 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualFlexKAN: Dual-stage Kolmogorov-Arnold Networks with Independent Function Control
Mar 09, 2026Multi-Layer Perceptrons (MLPs) rely on pre-defined, fixed activation functions, imposing a static inductive bias that forces the network to approximate complex topologies solely through increased depth and width. Kolmogorov-Arnold Networks (KANs) address this limitation through edge-centric learnable functions, yet their formulation suffers from quadratic parameter scaling and architectural rigidity that hinders the effective integration of standard regularization techniques. This paper introduces the DualFlexKAN (DFKAN), a flexible architecture featuring a dual-stage mechanism that independently controls pre-linear input transformations and post-linear output activations. This decoupling enables hybrid networks that optimize the trade-off between expressiveness and computational cost. Unlike standard formulations, DFKAN supports diverse basis function families, including orthogonal polynomials, B-splines, and radial basis functions, integrated with configurable regularization strategies that stabilize training dynamics. Comprehensive evaluations across regression benchmarks, physics-informed tasks, and function approximation demonstrate that DFKAN outperforms both MLPs and conventional KANs in accuracy, convergence speed, and gradient fidelity. The proposed hybrid configurations achieve superior performance with one to two orders of magnitude fewer parameters than standard KANs, effectively mitigating the parameter explosion problem while preserving KAN-style expressiveness. DFKAN provides a principled, scalable framework for incorporating adaptive non-linearities, proving particularly advantageous for data-efficient learning and interpretable function discovery in scientific applications.
Deep Learning in current Neuroimaging: a multivariate approach with power and type I error control but arguable generalization ability
Mar 30, 2021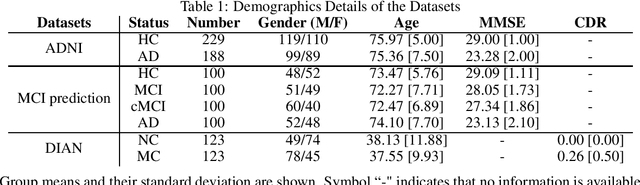
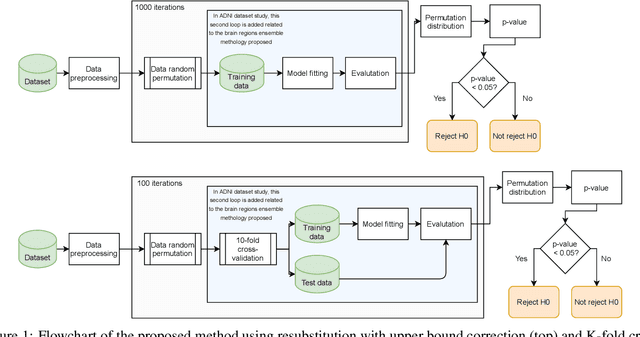
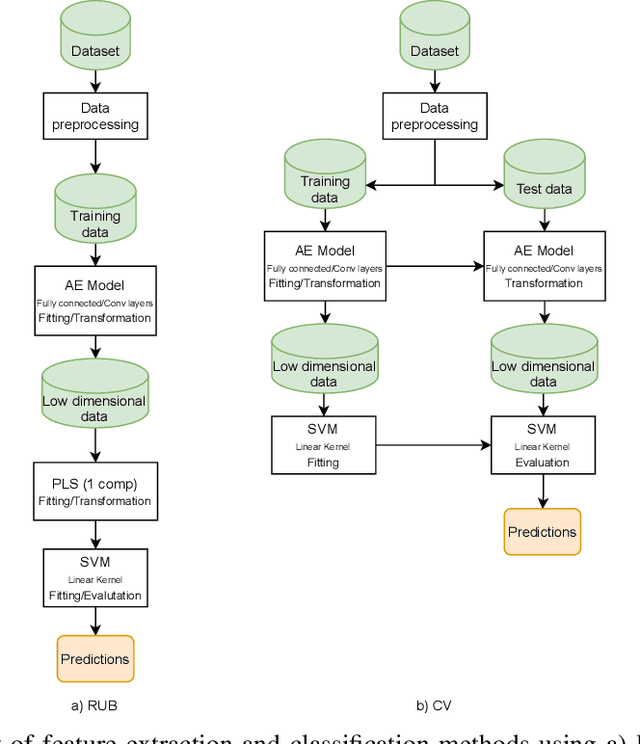
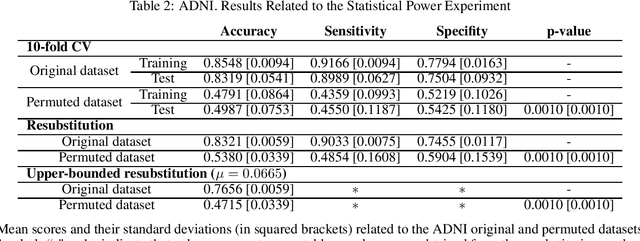
Discriminative analysis in neuroimaging by means of deep/machine learning techniques is usually tested with validation techniques, whereas the associated statistical significance remains largely under-developed due to their computational complexity. In this work, a non-parametric framework is proposed that estimates the statistical significance of classifications using deep learning architectures. In particular, a combination of autoencoders (AE) and support vector machines (SVM) is applied to: (i) a one-condition, within-group designs often of normal controls (NC) and; (ii) a two-condition, between-group designs which contrast, for example, Alzheimer's disease (AD) patients with NC (the extension to multi-class analyses is also included). A random-effects inference based on a label permutation test is proposed in both studies using cross-validation (CV) and resubstitution with upper bound correction (RUB) as validation methods. This allows both false positives and classifier overfitting to be detected as well as estimating the statistical power of the test. Several experiments were carried out using the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, the Dominantly Inherited Alzheimer Network (DIAN) dataset, and a MCI prediction dataset. We found in the permutation test that CV and RUB methods offer a false positive rate close to the significance level and an acceptable statistical power (although lower using cross-validation). A large separation between training and test accuracies using CV was observed, especially in one-condition designs. This implies a low generalization ability as the model fitted in training is not informative with respect to the test set. We propose as solution by applying RUB, whereby similar results are obtained to those of the CV test set, but considering the whole set and with a lower computational cost per iteration.