 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory augment is All You Need for image restoration
Sep 04, 2023Image restoration is a low-level vision task, most CNN methods are designed as a black box, lacking transparency and internal aesthetics. Although some methods combining traditional optimization algorithms with DNNs have been proposed, they all have some limitations. In this paper, we propose a three-granularity memory layer and contrast learning named MemoryNet, specifically, dividing the samples into positive, negative, and actual three samples for contrastive learning, where the memory layer is able to preserve the deep features of the image and the contrastive learning converges the learned features to balance. Experiments on Derain/Deshadow/Deblur task demonstrate that these methods are effective in improving restoration performance. In addition, this paper's model obtains significant PSNR, SSIM gain on three datasets with different degradation types, which is a strong proof that the recovered images are perceptually realistic. The source code of MemoryNet can be obtained from https://github.com/zhangbaijin/MemoryNet
SpA-Former: Transformer image shadow detection and removal via spatial attention
Jun 29, 2022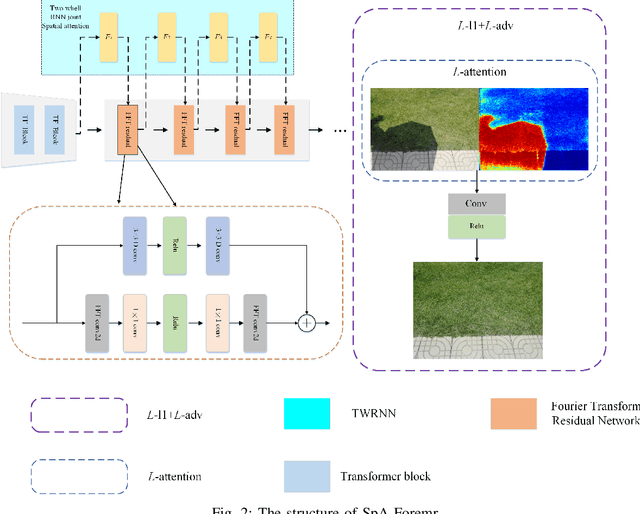
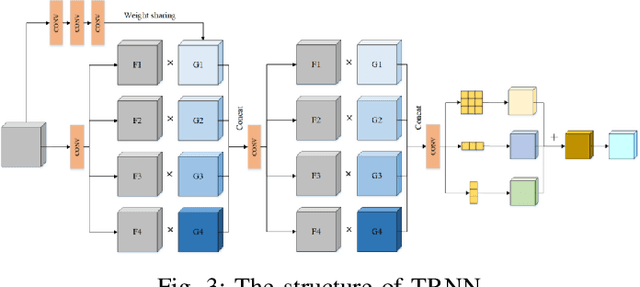


In this paper, we propose an end-to-end SpA-Former to recover a shadow-free image from a single shaded image. Unlike traditional methods that require two steps for shadow detection and then shadow removal, the SpA-Former unifies these steps into one, which is a one-stage network capable of directly learning the mapping function between shadows and no shadows, it does not require a separate shadow detection. Thus, SpA-former is adaptable to real image de-shadowing for shadows projected on different semantic regions. SpA-Former consists of transformer layer and a series of joint Fourier transform residual blocks and two-wheel joint spatial attention. The network in this paper is able to handle the task while achieving a very fast processing efficiency. Our code is relased on https://github.com/ zhangbaijin/Spatial-Transformer-shadow-removal