 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemisupervised Adversarial Neural Networks for Cyber Security Transfer Learning
Jul 25, 2019
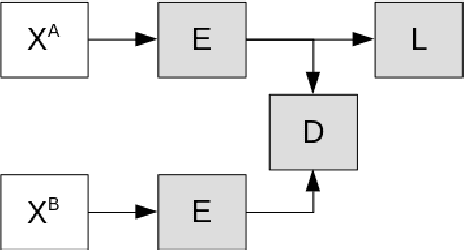
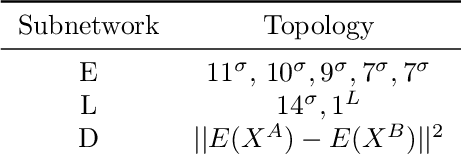
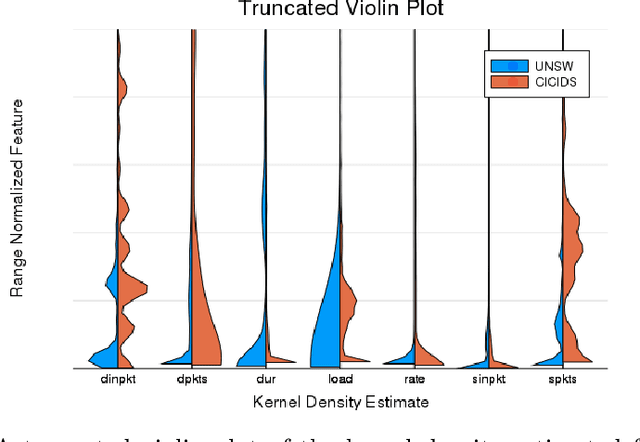
On the path to establishing a global cybersecurity framework where each enterprise shares information about malicious behavior, an important question arises. How can a machine learning representation characterizing a cyber attack on one network be used to detect similar attacks on other enterprise networks if each networks has wildly different distributions of benign and malicious traffic? We address this issue by comparing the results of naively transferring a model across network domains and using CORrelation ALignment, to our novel adversarial Siamese neural network. Our proposed model learns attack representations that are more invariant to each network's particularities via an adversarial approach. It uses a simple ranking loss that prioritizes the labeling of the most egregious malicious events correctly over average accuracy. This is appropriate for driving an alert triage workflow wherein an analyst only has time to inspect the top few events ranked highest by the model. In terms of accuracy, the other approaches fail completely to detect any malicious events when models were trained on one dataset are evaluated on another for the first 100 events. While, the method presented here retrieves sizable proportions of malicious events, at the expense of some training instabilities due in adversarial modeling. We evaluate these approaches using 2 publicly available networking datasets, and suggest areas for future research.
Uncharted Forest a Technique for Exploratory Data Analysis
Jun 30, 2018
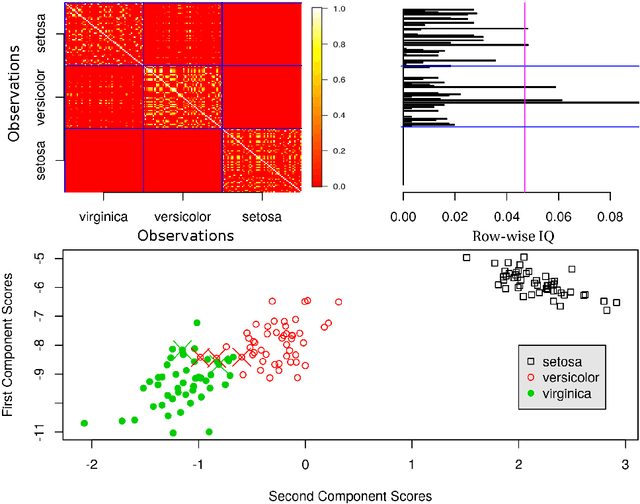
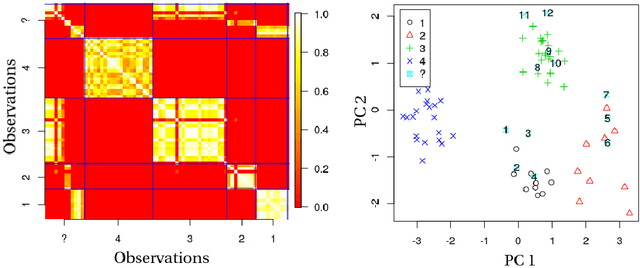
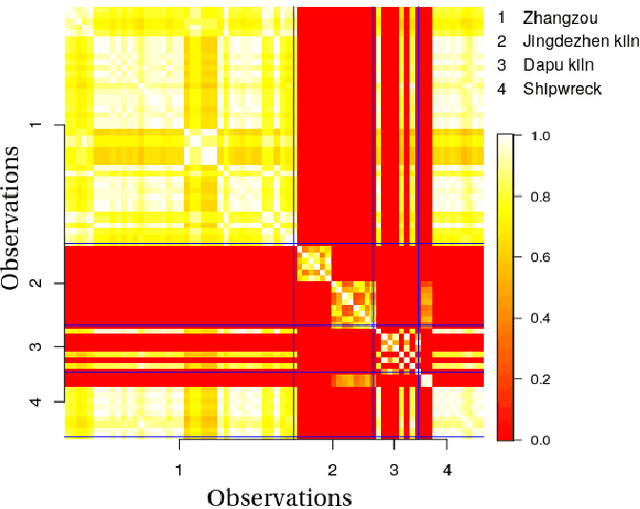
