 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential equation quantum solvers: engineering measurements to reduce cost
Mar 28, 2025Quantum computers have been proposed as a solution for efficiently solving non-linear differential equations (DEs), a fundamental task across diverse technological and scientific domains. However, a crucial milestone in this regard is to design protocols that are hardware-aware, making efficient use of limited available quantum resources. We focus here on promising variational methods derived from scientific machine learning: differentiable quantum circuits (DQC), addressing specifically their cost in number of circuit evaluations. Reducing the number of quantum circuit evaluations is particularly valuable in hybrid quantum/classical protocols, where the time required to interface and run quantum hardware at each cycle can impact the total wall-time much more than relatively inexpensive classical post-processing overhead. Here, we propose and test two sample-efficient protocols for solving non-linear DEs, achieving exponential savings in quantum circuit evaluations. These protocols are based on redesigning the extraction of information from DQC in a ``measure-first" approach, by introducing engineered cost operators similar to the randomized-measurement toolbox (i.e. classical shadows). In benchmark simulations on one and two-dimensional DEs, we report up to $\sim$ 100 fold reductions in circuit evaluations. Our protocols thus hold the promise to unlock larger and more challenging non-linear differential equation demonstrations with existing quantum hardware.
Quantum computing and persistence in topological data analysis
Oct 28, 2024Topological data analysis (TDA) aims to extract noise-robust features from a data set by examining the number and persistence of holes in its topology. We show that a computational problem closely related to a core task in TDA -- determining whether a given hole persists across different length scales -- is $\mathsf{BQP}_1$-hard and contained in $\mathsf{BQP}$. This result implies an exponential quantum speedup for this problem under standard complexity-theoretic assumptions. Our approach relies on encoding the persistence of a hole in a variant of the guided sparse Hamiltonian problem, where the guiding state is constructed from a harmonic representative of the hole.
On the relation between trainability and dequantization of variational quantum learning models
Jun 11, 2024



The quest for successful variational quantum machine learning (QML) relies on the design of suitable parametrized quantum circuits (PQCs), as analogues to neural networks in classical machine learning. Successful QML models must fulfill the properties of trainability and non-dequantization, among others. Recent works have highlighted an intricate interplay between trainability and dequantization of such models, which is still unresolved. In this work we contribute to this debate from the perspective of machine learning, proving a number of results identifying, among others when trainability and non-dequantization are not mutually exclusive. We begin by providing a number of new somewhat broader definitions of the relevant concepts, compared to what is found in other literature, which are operationally motivated, and consistent with prior art. With these precise definitions given and motivated, we then study the relation between trainability and dequantization of variational QML. Next, we also discuss the degrees of "variationalness" of QML models, where we distinguish between models like the hardware efficient ansatz and quantum kernel methods. Finally, we introduce recipes for building PQC-based QML models which are both trainable and nondequantizable, and corresponding to different degrees of variationalness. We do not address the practical utility for such models. Our work however does point toward a way forward for finding more general constructions, for which finding applications may become feasible.
Exponential separations between classical and quantum learners
Jun 28, 2023
Despite significant effort, the quantum machine learning community has only demonstrated quantum learning advantages for artificial cryptography-inspired datasets when dealing with classical data. In this paper we address the challenge of finding learning problems where quantum learning algorithms can achieve a provable exponential speedup over classical learning algorithms. We reflect on computational learning theory concepts related to this question and discuss how subtle differences in definitions can result in significantly different requirements and tasks for the learner to meet and solve. We examine existing learning problems with provable quantum speedups and find that they largely rely on the classical hardness of evaluating the function that generates the data, rather than identifying it. To address this, we present two new learning separations where the classical difficulty primarily lies in identifying the function generating the data. Furthermore, we explore computational hardness assumptions that can be leveraged to prove quantum speedups in scenarios where data is quantum-generated, which implies likely quantum advantages in a plethora of more natural settings (e.g., in condensed matter and high energy physics). We also discuss the limitations of the classical shadow paradigm in the context of learning separations, and how physically-motivated settings such as characterizing phases of matter and Hamiltonian learning fit in the computational learning framework.
