 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Grey-box Modelling of Phaser Effects using Frame-based Spectral Processing
Jun 02, 2023



Machine learning approaches to modelling analog audio effects have seen intensive investigation in recent years, particularly in the context of non-linear time-invariant effects such as guitar amplifiers. For modulation effects such as phasers, however, new challenges emerge due to the presence of the low-frequency oscillator which controls the slowly time-varying nature of the effect. Existing approaches have either required foreknowledge of this control signal, or have been non-causal in implementation. This work presents a differentiable digital signal processing approach to modelling phaser effects in which the underlying control signal and time-varying spectral response of the effect are jointly learned. The proposed model processes audio in short frames to implement a time-varying filter in the frequency domain, with a transfer function based on typical analog phaser circuit topology. We show that the model can be trained to emulate an analog reference device, while retaining interpretable and adjustable parameters. The frame duration is an important hyper-parameter of the proposed model, so an investigation was carried out into its effect on model accuracy. The optimal frame length depends on both the rate and transient decay-time of the target effect, but the frame length can be altered at inference time without a significant change in accuracy.
Puffin: pitch-synchronous neural waveform generation for fullband speech on modest devices
Nov 25, 2022


We present a neural vocoder designed with low-powered Alternative and Augmentative Communication devices in mind. By combining elements of successful modern vocoders with established ideas from an older generation of technology, our system is able to produce high quality synthetic speech at 48kHz on devices where neural vocoders are otherwise prohibitively complex. The system is trained adversarially using differentiable pitch synchronous overlap add, and reduces complexity by relying on pitch synchronous Inverse Short-Time Fourier Transform (ISTFT) to generate speech samples. Our system achieves comparable quality with a strong (HiFi-GAN) baseline while using only a fraction of the compute. We present results of a perceptual evaluation as well as an analysis of system complexity.
Autovocoder: Fast Waveform Generation from a Learned Speech Representation using Differentiable Digital Signal Processing
Nov 13, 2022Most state-of-the-art Text-to-Speech systems use the mel-spectrogram as an intermediate representation, to decompose the task into acoustic modelling and waveform generation. A mel-spectrogram is extracted from the waveform by a simple, fast DSP operation, but generating a high-quality waveform from a mel-spectrogram requires computationally expensive machine learning: a neural vocoder. Our proposed ``autovocoder'' reverses this arrangement. We use machine learning to obtain a representation that replaces the mel-spectrogram, and that can be inverted back to a waveform using simple, fast operations including a differentiable implementation of the inverse STFT. The autovocoder generates a waveform 5 times faster than the DSP-based Griffin-Lim algorithm, and 14 times faster than the neural vocoder HiFi-GAN. We provide perceptual listening test results to confirm that the speech is of comparable quality to HiFi-GAN in the copy synthesis task.
Predicting pairwise preferences between TTS audio stimuli using parallel ratings data and anti-symmetric twin neural networks
Sep 22, 2022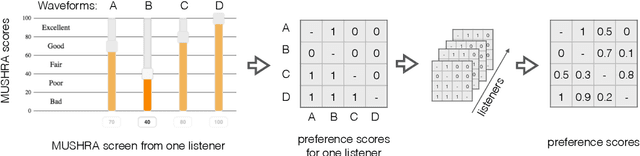
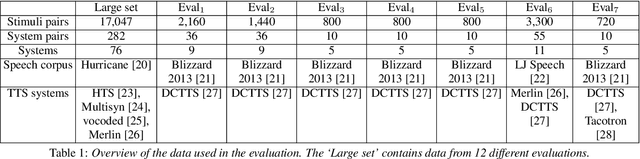
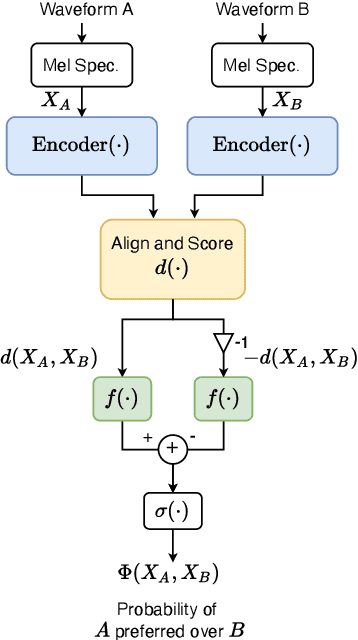
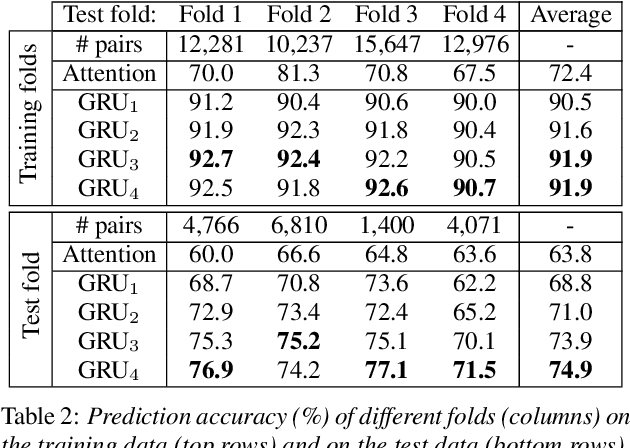
Automatically predicting the outcome of subjective listening tests is a challenging task. Ratings may vary from person to person even if preferences are consistent across listeners. While previous work has focused on predicting listeners' ratings (mean opinion scores) of individual stimuli, we focus on the simpler task of predicting subjective preference given two speech stimuli for the same text. We propose a model based on anti-symmetric twin neural networks, trained on pairs of waveforms and their corresponding preference scores. We explore both attention and recurrent neural nets to account for the fact that stimuli in a pair are not time aligned. To obtain a large training set we convert listeners' ratings from MUSHRA tests to values that reflect how often one stimulus in the pair was rated higher than the other. Specifically, we evaluate performance on data obtained from twelve MUSHRA evaluations conducted over five years, containing different TTS systems, built from data of different speakers. Our results compare favourably to a state-of-the-art model trained to predict MOS scores.