Exploratory data analysis is crucial for developing and understanding classification models from high-dimensional datasets. We explore the utility of a new unsupervised tree ensemble called uncharted forest for visualizing class associations, sample-sample associations, class heterogeneity, and uninformative classes for provenance studies. The uncharted forest algorithm can be used to partition data using random selections of variables and metrics based on statistical spread. After each tree is grown, a tally of the samples that arrive at every terminal node is maintained. Those tallies are stored in single sample association matrix and a likelihood measure for each sample being partitioned with one another can be made. That matrix may be readily viewed as a heat map, and the probabilities can be quantified via new metrics that account for class or cluster membership. We display the advantages and limitations of using this technique by applying it to two classification datasets and three provenance study datasets. Two of the metrics presented in this paper are also compared with widely used metrics from two algorithms that have variance-based clustering mechanisms.
Band Target Entropy Minimization and Target Partial Least Squares for Spectral Recovery and Calibration
Mar 27, 2018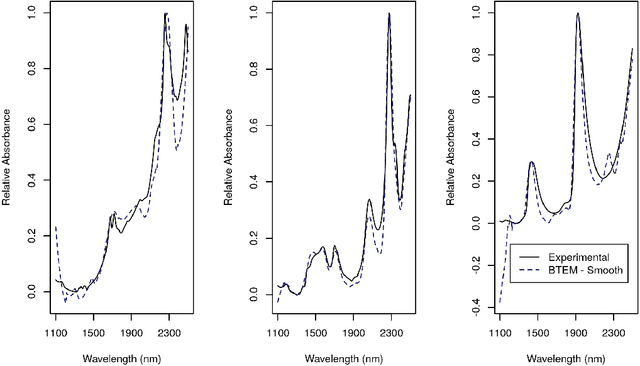
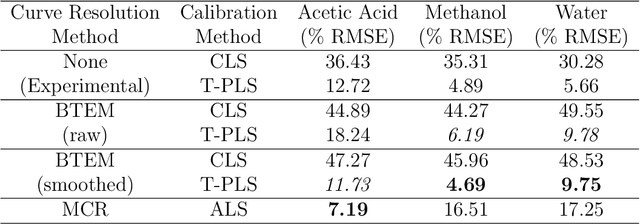
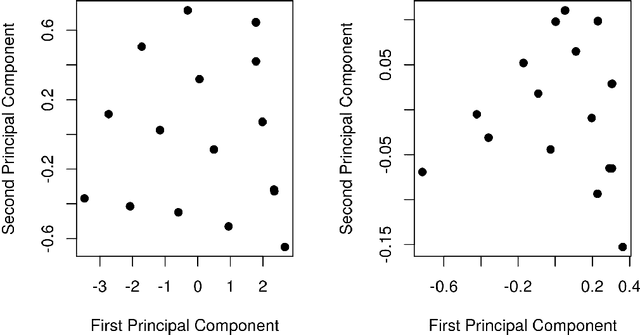
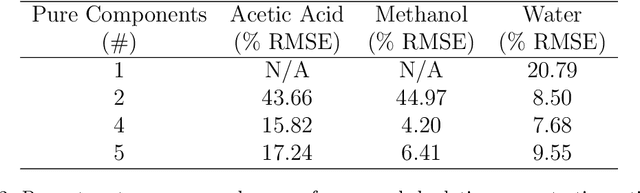
The resolution and calibration of pure spectra of minority components in measurements of chemical mixtures without prior knowledge of the mixture is a challenging problem. In this work, a combination of band target entropy minimization (BTEM) and target partial least squares (T-PLS) was used to obtain estimates for single pure component spectra and to calibrate those estimates in a true, one-at-a-time fashion. This approach allows for minor components to be targeted and their relative amounts estimated in the presence of other varying components in spectral data. The use of T-PLS estimation is an improvement to the BTEM