Shadows of quantum machine learning
May 31, 2023Quantum machine learning is often highlighted as one of the most promising uses for a quantum computer to solve practical problems. However, a major obstacle to the widespread use of quantum machine learning models in practice is that these models, even once trained, still require access to a quantum computer in order to be evaluated on new data. To solve this issue, we suggest that following the training phase of a quantum model, a quantum computer could be used to generate what we call a classical shadow of this model, i.e., a classically computable approximation of the learned function. While recent works already explore this idea and suggest approaches to construct such shadow models, they also raise the possibility that a completely classical model could be trained instead, thus circumventing the need for a quantum computer in the first place. In this work, we take a novel approach to define shadow models based on the frameworks of quantum linear models and classical shadow tomography. This approach allows us to show that there exist shadow models which can solve certain learning tasks that are intractable for fully classical models, based on widely-believed cryptography assumptions. We also discuss the (un)likeliness that all quantum models could be shadowfiable, based on common assumptions in complexity theory.
On establishing learning separations between classical and quantum machine learning with classical data
Aug 12, 2022Despite years of effort, the quantum machine learning community has only been able to show quantum learning advantages for certain contrived cryptography-inspired datasets in the case of classical data. In this note, we discuss the challenges of finding learning problems that quantum learning algorithms can learn much faster than any classical learning algorithm, and we study how to identify such learning problems. Specifically, we reflect on the main concepts in computational learning theory pertaining to this question, and we discuss how subtle changes in definitions can mean conceptually significantly different tasks, which can either lead to a separation or no separation at all. Moreover, we study existing learning problems with a provable quantum speedup to distill sets of more general and sufficient conditions (i.e., ``checklists'') for a learning problem to exhibit a separation between classical and quantum learners. These checklists are intended to streamline one's approach to proving quantum speedups for learning problems, or to elucidate bottlenecks. Finally, to illustrate its application, we analyze examples of potential separations (i.e., when the learning problem is build from computational separations, or when the data comes from a quantum experiment) through the lens of our approach.
High Dimensional Quantum Learning With Small Quantum Computers
Mar 25, 2022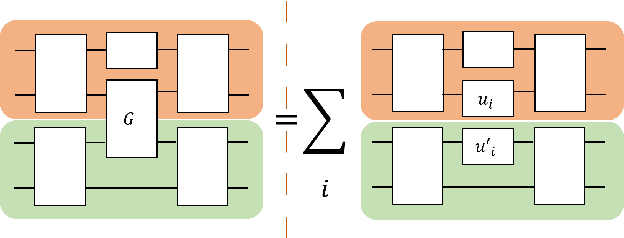
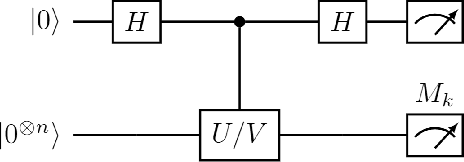
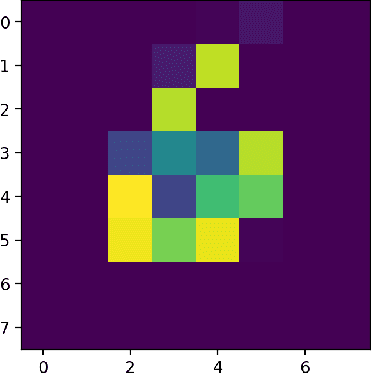
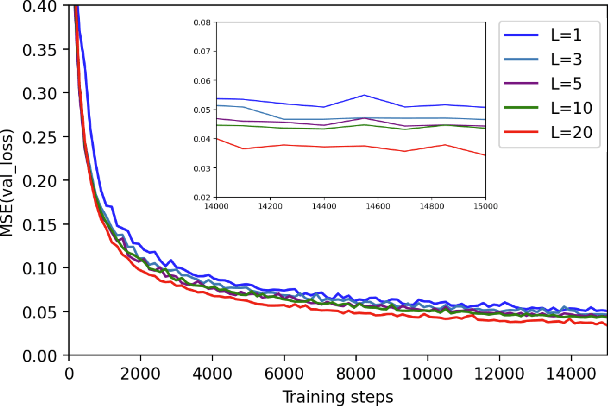
Quantum computers hold great promise to enhance machine learning, but their current qubit counts restrict the realisation of this promise. In an attempt to placate this limitation techniques can be applied for evaluating a quantum circuit using a machine with fewer qubits than the circuit naively requires. These techniques work by evaluating many smaller circuits on the smaller machine, that are then combined in a polynomial to replicate the output of the larger machine. This scheme requires more circuit evaluations than are practical for general circuits. However, we investigate the possibility that for certain applications many of these subcircuits are superfluous, and that a much smaller sum is sufficient to estimate the full circuit. We construct a machine learning model that may be capable of approximating the outputs of the larger circuit with much fewer circuit evaluations. We successfully apply our model to the task of digit recognition, using simulated quantum computers much smaller than the data dimension. The model is also applied to the task of approximating a random 10 qubit PQC with simulated access to a 5 qubit computer, even with only relatively modest number of circuits our model provides an accurate approximation of the 10 qubit PQCs output, superior to a neural network attempt. The developed method might be useful for implementing quantum models on larger data throughout the NISQ era.
