 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Image segmentation using Fractional Gradients-Learning Model Parameters using Approximate Marginal Inference
May 07, 2016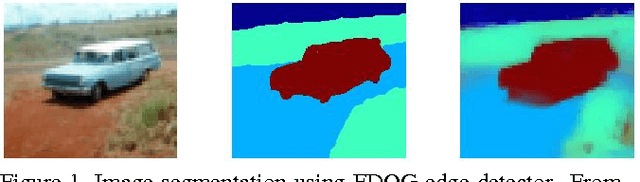
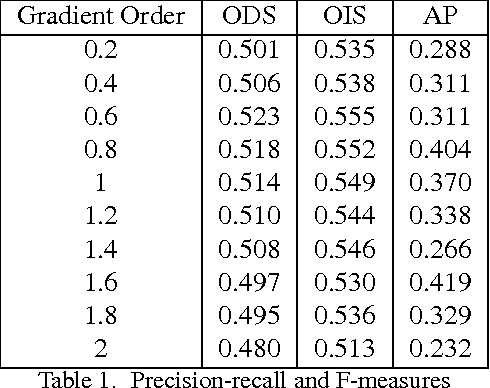

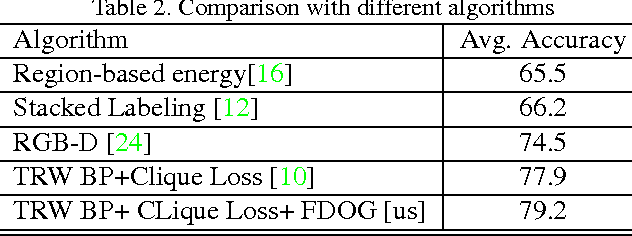
Estimates of image gradients play a ubiquitous role in image segmentation and classification problems since gradients directly relate to the boundaries or the edges of a scene. This paper proposes an unified approach to gradient estimation based on fractional calculus that is computationally cheap and readily applicable to any existing algorithm that relies on image gradients. We show experiments on edge detection and image segmentation on the Stanford Backgrounds Dataset where these improved local gradients outperforms state of the art, achieving a performance of 79.2% average accuracy.
Spatially Aware Dictionary Learning and Coding for Fossil Pollen Identification
May 03, 2016We propose a robust approach for performing automatic species-level recognition of fossil pollen grains in microscopy images that exploits both global shape and local texture characteristics in a patch-based matching methodology. We introduce a novel criteria for selecting meaningful and discriminative exemplar patches. We optimize this function during training using a greedy submodular function optimization framework that gives a near-optimal solution with bounded approximation error. We use these selected exemplars as a dictionary basis and propose a spatially-aware sparse coding method to match testing images for identification while maintaining global shape correspondence. To accelerate the coding process for fast matching, we introduce a relaxed form that uses spatially-aware soft-thresholding during coding. Finally, we carry out an experimental study that demonstrates the effectiveness and efficiency of our exemplar selection and classification mechanisms, achieving $86.13\%$ accuracy on a difficult fine-grained species classification task distinguishing three types of fossil spruce pollen.
The Open World of Micro-Videos
Apr 01, 2016
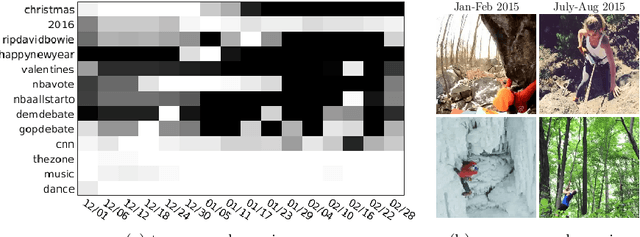
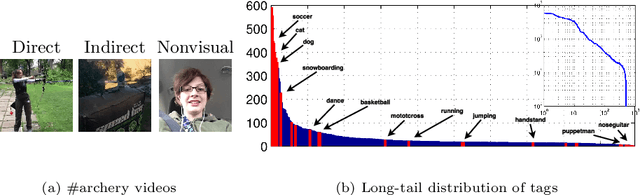
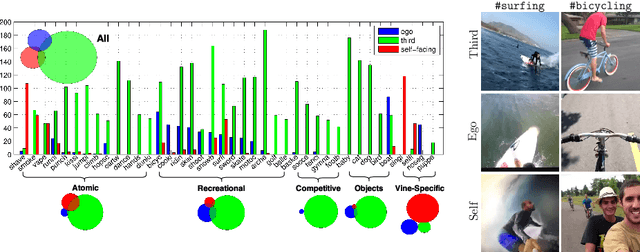
Micro-videos are six-second videos popular on social media networks with several unique properties. Firstly, because of the authoring process, they contain significantly more diversity and narrative structure than existing collections of video "snippets". Secondly, because they are often captured by hand-held mobile cameras, they contain specialized viewpoints including third-person, egocentric, and self-facing views seldom seen in traditional produced video. Thirdly, due to to their continuous production and publication on social networks, aggregate micro-video content contains interesting open-world dynamics that reflects the temporal evolution of tag topics. These aspects make micro-videos an appealing well of visual data for developing large-scale models for video understanding. We analyze a novel dataset of micro-videos labeled with 58 thousand tags. To analyze this data, we introduce viewpoint-specific and temporally-evolving models for video understanding, defined over state-of-the-art motion and deep visual features. We conclude that our dataset opens up new research opportunities for large-scale video analysis, novel viewpoints, and open-world dynamics.