method because it overcomes the need to identify all of the pure components prior to estimation. Estimated amounts from this combination were found to be similar to those obtained from a standard method, multivariate curve resolution-alternating least squares (MCR-ALS), on a simple, three component mixture dataset. Studies from two experimental datasets demonstrate where the combination of BTEM and T-PLS could model the pure component spectra and obtain concentration profiles of minor components but MCR-ALS could not.
Small Moving Window Calibration Models for Soft Sensing Processes with Limited History
Mar 13, 2018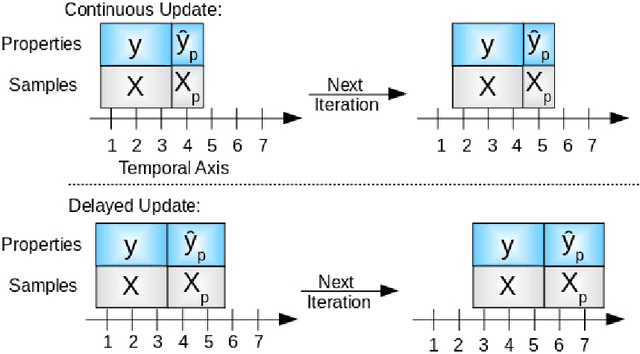
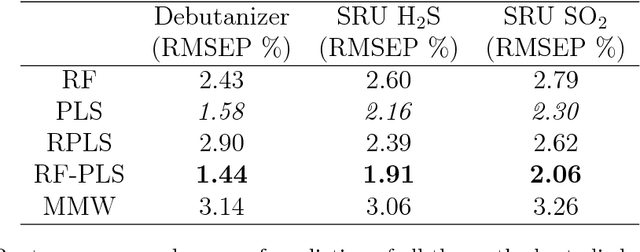
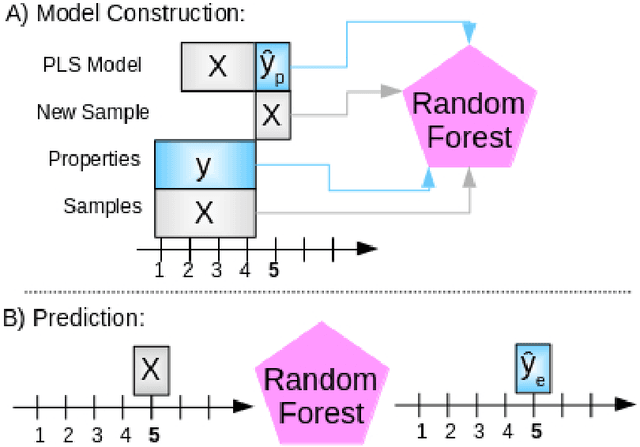

Five simple soft sensor methodologies with two update conditions were compared on two experimentally-obtained datasets and one simulated dataset. The soft sensors investigated were moving window partial least squares regression (and a recursive variant), moving window random forest regression, the mean moving window of $y$, and a novel random forest partial least squares regression ensemble (RF-PLS), all of which can be used with small sample sizes so that they can be rapidly placed online. It was found that, on two of the datasets studied, small window sizes led to the lowest prediction errors for all of the moving window methods studied. On the majority of datasets studied, the RF-PLS calibration method offered the lowest one-step-ahead prediction errors compared to those of the other methods, and it demonstrated greater predictive stability at larger time delays than moving window PLS alone. It was found that both the random forest and RF-PLS methods most adequately modeled the datasets that did not feature purely monotonic increases in property values, but that both methods performed more poorly than moving window PLS models on one dataset with purely monotonic property values. Other data dependent findings are presented and discussed.
