 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Prediction Mechanism of Sentiments by XAI Visualization
Mar 03, 2020
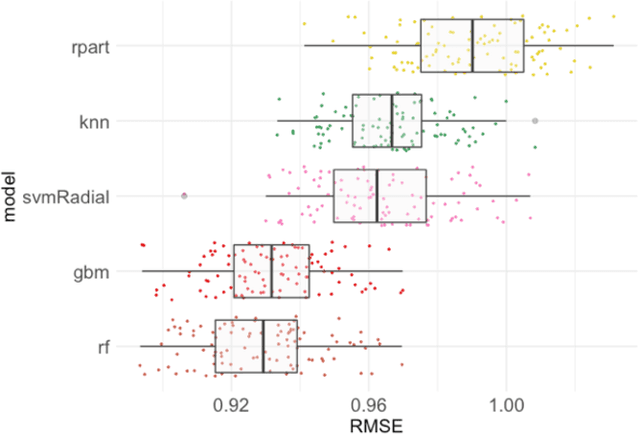
People often rely on online reviews to make purchase decisions. The present work aimed to gain an understanding of a machine learning model's prediction mechanism by visualizing the effect of sentiments extracted from online hotel reviews with explainable AI (XAI) methodology. Study 1 used the extracted sentiments as features to predict the review ratings by five machine learning algorithms (knn, CART decision trees, support vector machines, random forests, gradient boosting machines) and identified random forests as best algorithm. Study 2 analyzed the random forests model by feature importance and revealed the sentiments joy, disgust, positive and negative as the most predictive features. Furthermore, the visualization of additive variable attributions and their prediction distribution showed correct prediction in direction and effect size for the 5-star rating but partially wrong direction and insufficient effect size for the 1-star rating. These prediction details were corroborated by a what-if analysis for the four top features. In conclusion, the prediction mechanism of a machine learning model can be uncovered by visualization of particular observations. Comparing instances of contrasting ground truth values can draw a differential picture of the prediction mechanism and inform decisions for model improvement.
What Emotions Make One or Five Stars? Understanding Ratings of Online Product Reviews by Sentiment Analysis and XAI
