 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThresholding Classifiers to Maximize F1 Score
May 14, 2014
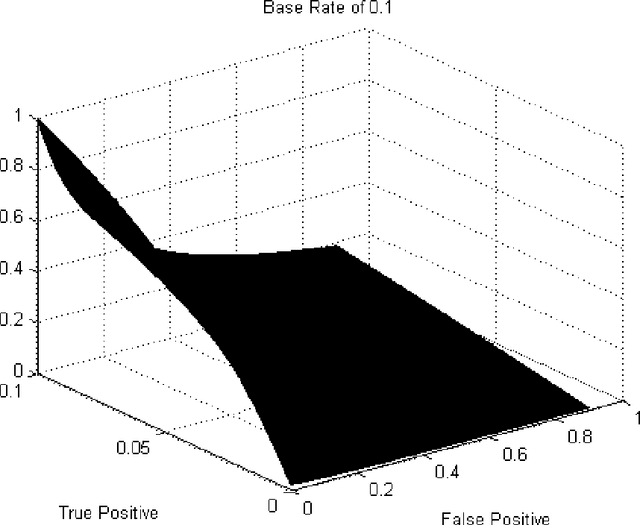
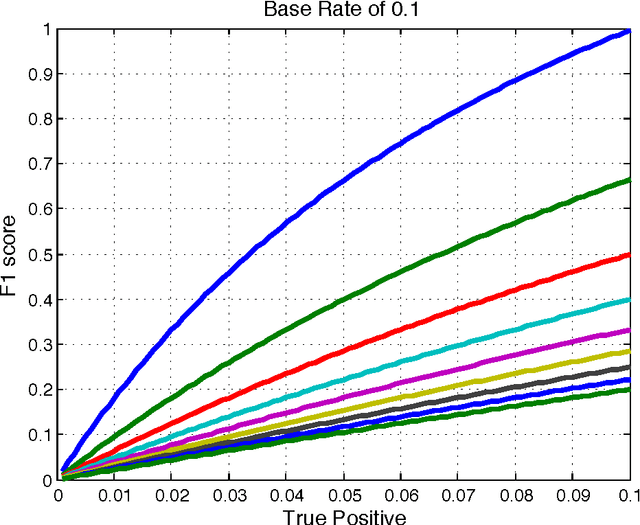
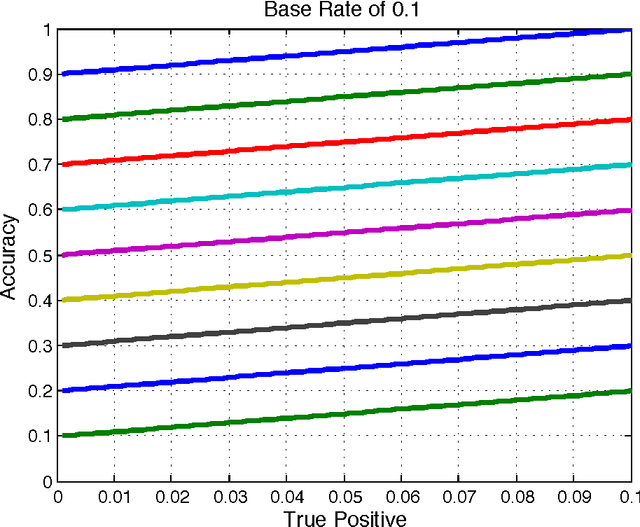
This paper provides new insight into maximizing F1 scores in the context of binary classification and also in the context of multilabel classification. The harmonic mean of precision and recall, F1 score is widely used to measure the success of a binary classifier when one class is rare. Micro average, macro average, and per instance average F1 scores are used in multilabel classification. For any classifier that produces a real-valued output, we derive the relationship between the best achievable F1 score and the decision-making threshold that achieves this optimum. As a special case, if the classifier outputs are well-calibrated conditional probabilities, then the optimal threshold is half the optimal F1 score. As another special case, if the classifier is completely uninformative, then the optimal behavior is to classify all examples as positive. Since the actual prevalence of positive examples typically is low, this behavior can be considered undesirable. As a case study, we discuss the results, which can be surprising, of applying this procedure when predicting 26,853 labels for Medline documents.
Predicting accurate probabilities with a ranking loss
Jun 18, 2012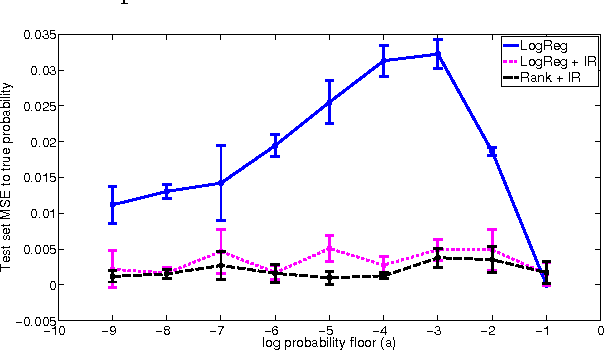
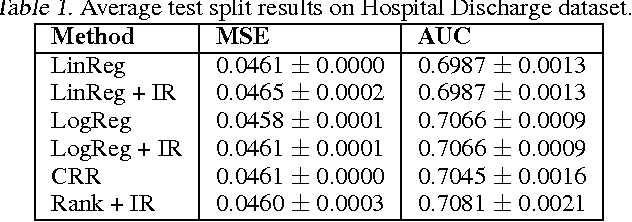
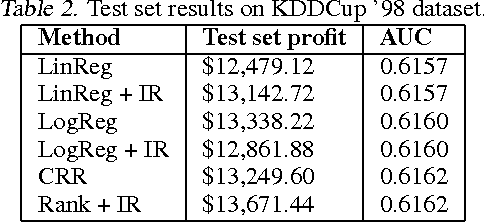
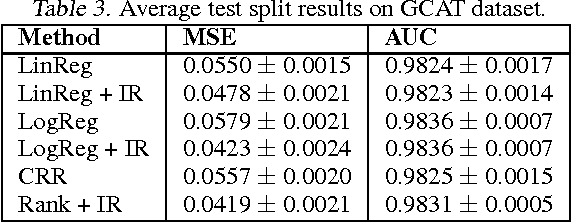
In many real-world applications of machine learning classifiers, it is essential to predict the probability of an example belonging to a particular class. This paper proposes a simple technique for predicting probabilities based on optimizing a ranking loss, followed by isotonic regression. This semi-parametric technique offers both good ranking and regression performance, and models a richer set of probability distributions than statistical workhorses such as logistic regression. We provide experimental results that show the effectiveness of this technique on real-world applications of probability prediction.
Dyadic Prediction Using a Latent Feature Log-Linear Model
Jun 10, 2010


In dyadic prediction, labels must be predicted for pairs (dyads) whose members possess unique identifiers and, sometimes, additional features called side-information. Special cases of this problem include collaborative filtering and link prediction. We present the first model for dyadic prediction that satisfies several important desiderata: (i) labels may be ordinal or nominal, (ii) side-information can be easily exploited if present, (iii) with or without side-information, latent features are inferred for dyad members, (iv) it is resistant to sample-selection bias, (v) it can learn well-calibrated probabilities, and (vi) it can scale to very large datasets. To our knowledge, no existing method satisfies all the above criteria. In particular, many methods assume that the labels are ordinal and ignore side-information when it is present. Experimental results show that the new method is competitive with state-of-the-art methods for the special cases of collaborative filtering and link prediction, and that it makes accurate predictions on nominal data.