Robust Particle Swarm Optimizer based on Chemomimicry
Feb 12, 2018
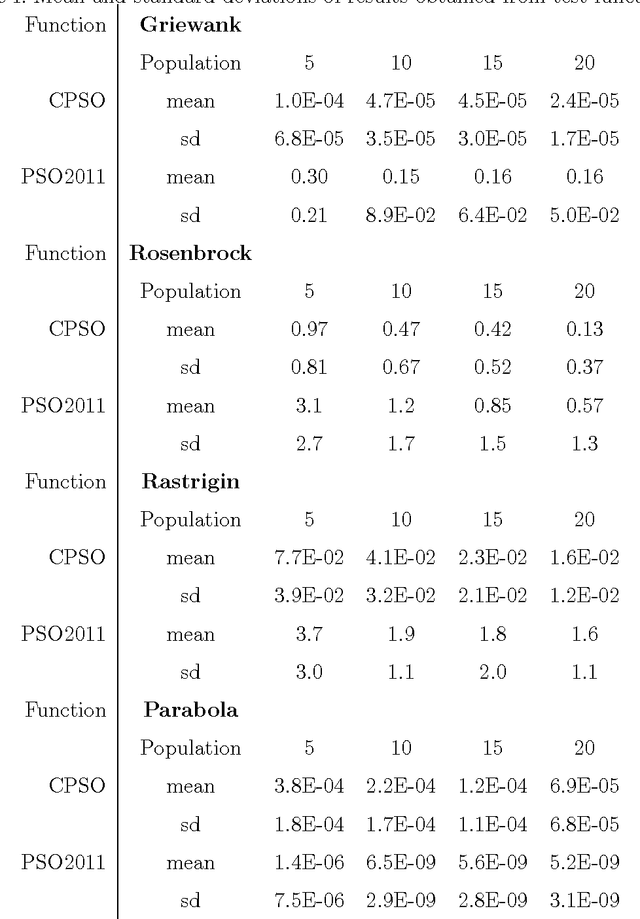
A particle swarm optimizer (PSO) loosely based on the phenomena of crystallization and a chaos factor which follows the complimentary error function is described. The method features three phases: diffusion, directed motion, and nucleation. During the diffusion phase random walk is the only contributor to particle motion. As the algorithm progresses the contribution from chaos decreases and movement toward global best locations is pursued until convergence has occurred. The algorithm was found to be more robust to local minima in multimodal test functions than a standard PSO algorithm and is designed for problems which feature experimental precision.
Optimized Spatial Partitioning via Minimal Swarm Intelligence
Jan 19, 2017



Optimized spatial partitioning algorithms are the corner stone of many successful experimental designs and statistical methods. Of these algorithms, the Centroidal Voronoi Tessellation (CVT) is the most widely utilized. CVT based methods require global knowledge of spatial boundaries, do not readily allow for weighted regions, have challenging implementations, and are inefficiently extended to high dimensional spaces. We describe two simple partitioning schemes based on nearest and next nearest neighbor locations which easily incorporate these features at the slight expense of optimal placement. Several novel qualitative techniques which assess these partitioning schemes are also included. The feasibility of autonomous uninformed sensor networks utilizing these algorithms are considered. Some improvements in particle swarm optimizer results on multimodal test functions from partitioned initial positions in two space are also illustrated. Pseudo code for all of the novel algorithms depicted here-in is available in the supplementary information of this manuscript.