 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Language Acquisition
Nov 12, 1996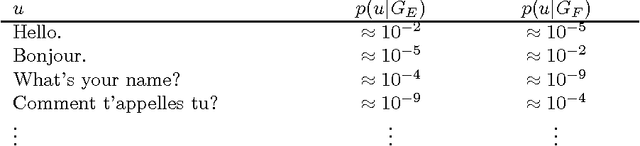
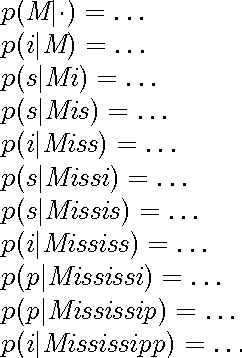
This thesis presents a computational theory of unsupervised language acquisition, precisely defining procedures for learning language from ordinary spoken or written utterances, with no explicit help from a teacher. The theory is based heavily on concepts borrowed from machine learning and statistical estimation. In particular, learning takes place by fitting a stochastic, generative model of language to the evidence. Much of the thesis is devoted to explaining conditions that must hold for this general learning strategy to arrive at linguistically desirable grammars. The thesis introduces a variety of technical innovations, among them a common representation for evidence and grammars, and a learning strategy that separates the ``content'' of linguistic parameters from their representation. Algorithms based on it suffer from few of the search problems that have plagued other computational approaches to language acquisition. The theory has been tested on problems of learning vocabularies and grammars from unsegmented text and continuous speech, and mappings between sound and representations of meaning. It performs extremely well on various objective criteria, acquiring knowledge that causes it to assign almost exactly the same structure to utterances as humans do. This work has application to data compression, language modeling, speech recognition, machine translation, information retrieval, and other tasks that rely on either structural or stochastic descriptions of language.
Linguistic Structure as Composition and Perturbation
Jun 21, 1996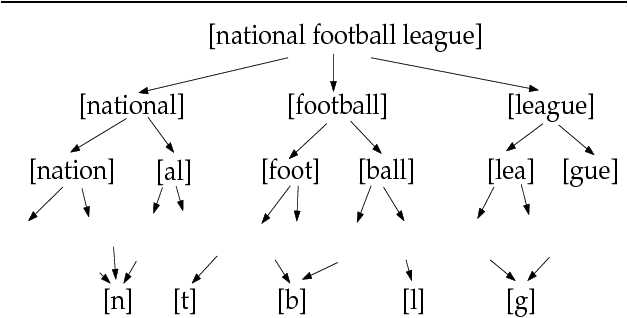



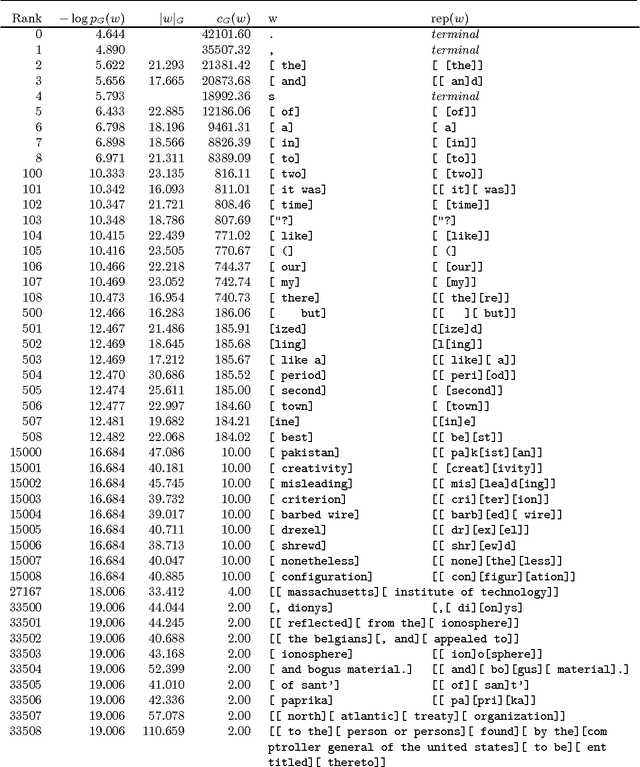
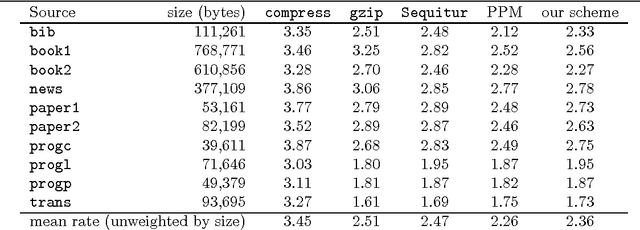
This paper discusses the problem of learning language from unprocessed text and speech signals, concentrating on the problem of learning a lexicon. In particular, it argues for a representation of language in which linguistic parameters like words are built by perturbing a composition of existing parameters. The power of this representation is demonstrated by several examples in text segmentation and compression, acquisition of a lexicon from raw speech, and the acquisition of mappings between text and artificial representations of meaning.
The Unsupervised Acquisition of a Lexicon from Continuous Speech
Dec 13, 1995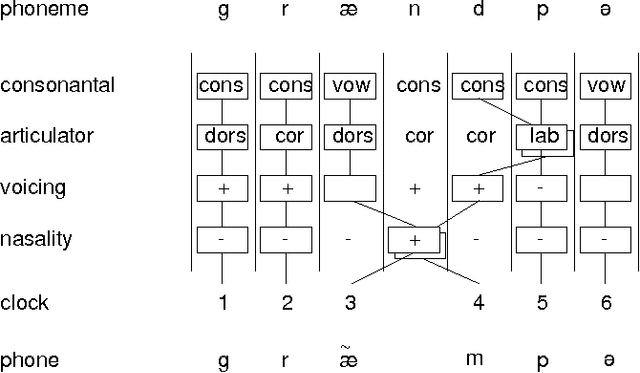


