 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Word Recognition using Multiple Hypotheses and Deep Embeddings
Oct 27, 2020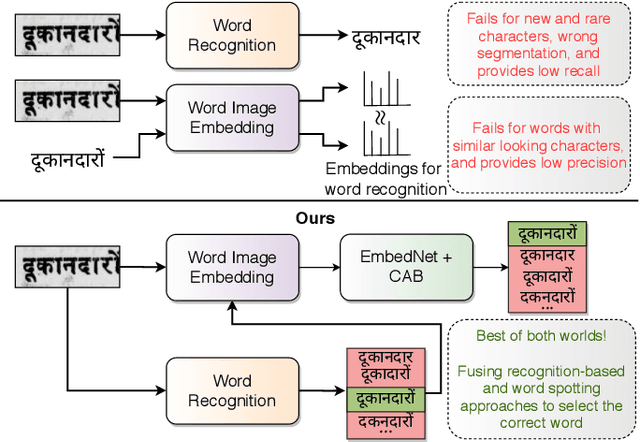
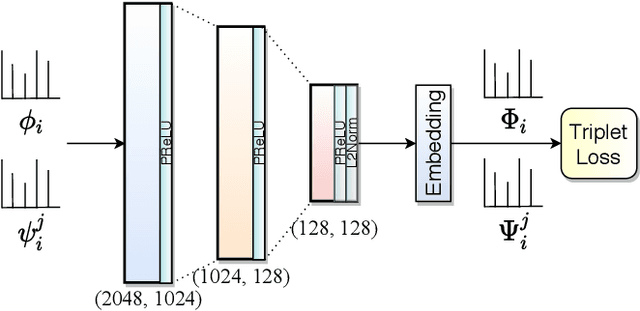
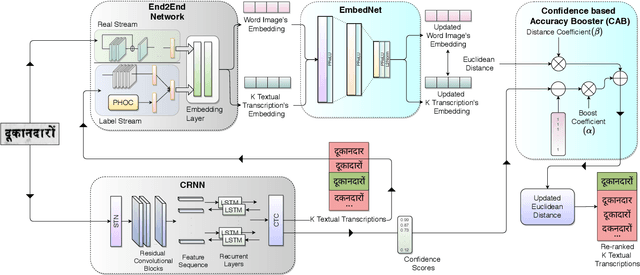
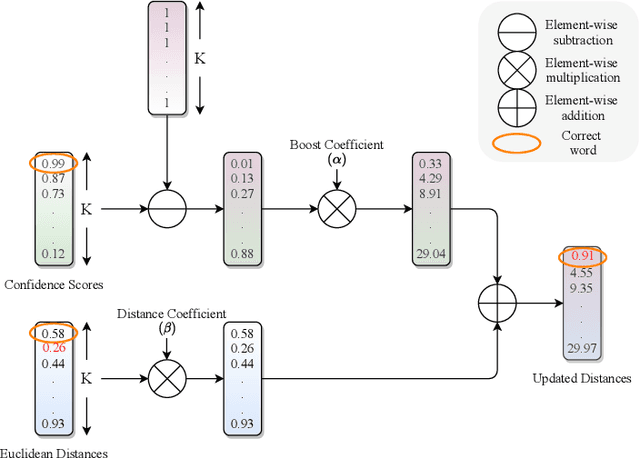
We propose a novel scheme for improving the word recognition accuracy using word image embeddings. We use a trained text recognizer, which can predict multiple text hypothesis for a given word image. Our fusion scheme improves the recognition process by utilizing the word image and text embeddings obtained from a trained word image embedding network. We propose EmbedNet, which is trained using a triplet loss for learning a suitable embedding space where the embedding of the word image lies closer to the embedding of the corresponding text transcription. The updated embedding space thus helps in choosing the correct prediction with higher confidence. To further improve the accuracy, we propose a plug-and-play module called Confidence based Accuracy Booster (CAB). The CAB module takes in the confidence scores obtained from the text recognizer and Euclidean distances between the embeddings to generate an updated distance vector. The updated distance vector has lower distance values for the correct words and higher distance values for the incorrect words. We rigorously evaluate our proposed method systematically on a collection of books in the Hindi language. Our method achieves an absolute improvement of around 10 percent in terms of word recognition accuracy.
Table Structure Recognition using Top-Down and Bottom-Up Cues
Oct 09, 2020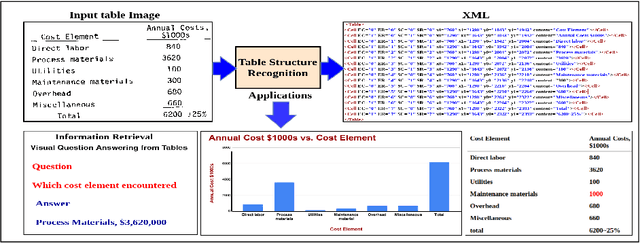

