 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Opponent Modeling with Graph Neural Networks, Deep Reinforcement Learning and Probabilistic Topic Modeling
Nov 14, 2025



This paper provides a comprehensive review of mainly Graph Neural Networks, Deep Reinforcement Learning, and Probabilistic Topic Modeling methods with a focus on their potential incorporation in strategic multiagent settings. We draw interest in (i) Machine Learning methods currently utilized for uncovering unknown model structures adaptable to the task of strategic opponent modeling, and (ii) the integration of these methods with Game Theoretic concepts that avoid relying on assumptions often invalid in real-world scenarios, such as the Common Prior Assumption (CPA) and the Self-Interest Hypothesis (SIH). We analyze the ability to handle uncertainty and heterogeneity, two characteristics that are very common in real-world application cases, as well as scalability. As a potential answer to effectively modeling relationships and interactions in multiagent settings, we champion the use of Graph Neural Networks (GNN). Such approaches are designed to operate upon graph-structured data, and have been shown to be a very powerful tool for performing tasks such as node classification and link prediction. Next, we review the domain of Reinforcement Learning (RL), and in particular that of Multiagent Deep Reinforcement Learning (MADRL). Following, we describe existing relevant game theoretic solution concepts and consider properties such as fairness and stability. Our review comes complete with a note on the literature that utilizes PTM in domains other than that of document analysis and classification. The capability of PTM to estimate unknown underlying distributions can help with tackling heterogeneity and unknown agent beliefs. Finally, we identify certain open challenges specifically, the need to (i) fit non-stationary environments, (ii) balance the degrees of stability and adaptation, (iii) tackle uncertainty and heterogeneity, (iv) guarantee scalability and solution tractability.
Dealing with Inconsistency for Reasoning over Knowledge Graphs: A Survey
Feb 26, 2025
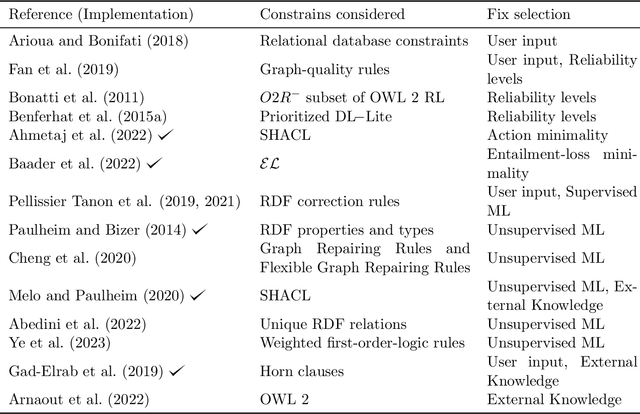
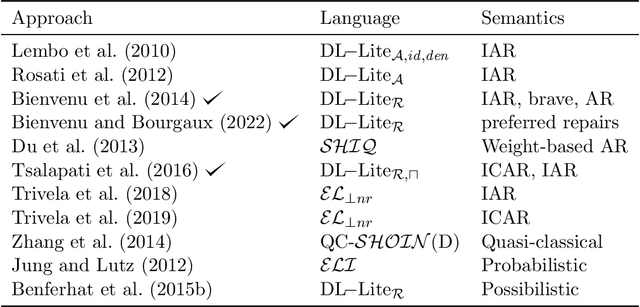
In Knowledge Graphs (KGs), where the schema of the data is usually defined by particular ontologies, reasoning is a necessity to perform a range of tasks, such as retrieval of information, question answering, and the derivation of new knowledge. However, information to populate KGs is often extracted (semi-) automatically from natural language resources, or by integrating datasets that follow different semantic schemas, resulting in KG inconsistency. This, however, hinders the process of reasoning. In this survey, we focus on how to perform reasoning on inconsistent KGs, by analyzing the state of the art towards three complementary directions: a) the detection of the parts of the KG that cause the inconsistency, b) the fixing of an inconsistent KG to render it consistent, and c) the inconsistency-tolerant reasoning. We discuss existing work from a range of relevant fields focusing on how, and in which cases they are related to the above directions. We also highlight persisting challenges and future directions.
Early Time-Series Classification Algorithms: An Empirical Comparison
Mar 03, 2022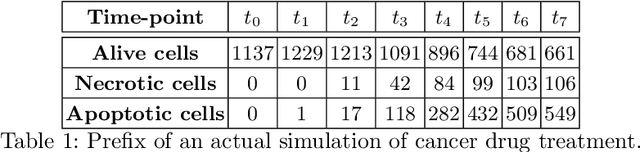
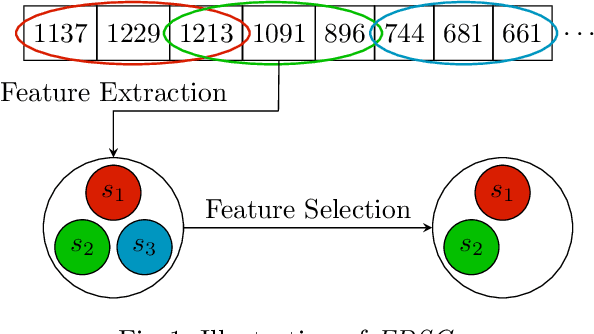
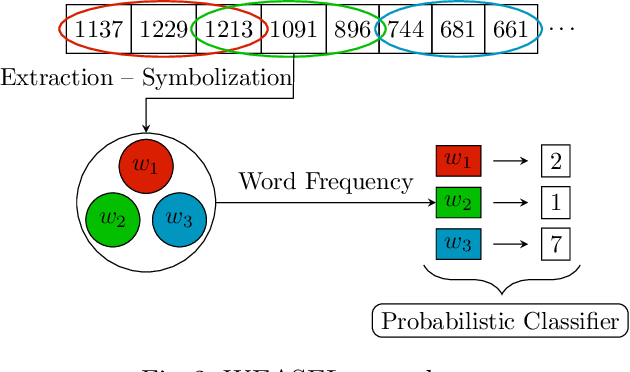
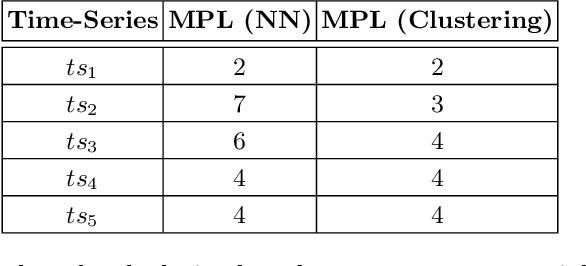
Early Time-Series Classification (ETSC) is the task of predicting the class of incoming time-series by observing as few measurements as possible. Such methods can be employed to obtain classification forecasts in many time-critical applications. However, available techniques are not equally suitable for every problem, since differentiations in the data characteristics can impact algorithm performance in terms of earliness, accuracy, F1-score, and training time. We evaluate six existing ETSC algorithms on publicly available data, as well as on two newly introduced datasets originating from the life sciences and maritime domains. Our goal is to provide a framework for the evaluation and comparison of ETSC algorithms and to obtain intuition on how such approaches perform on real-life applications. The presented framework may also serve as a benchmark for new related techniques.