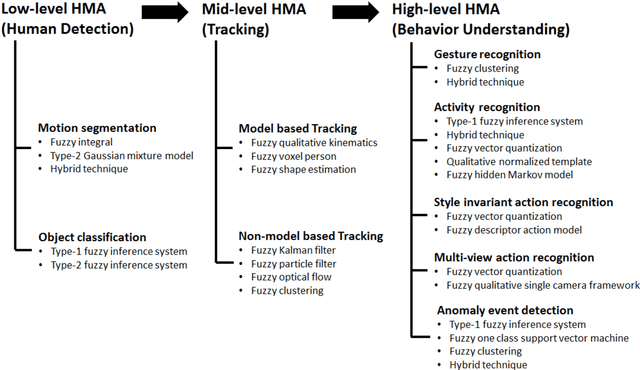
Human Motion Analysis (HMA) is currently one of the most popularly active research domains as such significant research interests are motivated by a number of real world applications such as video surveillance, sports analysis, healthcare monitoring and so on. However, most of these real world applications face high levels of uncertainties that can affect the operations of such applications. Hence, the fuzzy set theory has been applied and showed great success in the recent past. In this paper, we aim at reviewing the fuzzy set oriented approaches for HMA, individuating how the fuzzy set may improve the HMA, envisaging and delineating the future perspectives. To the best of our knowledge, there is not found a single survey in the current literature that has discussed and reviewed fuzzy approaches towards the HMA. For ease of understanding, we conceptually classify the human motion into three broad levels: Low-Level (LoL), Mid-Level (MiL), and High-Level (HiL) HMA.
* Accepted in Pattern Recognition, first survey paper that discusses and reviews fuzzy approaches towards HMA