 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Physics-Informed Reinforcement Learning-Based Approach for Construction of Representative Drive Cycle
Jun 09, 2025Accurate driving cycle construction is crucial for vehicle design, fuel economy analysis, and environmental impact assessments. A generative Physics-Informed Expected SARSA-Monte Carlo (PIESMC) approach that constructs representative driving cycles by capturing transient dynamics, acceleration, deceleration, idling, and road grade transitions while ensuring model fidelity is introduced. Leveraging a physics-informed reinforcement learning framework with Monte Carlo sampling, PIESMC delivers efficient cycle construction with reduced computational cost. Experimental evaluations on two real-world datasets demonstrate that PIESMC replicates key kinematic and energy metrics, achieving up to a 57.3% reduction in cumulative kinematic fragment errors compared to the Micro-trip-based (MTB) method and a 10.5% reduction relative to the Markov-chain-based (MCB) method. Moreover, it is nearly an order of magnitude faster than conventional techniques. Analyses of vehicle-specific power distributions and wavelet-transformed frequency content further confirm its ability to reproduce experimental central tendencies and variability.
Hybrid Reinforcement Learning and Model Predictive Control for Adaptive Control of Hydrogen-Diesel Dual-Fuel Combustion
Apr 23, 2025Reinforcement Learning (RL) and Machine Learning Integrated Model Predictive Control (ML-MPC) are promising approaches for optimizing hydrogen-diesel dual-fuel engine control, as they can effectively control multiple-input multiple-output systems and nonlinear processes. ML-MPC is advantageous for providing safe and optimal controls, ensuring the engine operates within predefined safety limits. In contrast, RL is distinguished by its adaptability to changing conditions through its learning-based approach. However, the practical implementation of either method alone poses challenges. RL requires high variance in control inputs during early learning phases, which can pose risks to the system by potentially executing unsafe actions, leading to mechanical damage. Conversely, ML-MPC relies on an accurate system model to generate optimal control inputs and has limited adaptability to system drifts, such as injector aging, which naturally occur in engine applications. To address these limitations, this study proposes a hybrid RL and ML-MPC approach that uses an ML-MPC framework while incorporating an RL agent to dynamically adjust the ML-MPC