 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbor: A Framework for Reliable Navigation of Critical Conversation Flows
Feb 17, 2026Large language models struggle to maintain strict adherence to structured workflows in high-stakes domains such as healthcare triage. Monolithic approaches that encode entire decision structures within a single prompt are prone to instruction-following degradation as prompt length increases, including lost-in-the-middle effects and context window overflow. To address this gap, we present Arbor, a framework that decomposes decision tree navigation into specialized, node-level tasks. Decision trees are standardized into an edge-list representation and stored for dynamic retrieval. At runtime, a directed acyclic graph (DAG)-based orchestration mechanism iteratively retrieves only the outgoing edges of the current node, evaluates valid transitions via a dedicated LLM call, and delegates response generation to a separate inference step. The framework is agnostic to the underlying decision logic and model provider. Evaluated against single-prompt baselines across 10 foundation models using annotated turns from real clinical triage conversations. Arbor improves mean turn accuracy by 29.4 percentage points, reduces per-turn latency by 57.1%, and achieves an average 14.4x reduction in per-turn cost. These results indicate that architectural decomposition reduces dependence on intrinsic model capability, enabling smaller models to match or exceed larger models operating under single-prompt baselines.
Unbabel's Participation in the WMT20 Metrics Shared Task
Oct 29, 2020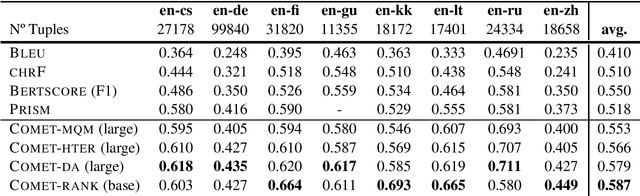

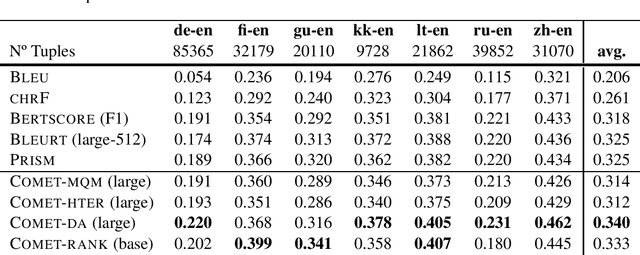
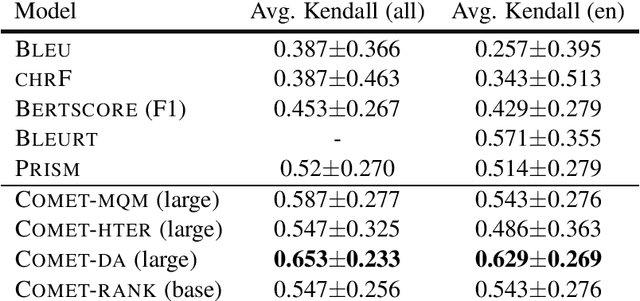
We present the contribution of the Unbabel team to the WMT 2020 Shared Task on Metrics. We intend to participate on the segment-level, document-level and system-level tracks on all language pairs, as well as the 'QE as a Metric' track. Accordingly, we illustrate results of our models in these tracks with reference to test sets from the previous year. Our submissions build upon the recently proposed COMET framework: We train several estimator models to regress on different human-generated quality scores and a novel ranking model trained on relative ranks obtained from Direct Assessments. We also propose a simple technique for converting segment-level predictions into a document-level score. Overall, our systems achieve strong results for all language pairs on previous test sets and in many cases set a new state-of-the-art.