Structural risk minimization for quantum linear classifiers
May 12, 2021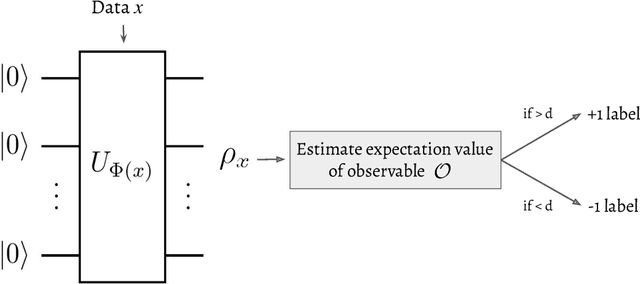
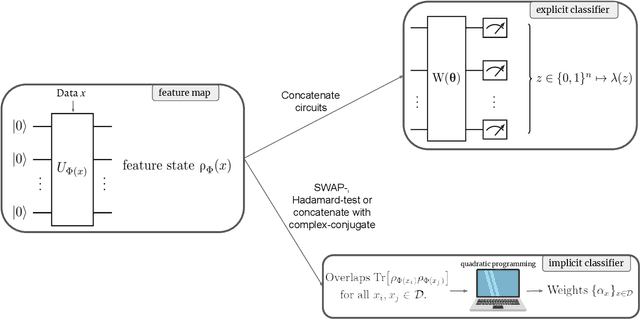
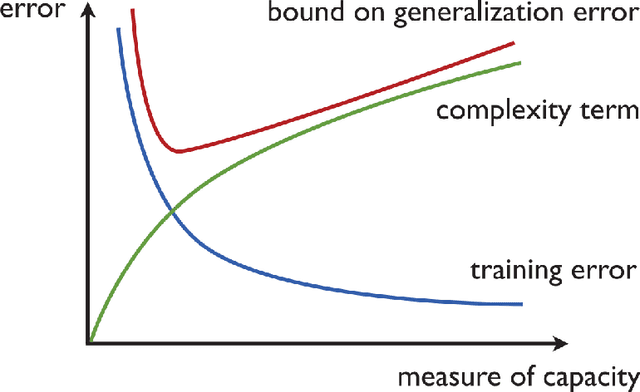
Quantum machine learning (QML) stands out as one of the typically highlighted candidates for quantum computing's near-term "killer application". In this context, QML models based on parameterized quantum circuits comprise a family of machine learning models that are well suited for implementations on near-term devices and that can potentially harness computational powers beyond what is efficiently achievable on a classical computer. However, how to best use these models -- e.g., how to control their expressivity to best balance between training accuracy and generalization performance -- is far from understood. In this paper we investigate capacity measures of two closely related QML models called explicit and implicit quantum linear classifiers (also called the quantum variational method and quantum kernel estimator) with the objective of identifying new ways to implement structural risk minimization -- i.e., how to balance between training accuracy and generalization performance. In particular, we identify that the rank and Frobenius norm of the observables used in the QML model closely control the model's capacity. Additionally, we theoretically investigate the effect that these model parameters have on the training accuracy of the QML model. Specifically, we show that there exists datasets that require a high-rank observable for correct classification, and that there exists datasets that can only be classified with a given margin using an observable of at least a certain Frobenius norm. Our results provide new options for performing structural risk minimization for QML models.