Feb 29, 2020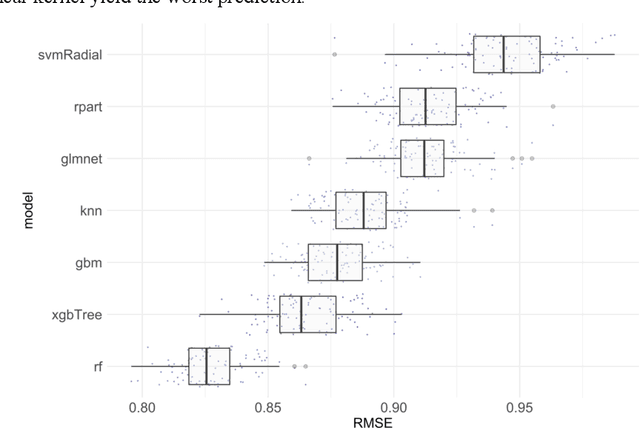
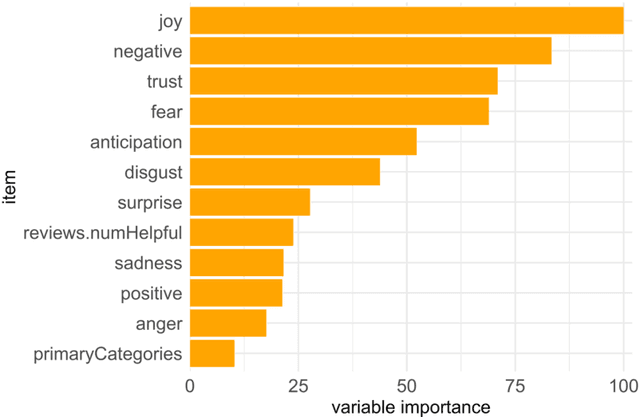
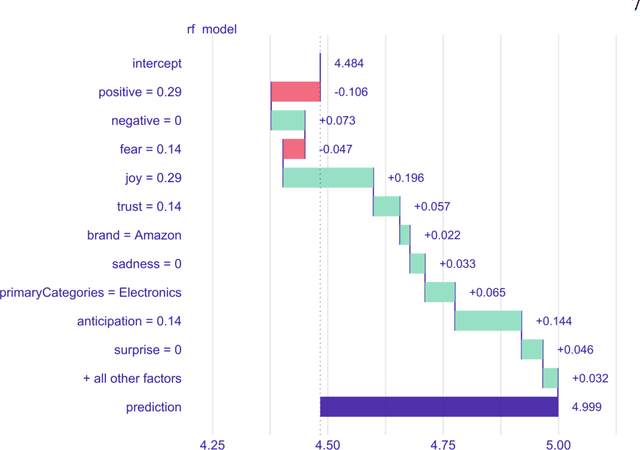
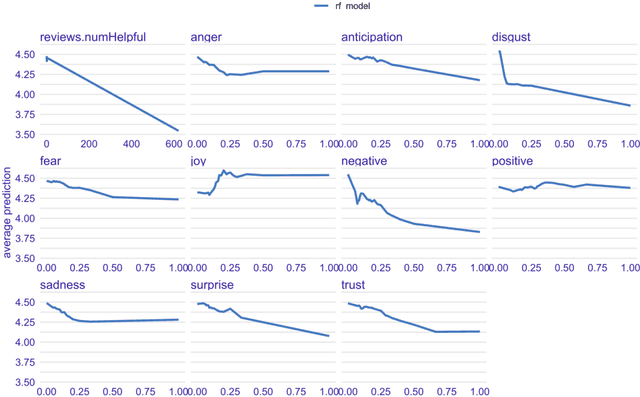
When people buy products online, they primarily base their decisions on the recommendations of others given in online reviews. The current work analyzed these online reviews by sentiment analysis and used the extracted sentiments as features to predict the product ratings by several machine learning algorithms. These predictions were disentangled by various meth-ods of explainable AI (XAI) to understand whether the model showed any bias during prediction. Study 1 benchmarked these algorithms (knn, support vector machines, random forests, gradient boosting machines, XGBoost) and identified random forests and XGBoost as best algorithms for predicting the product ratings. In Study 2, the analysis of global feature importance identified the sentiment joy and the emotional valence negative as most predictive features. Two XAI visualization methods, local feature attributions and partial dependency plots, revealed several incorrect prediction mechanisms on the instance-level. Performing the benchmarking as classification, Study 3 identified a high no-information rate of 64.4% that indicated high class imbalance as underlying reason for the identified problems. In conclusion, good performance by machine learning algorithms must be taken with caution because the dataset, as encountered in this work, could be biased towards certain predictions. This work demonstrates how XAI methods reveal such prediction bias.
