 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Principles of ReLU Networks with One Hidden Layer
Nov 11, 2024A neural network with one hidden layer or a two-layer network (regardless of the input layer) is the simplest feedforward neural network, whose mechanism may be the basis of more general network architectures. However, even to this type of simple architecture, it is also a ``black box''; that is, it remains unclear how to interpret the mechanism of its solutions obtained by the back-propagation algorithm and how to control the training process through a deterministic way. This paper systematically studies the first problem by constructing universal function-approximation solutions. It is shown that, both theoretically and experimentally, the training solution for the one-dimensional input could be completely understood, and that for a higher-dimensional input can also be well interpreted to some extent. Those results pave the way for thoroughly revealing the black box of two-layer ReLU networks and advance the understanding of deep ReLU networks.
On an Interpretation of ResNets via Solution Constructions
Dec 12, 2022This paper first constructs a typical solution of ResNets for multi-category classifications by the principle of gate-network controls and deep-layer classifications, from which a general interpretation of the ResNet architecture is given and the performance mechanism is explained. We then use more solutions to further demonstrate the generality of that interpretation. The universal-approximation capability of ResNets is proved.
Universal Solutions of Feedforward ReLU Networks for Interpolations
Aug 16, 2022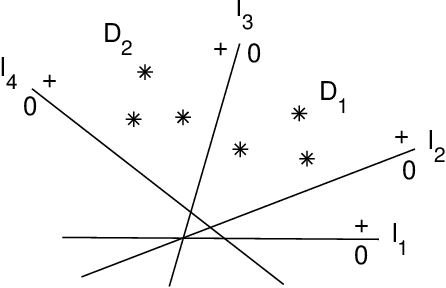
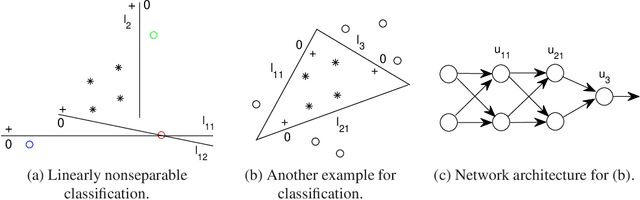
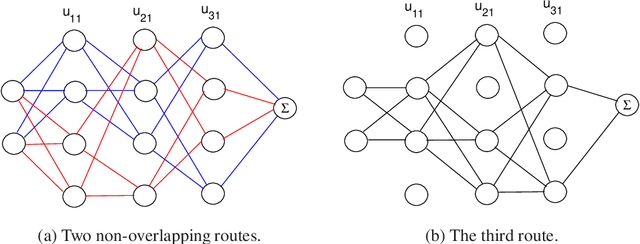
This paper provides a theoretical framework on the solution of feedforward ReLU networks for interpolations, in terms of what is called an interpolation matrix, which is the summary, extension and generalization of our three preceding works, with the expectation that the solution of engineering could be included in this framework and finally understood. To three-layer networks, we classify different kinds of solutions and model them in a normalized form; the solution finding is investigated by three dimensions, including data, networks and the training; the mechanism of overparameterization solutions is interpreted. To deep-layer networks, we present a general result called sparse-matrix principle, which could describe some basic behavior of deep layers and explain the phenomenon of the sparse-activation mode that appears in engineering applications associated with brain science; an advantage of deep layers compared to shallower ones is manifested in this principle. As applications, a general solution of deep neural networks for classification is constructed by that principle; and we also use the principle to study the data-disentangling property of encoders. Analogous to the three-layer case, the solution of deep layers is also explored through several dimensions. The mechanism of multi-output neural networks is explained from the perspective of interpolation matrices.
On a Mechanism Framework of Autoencoders
Aug 15, 2022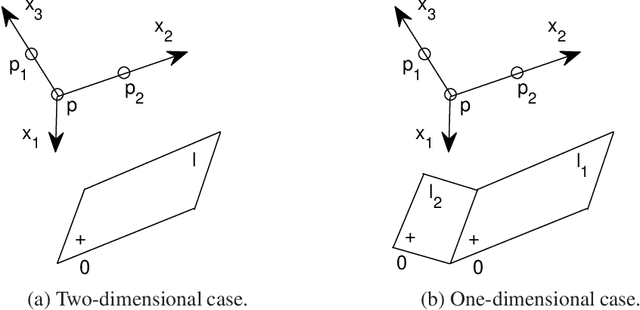
This paper proposes a theoretical framework on the mechanism of autoencoders. To the encoder part, under the main use of dimensionality reduction, we investigate its two fundamental properties: bijective maps and data disentangling. The general construction methods of an encoder that satisfies either or both of the above two properties are given. To the decoder part, as a consequence of the encoder constructions, we present a new basic principle of the solution, without using affine transforms. The generalization mechanism of autoencoders is modeled. The results of ReLU autoencoders are generalized to some non-ReLU cases, particularly for the sigmoid-unit autoencoder. Based on the theoretical framework above, we explain some experimental results of variational autoencoders, denoising autoencoders, and linear-unit autoencoders, with emphasis on the interpretation of the lower-dimensional representation of data via encoders; and the mechanism of image restoration through autoencoders is natural to be understood by those explanations. Compared to PCA and decision trees, the advantages of (generalized) autoencoders on dimensionality reduction and classification are demonstrated, respectively. Convolutional neural networks and randomly weighted neural networks are also interpreted by this framework.