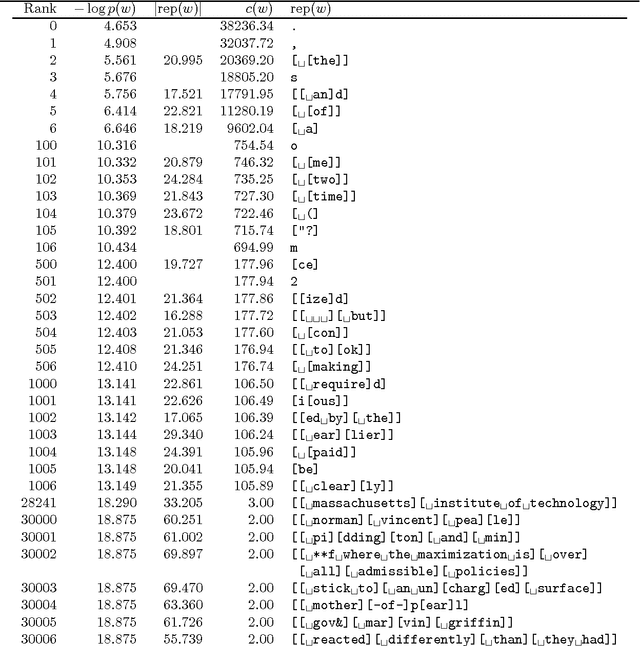
We present an unsupervised learning algorithm that acquires a natural-language lexicon from raw speech. The algorithm is based on the optimal encoding of symbol sequences in an MDL framework, and uses a hierarchical representation of language that overcomes many of the problems that have stymied previous grammar-induction procedures. The forward mapping from symbol sequences to the speech stream is modeled using features based on articulatory gestures. We present results on the acquisition of lexicons and language models from raw speech, text, and phonetic transcripts, and demonstrate that our algorithm compares very favorably to other reported results with respect to segmentation performance and statistical efficiency.
Acquiring a Lexicon from Unsegmented Speech
May 08, 1995
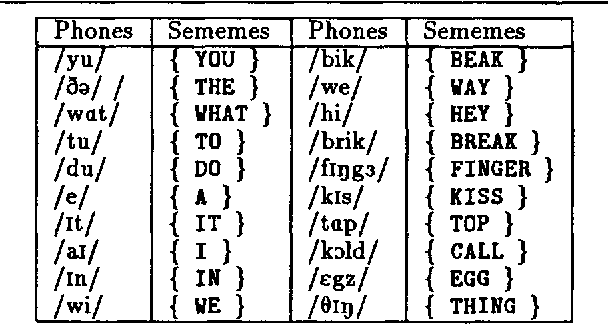

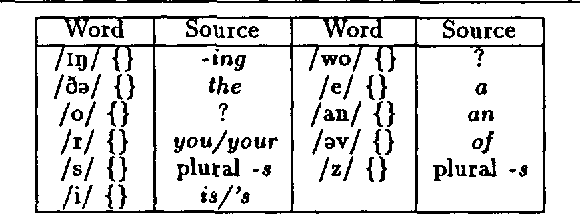
We present work-in-progress on the machine acquisition of a lexicon from sentences that are each an unsegmented phone sequence paired with a primitive representation of meaning. A simple exploratory algorithm is described, along with the direction of current work and a discussion of the relevance of the problem for child language acquisition and computer speech recognition.
The Acquisition of a Lexicon from Paired Phoneme Sequences and Semantic Representations
Jul 15, 1994We present an algorithm that acquires words (pairings of phonological forms and semantic representations) from larger utterances of unsegmented phoneme sequences and semantic representations. The algorithm maintains from utterance to utterance only a single coherent dictionary, and learns in the presence of homonymy, synonymy, and noise. Test results over a corpus of utterances generated from the Childes database of mother-child interactions are presented.