Human-in-the-Loop Design Cycles -- A Process Framework that Integrates Design Sprints, Agile Processes, and Machine Learning with Humans
Feb 29, 2020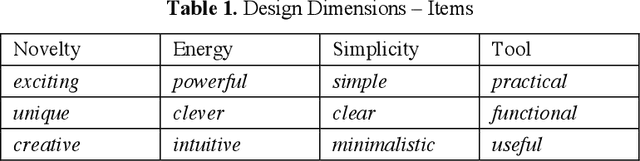
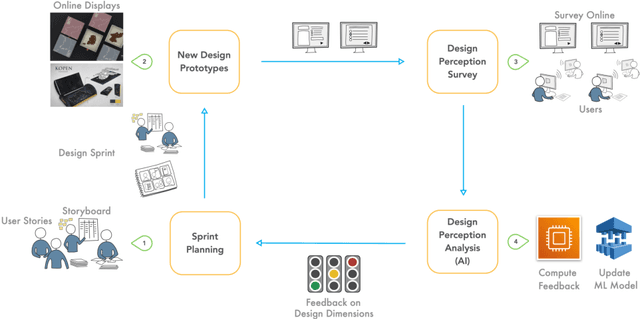
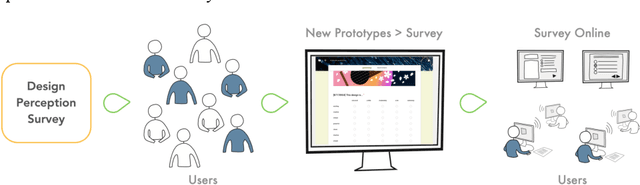
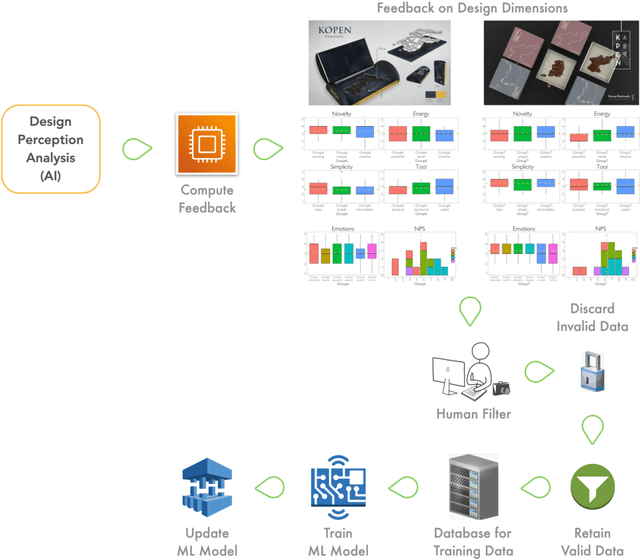
Demands on more transparency of the backbox nature of machine learning models have led to the recent rise of human-in-the-loop in machine learning, i.e. processes that integrate humans in the training and application of machine learning models. The present work argues that this process requirement does not represent an obstacle but an opportunity to optimize the design process. Hence, this work proposes a new process framework, Human-in-the-learning-loop (HILL) Design Cycles - a design process that integrates the structural elements of agile and design thinking process, and controls the training of a machine learning model by the human in the loop. The HILL Design Cycles process replaces the qualitative user testing by a quantitative psychometric measurement instrument for design perception. The generated user feedback serves to train a machine learning model and to instruct the subsequent design cycle along four design dimensions (novelty, energy, simplicity, tool). Mapping the four-dimensional user feedback into user stories and priorities, the design sprint thus transforms the user feedback directly into the implementation process. The human in the loop is a quality engineer who scrutinizes the collected user feedback to prevents invalid data to enter machine learning model training.
Are You an Introvert or Extrovert? Accurate Classification With Only Ten Predictors