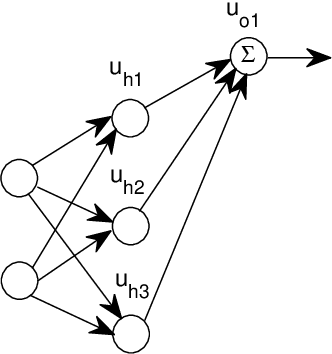
Theoretical Exploration of Solutions of Feedforward ReLU networks
Feb 09, 2022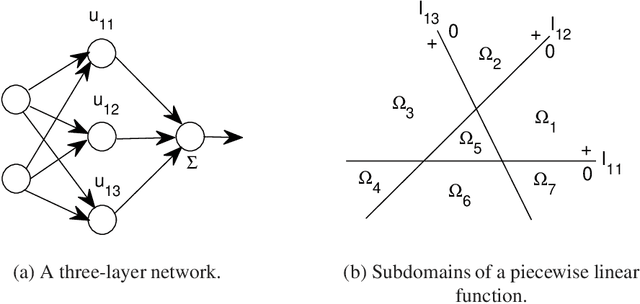
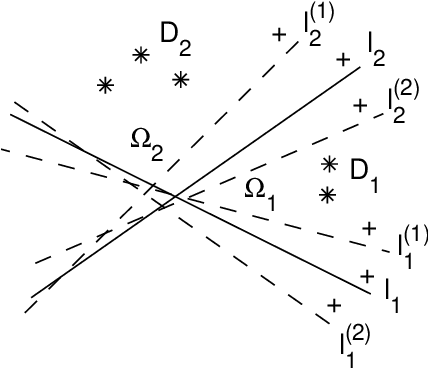
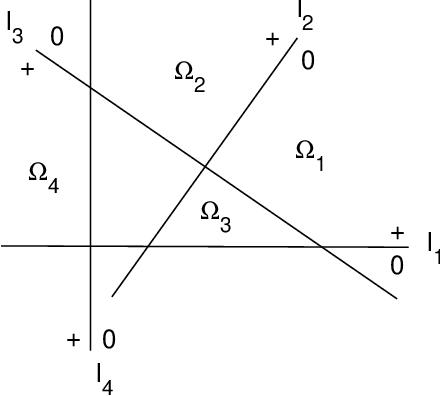
This paper aims to interpret the mechanism of feedforward ReLU networks by exploring their solutions for piecewise linear functions through basic rules. The constructed solutions should be universal enough to explain the network architectures of engineering. In order for that, we borrow the methodology of theoretical physics to develop the theories. Some of the consequences of our theories include: Under geometric backgrounds, the solutions of both three-layer networks and deep-layer networks are presented, and the solution universality is ensured by several ways; We give clear and intuitive interpretations of each component of network architectures, such as the parameter-sharing mechanism for multi-output, the function of each layer, the advantage of deep layers, the redundancy of parameters, and so on. We explain three typical network architectures: the subnetwork of last three layers of convolutional networks, multi-layer feedforward networks, and the decoder of autoencoders. This paper is expected to provide a basic foundation of theories of feedforward ReLU networks for further investigations.
A General Interpretation of Deep Learning by Affine Transform and Region Dividing without Mutual Interference
Jul 04, 2019
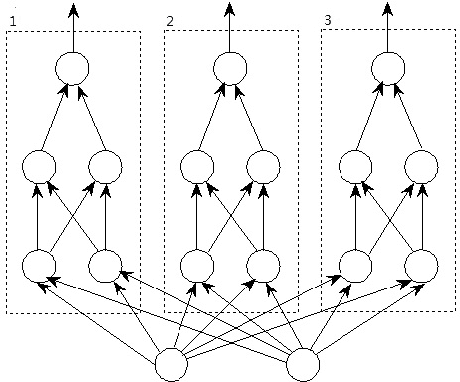
This paper mainly deals with the "black-box" problem of deep learning composed of ReLUs with n-dimensional input space, as well as some discussions of sigmoid-unit deep learning. We prove that a region of input space can be transmitted to succeeding layers one by one in the sense of affine transforms; adding a new layer can help to realize the subregion dividing without influencing an excluded region, which is a key distinctive feature of deep leaning. Then constructive proof is given to demonstrate that multi-category data points can be classified by deep learning. Furthermore, we prove that deep learning can approximate any continuous function on a closed set of n-dimensional space with arbitrary precision. Finally, generalize some of the conclusions of ReLU deep learning to the case of sigmoid-unit deep learning.