Variational quantum policies for reinforcement learning
Mar 09, 2021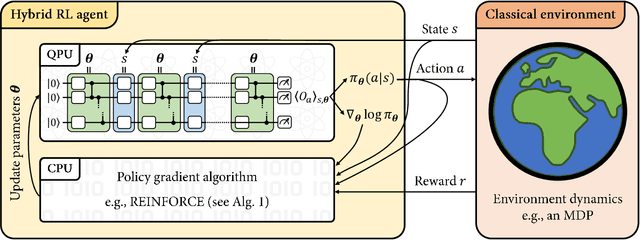

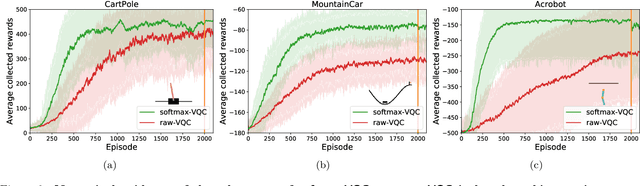
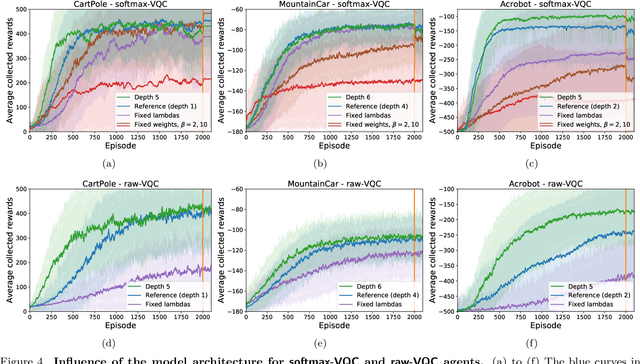
Variational quantum circuits have recently gained popularity as quantum machine learning models. While considerable effort has been invested to train them in supervised and unsupervised learning settings, relatively little attention has been given to their potential use in reinforcement learning. In this work, we leverage the understanding of quantum policy gradient algorithms in a number of ways. First, we investigate how to construct and train reinforcement learning policies based on variational quantum circuits. We propose several designs for quantum policies, provide their learning algorithms, and test their performance on classical benchmarking environments. Second, we show the existence of task environments with a provable separation in performance between quantum learning agents and any polynomial-time classical learner, conditioned on the widely-believed classical hardness of the discrete logarithm problem. We also consider more natural settings, in which we show an empirical quantum advantage of our quantum policies over standard neural-network policies. Our results constitute a first step towards establishing a practical near-term quantum advantage in a reinforcement learning setting. Additionally, we believe that some of our design choices for variational quantum policies may also be beneficial to other models based on variational quantum circuits, such as quantum classifiers and quantum regression models.
Towards quantum advantage for topological data analysis
May 06, 2020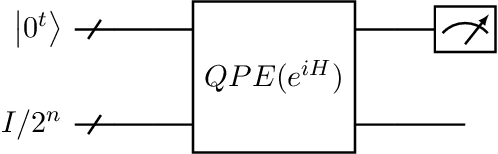
A particularly promising line of quantum machine leaning (QML) algorithms with the potential to exhibit exponential speedups over their classical counterparts has recently been set back by a series of "dequantization" results, that is, quantum-inspired classical algorithms which perform equally well in essence. This raises the important question whether other QML algorithms are susceptible to such dequantization, or whether it can be formally argued that they are out of reach of classical computers. In this paper, we study the quantum algorithm for topological data analysis by Lloyd, Garnerone and Zanardi (LGZ). We provide evidence that certain crucial steps in this algorithm solve problems that are classically intractable by closely relating them to the one clean qubit model, a restricted model of quantum computation whose power is strongly believed to lie beyond that of classical computation. While our results do not imply that the topological data analysis problem solved by the LGZ algorithm (i.e., Betti number estimation) is itself DQC1-hard, our work does provide the first steps towards answering the question of whether it is out of reach of classical computers. Additionally, we discuss how to extend the applicability of this algorithm beyond its original aim of estimating Betti numbers and demonstrate this by looking into quantum algorithms for spectral entropy estimation. Finally, we briefly consider the suitability of the LGZ algorithm for near-term implementations.