Feb 29, 2020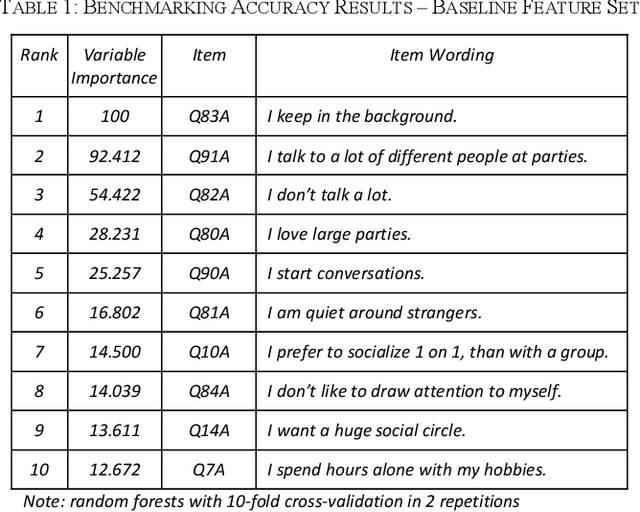
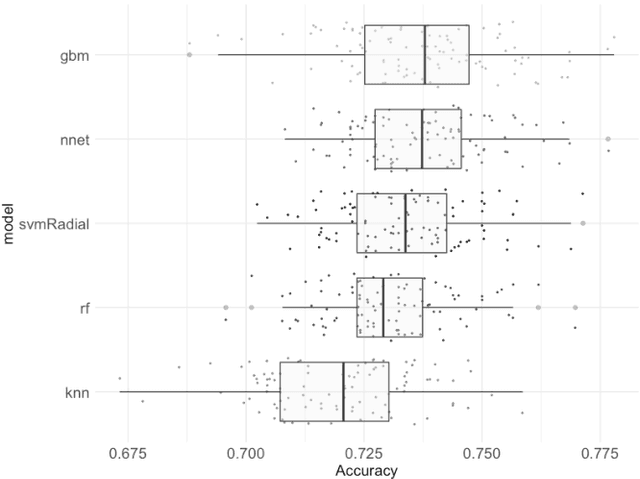
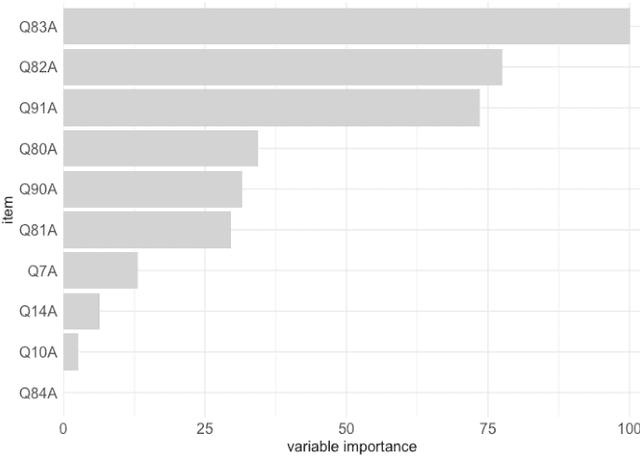
This paper investigates how accurately the prediction of being an introvert vs. extrovert can be made with less than ten predictors. The study is based on a previous data collection of 7161 respondents of a survey on 91 personality and 3 demographic items. The results show that it is possible to effectively reduce the size of this measurement instrument from 94 to 10 features with a performance loss of only 1%, achieving an accuracy of 73.81% on unseen data. Class imbalance correction methods like SMOTE or ADASYN showed considerable improvement on the validation set but only minor performance improvement on the testing set.
Who Wins the Game of Thrones? How Sentiments Improve the Prediction of Candidate Choice
Feb 29, 2020
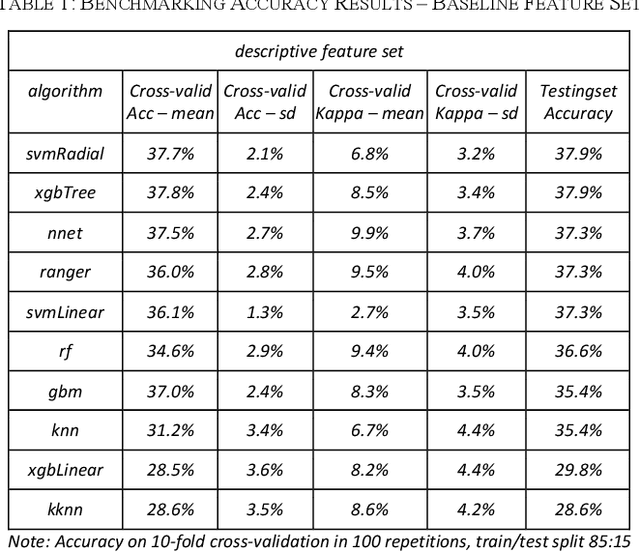
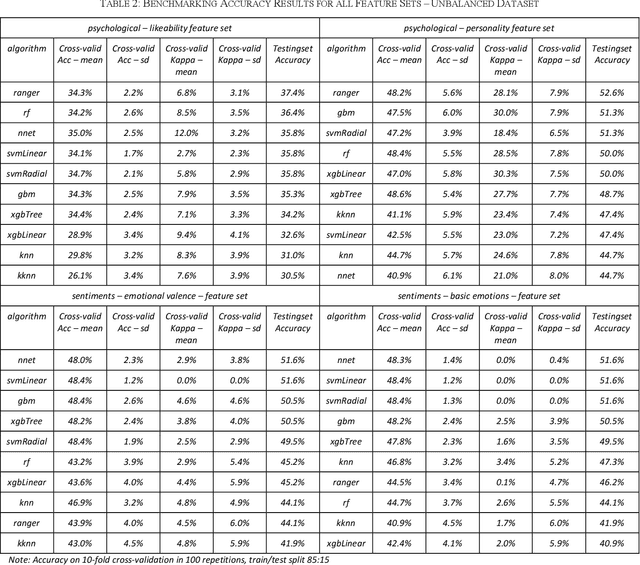
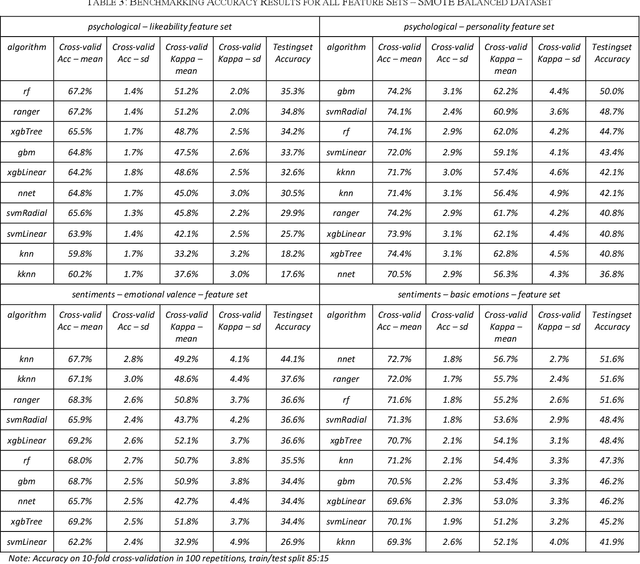
This paper analyzes how candidate choice prediction improves by different psychological predictors. To investigate this question, it collected an original survey dataset featuring the popular TV series "Game of Thrones". The respondents answered which character they anticipated to win in the final episode of the series, and explained their choice of the final candidate in free text from which sentiments were extracted. These sentiments were compared to feature sets derived from candidate likeability and candidate personality ratings. In our benchmarking of 10-fold cross-validation in 100 repetitions, all feature sets except the likeability ratings