 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Noise, Same Certificate: Retain Sensitivity for Unlearning
Mar 03, 2026Certified machine unlearning aims to provably remove the influence of a deletion set $U$ from a model trained on a dataset $S$, by producing an unlearned output that is statistically indistinguishable from retraining on the retain set $R:=S\setminus U$. Many existing certified unlearning methods adapt techniques from Differential Privacy (DP) and add noise calibrated to global sensitivity, i.e., the worst-case output change over all adjacent datasets. We show that this DP-style calibration is often overly conservative for unlearning, based on a key observation: certified unlearning, by definition, does not require protecting the privacy of the retained data $R$. Motivated by this distinction, we define retain sensitivity as the worst-case output change over deletions $U$ while keeping $R$ fixed. While insufficient for DP, retain sensitivity is exactly sufficient for unlearning, allowing for the same certificates with less noise. We validate these reductions in noise theoretically and empirically across several problems, including the weight of minimum spanning trees, PCA, and ERM. Finally, we refine the analysis of two widely used certified unlearning algorithms through the lens of retain sensitivity, leveraging the regularity induced by $R$ to further reduce noise and improve utility.
Adversarial Resilience against Clean-Label Attacks in Realizable and Noisy Settings
Apr 17, 2025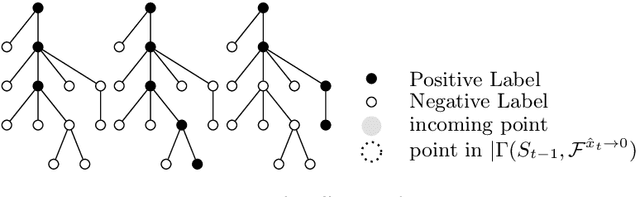
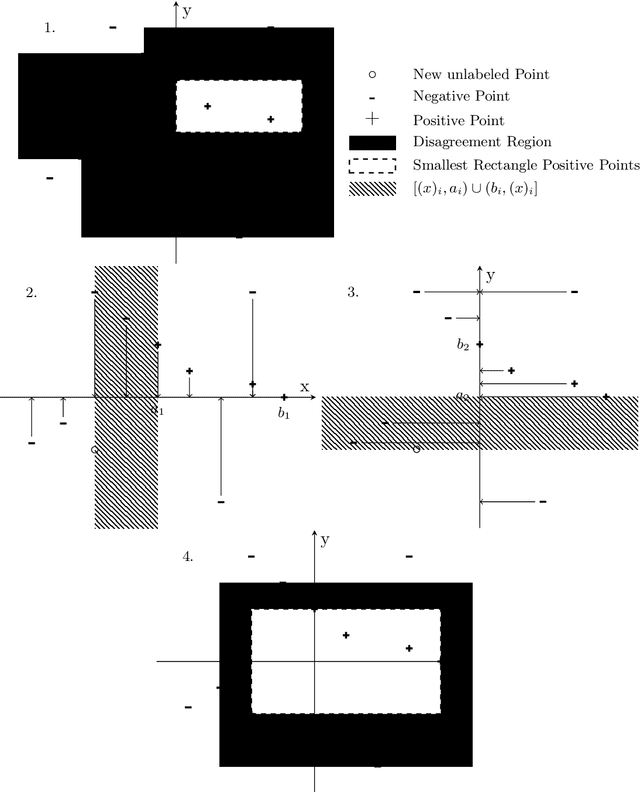
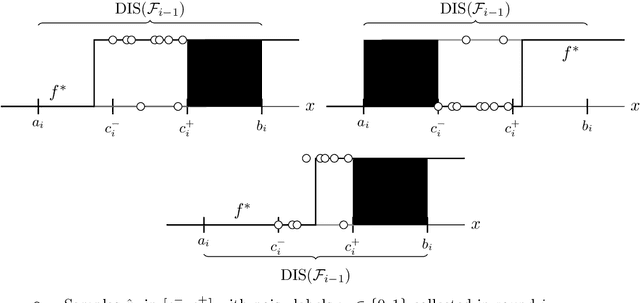
We investigate the challenge of establishing stochastic-like guarantees when sequentially learning from a stream of i.i.d. data that includes an unknown quantity of clean-label adversarial samples. We permit the learner to abstain from making predictions when uncertain. The regret of the learner is measured in terms of misclassification and abstention error, where we allow the learner to abstain for free on adversarial injected samples. This approach is based on the work of Goel, Hanneke, Moran, and Shetty from arXiv:2306.13119. We explore the methods they present and manage to correct inaccuracies in their argumentation. However, this approach is limited to the realizable setting, where labels are assigned according to some function $f^*$ from the hypothesis space $\mathcal{F}$. Based on similar arguments, we explore methods to make adaptations for the agnostic setting where labels are random. Introducing the notion of a clean-label adversary in the agnostic context, we are the first to give a theoretical analysis of a disagreement-based learner for thresholds, subject to a clean-label adversary with noise.