 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Statistics and False Belief Reasoning: Evidence from 41 Open-Weight LMs
Feb 17, 2026Research on mental state reasoning in language models (LMs) has the potential to inform theories of human social cognition--such as the theory that mental state reasoning emerges in part from language exposure--and our understanding of LMs themselves. Yet much published work on LMs relies on a relatively small sample of closed-source LMs, limiting our ability to rigorously test psychological theories and evaluate LM capacities. Here, we replicate and extend published work on the false belief task by assessing LM mental state reasoning behavior across 41 open-weight models (from distinct model families). We find sensitivity to implied knowledge states in 34% of the LMs tested; however, consistent with prior work, none fully ``explain away'' the effect in humans. Larger LMs show increased sensitivity and also exhibit higher psychometric predictive power. Finally, we use LM behavior to generate and test a novel hypothesis about human cognition: both humans and LMs show a bias towards attributing false beliefs when knowledge states are cued using a non-factive verb (``John thinks...'') than when cued indirectly (``John looks in the...''). Unlike the primary effect of knowledge states, where human sensitivity exceeds that of LMs, the magnitude of the human knowledge cue effect falls squarely within the distribution of LM effect sizes-suggesting that distributional statistics of language can in principle account for the latter but not the former in humans. These results demonstrate the value of using larger samples of open-weight LMs to test theories of human cognition and evaluate LM capacities.
Does GPT-4 Pass the Turing Test?
Oct 31, 2023We evaluated GPT-4 in a public online Turing Test. The best-performing GPT-4 prompt passed in 41% of games, outperforming baselines set by ELIZA (27%) and GPT-3.5 (14%), but falling short of chance and the baseline set by human participants (63%). Participants' decisions were based mainly on linguistic style (35%) and socio-emotional traits (27%), supporting the idea that intelligence is not sufficient to pass the Turing Test. Participants' demographics, including education and familiarity with LLMs, did not predict detection rate, suggesting that even those who understand systems deeply and interact with them frequently may be susceptible to deception. Despite known limitations as a test of intelligence, we argue that the Turing Test continues to be relevant as an assessment of naturalistic communication and deception. AI models with the ability to masquerade as humans could have widespread societal consequences, and we analyse the effectiveness of different strategies and criteria for judging humanlikeness.
Do Large Language Models know what humans know?
Sep 04, 2022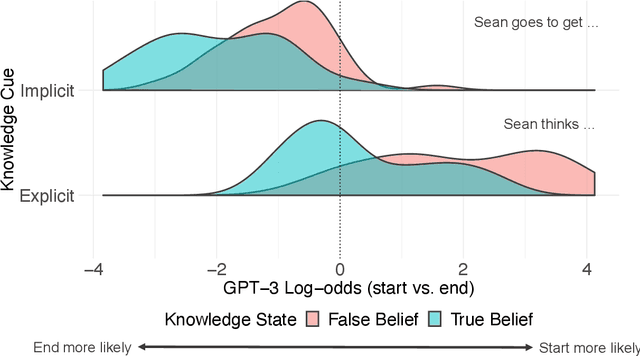
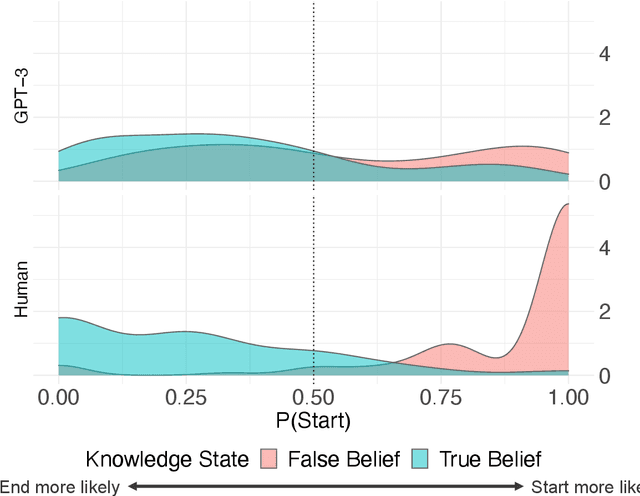
Humans can attribute mental states to others, a capacity known as Theory of Mind. However, it is unknown to what extent this ability results from an innate biological endowment or from experience accrued through child development, particularly exposure to language describing others' mental states. We test the viability of the language exposure hypothesis by assessing whether models exposed to large quantities of human language develop evidence of Theory of Mind. In a pre-registered analysis, we present a linguistic version of the False Belief Task, widely used to assess Theory of Mind, to both human participants and a state-of-the-art Large Language Model, GPT-3. Both are sensitive to others' beliefs, but the language model does not perform as well as the humans, nor does it explain the full extent of their behavior, despite being exposed to more language than a human would in a lifetime. This suggests that while language exposure may in part explain how humans develop Theory of Mind, other mechanisms are also responsible.