load tracking reference in response to changes in the environment. At the same time, the ML-MPC ensures that actions stay safe throughout the RL agent's exploration. To evaluate the effectiveness of this approach, fuel pressure is deliberately varied to introduce a model-plant mismatch between the ML-MPC and the engine test bench. The result of this mismatch is a root mean square error (RMSE) in indicated mean effective pressure of 0.57 bar when running the ML-MPC. The experimental results demonstrate that RL successfully adapts to changing boundary conditions by altering the tracking reference while ML-MPC ensures safe control inputs. The quantitative improvement in load tracking by implementing RL is an RSME of 0.44 bar.
Transfer of Reinforcement Learning-Based Controllers from Model- to Hardware-in-the-Loop
Oct 25, 2023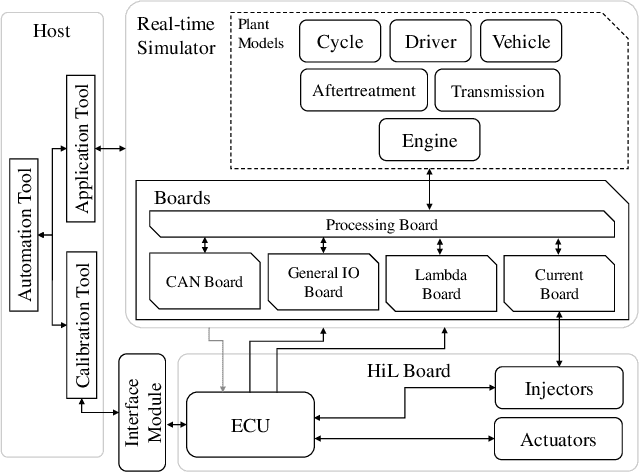
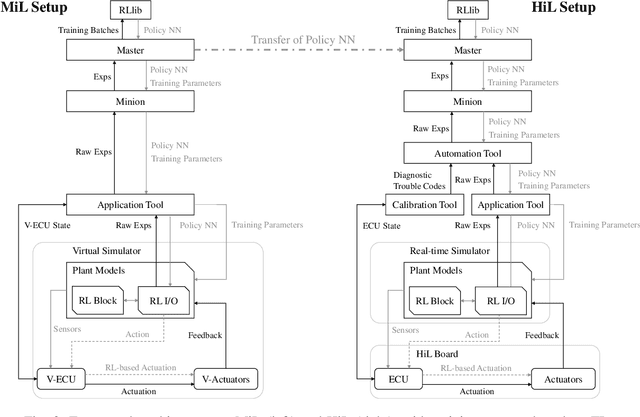
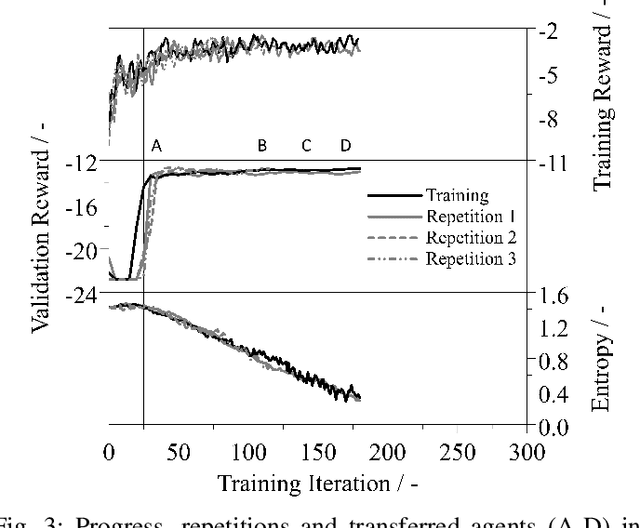
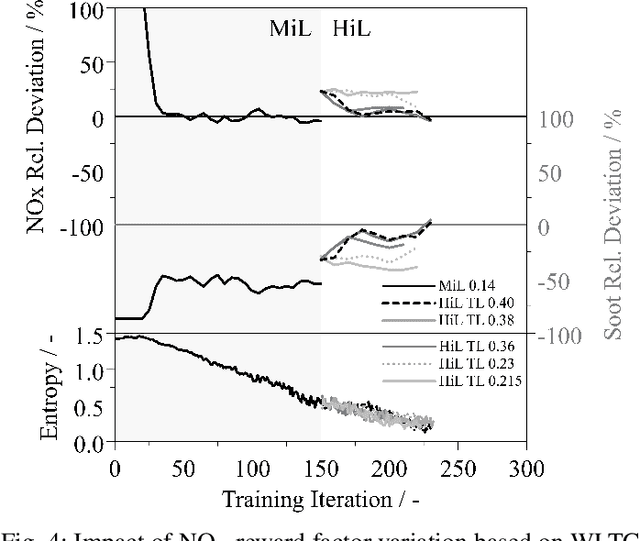
The process of developing control functions for embedded systems is resource-, time-, and data-intensive, often resulting in sub-optimal cost and solutions approaches. Reinforcement Learning (RL) has great potential for autonomously training agents to perform complex control tasks with minimal human intervention. Due to costly data generation and safety constraints, however, its application is mostly limited to purely simulated domains. To use RL effectively in embedded system function development, the generated agents must be able to handle real-world applications. In this context, this work focuses on accelerating the training process of RL agents by combining Transfer Learning (TL) and X-in-the-Loop (XiL) simulation. For the use case of transient exhaust gas re-circulation control for an internal combustion engine, use of a computationally cheap Model-in-the-Loop (MiL) simulation is made to select a suitable algorithm, fine-tune hyperparameters, and finally train candidate agents for the transfer. These pre-trained RL agents are then fine-tuned in a Hardware-in-the-Loop (HiL) system via TL. The transfer revealed the need for adjusting the reward parameters when advancing to real hardware. Further, the comparison between a purely HiL-trained and a transferred agent showed a reduction of training time by a factor of 5.9. The results emphasize the necessity to train RL agents with real hardware, and demonstrate that the maturity of the transferred policies affects both training time and performance, highlighting the strong synergies between TL and XiL simulation.