Do We Need More Training Data?
Mar 05, 2015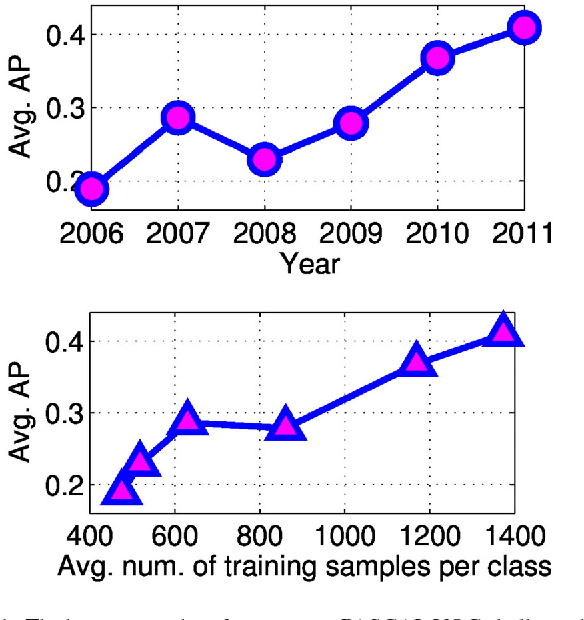
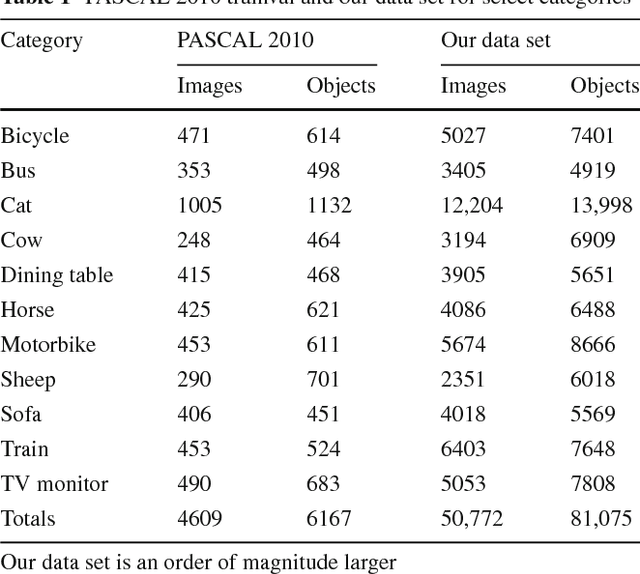
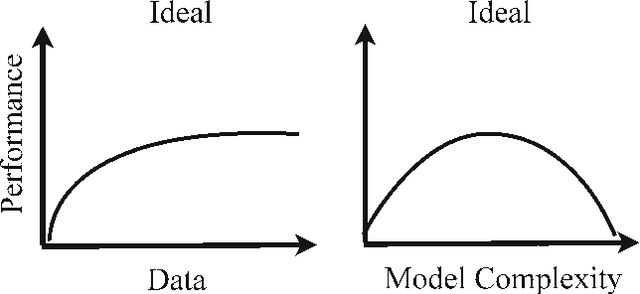
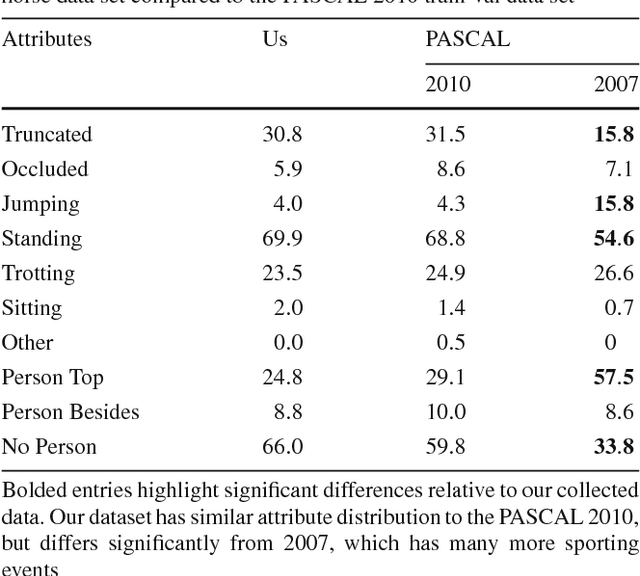
Datasets for training object recognition systems are steadily increasing in size. This paper investigates the question of whether existing detectors will continue to improve as data grows, or saturate in performance due to limited model complexity and the Bayes risk associated with the feature spaces in which they operate. We focus on the popular paradigm of discriminatively trained templates defined on oriented gradient features. We investigate the performance of mixtures of templates as the number of mixture components and the amount of training data grows. Surprisingly, even with proper treatment of regularization and "outliers", the performance of classic mixture models appears to saturate quickly ($\sim$10 templates and $\sim$100 positive training examples per template). This is not a limitation of the feature space as compositional mixtures that share template parameters via parts and that can synthesize new templates not encountered during training yield significantly better performance. Based on our analysis, we conjecture that the greatest gains in detection performance will continue to derive from improved representations and learning algorithms that can make efficient use of large datasets.