yielded a 10-11% improvement in accuracy on the holdout set over the base model. Treating the class imbalance with synthetic minority oversampling (SMOTE) increased holdout set performance by 20-34% but surprisingly not testing set performance. Taken together, our study provides a quantified estimation of the additional predictive value of psychological predictors. Likeability ratings were clearly outperformed by the feature sets based on personality, emotional valence, and basic emotions.
A Pragmatic AI Approach to Creating Artistic Visual Variations by Neural Style Transfer
May 28, 2018



On a constant quest for inspiration, designers can become more effective with tools that facilitate their creative process and let them overcome design fixation. This paper explores the practicality of applying neural style transfer as an emerging design tool for generating creative digital content. To this aim, the present work explores a well-documented neural style transfer algorithm (Johnson 2016) in four experiments on four relevant visual parameters: number of iterations, learning rate, total variation, content vs. style weight. The results allow a pragmatic recommendation of parameter configuration (number of iterations: 200 to 300, learning rate: 2e-1 to 4e-1, total variation: 1e-4 to 1e-8, content weights vs. style weights: 50:100 to 200:100) that saves extensive experimentation time and lowers the technical entry barrier. With this rule-of-thumb insight, visual designers can effectively apply deep learning to create artistic visual variations of digital content. This could enable designers to leverage AI for creating design works as state-of-the-art.