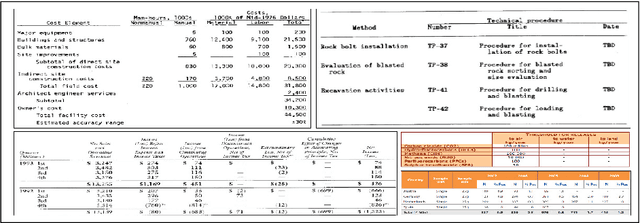
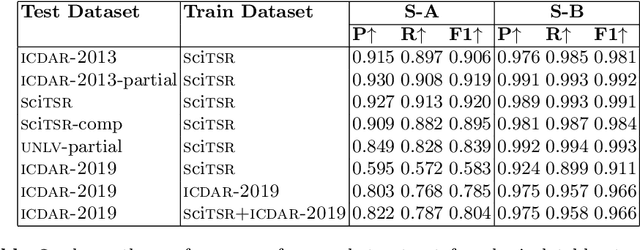
Tables are information-rich structured objects in document images. While significant work has been done in localizing tables as graphic objects in document images, only limited attempts exist on table structure recognition. Most existing literature on structure recognition depends on extraction of meta-features from the PDF document or on the optical character recognition (OCR) models to extract low-level layout features from the image. However, these methods fail to generalize well because of the absence of meta-features or errors made by the OCR when there is a significant variance in table layouts and text organization. In our work, we focus on tables that have complex structures, dense content, and varying layouts with no dependency on meta-features and/or OCR. We present an approach for table structure recognition that combines cell detection and interaction modules to localize the cells and predict their row and column associations with other detected cells. We incorporate structural constraints as additional differential components to the loss function for cell detection. We empirically validate our method on the publicly available real-world datasets - ICDAR-2013, ICDAR-2019 (cTDaR) archival, UNLV, SciTSR, SciTSR-COMP, TableBank, and PubTabNet. Our attempt opens up a new direction for table structure recognition by combining top-down (table cells detection) and bottom-up (structure recognition) cues in visually understanding the tables.
Graphical Object Detection in Document Images
Aug 25, 2020
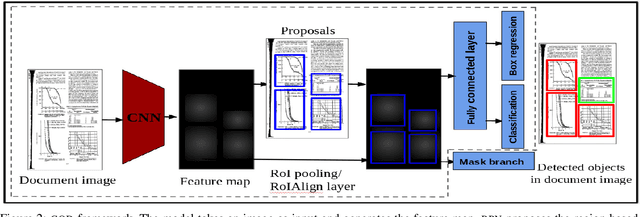


Graphical elements: particularly tables and figures contain a visual summary of the most valuable information contained in a document. Therefore, localization of such graphical objects in the document images is the initial step to understand the content of such graphical objects or document images. In this paper, we present a novel end-to-end trainable deep learning based framework to localize graphical objects in the document images called as Graphical Object Detection (GOD). Our framework is data-driven and does not require any heuristics or meta-data to locate graphical objects in the document images. The GOD explores the concept of transfer learning and domain adaptation to handle scarcity of labeled training images for graphical object detection task in the document images. Performance analysis carried out on the various public benchmark data sets: ICDAR-2013, ICDAR-POD2017,and UNLV shows that our model yields promising results as compared to state-of-the-art techniques.
* 8
CDeC-Net: Composite Deformable Cascade Network for Table Detection in Document Images
Aug 25, 2020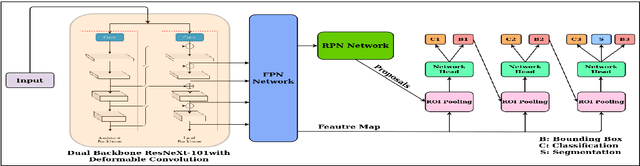
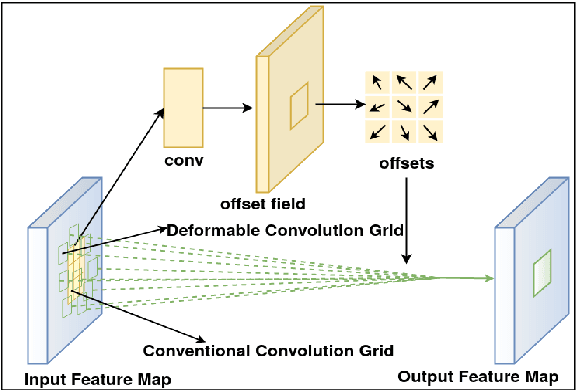

Localizing page elements/objects such as tables, figures, equations, etc. is the primary step in extracting information from document images. We propose a novel end-to-end trainable deep network, (CDeC-Net) for detecting tables present in the documents. The proposed network consists of a multistage extension of Mask R-CNN with a dual backbone having deformable convolution for detecting tables varying in scale with high detection accuracy at higher IoU threshold. We empirically evaluate CDeC-Net on all the publicly available benchmark datasets - ICDAR-2013, ICDAR-2017, ICDAR-2019,UNLV, Marmot, PubLayNet, and TableBank - with extensive experiments. Our solution has three important properties: (i) a single trained model CDeC-Net{\ddag} performs well across all the popular benchmark datasets; (ii) we report excellent performances across multiple, including higher, thresholds of IoU; (iii) by following the same protocol of the recent papers for each of the benchmarks, we consistently demonstrate the superior quantitative performance. Our code and models will be publicly released for enabling the reproducibility of the results.
Document Visual Question Answering Challenge 2020
Aug 20, 2020
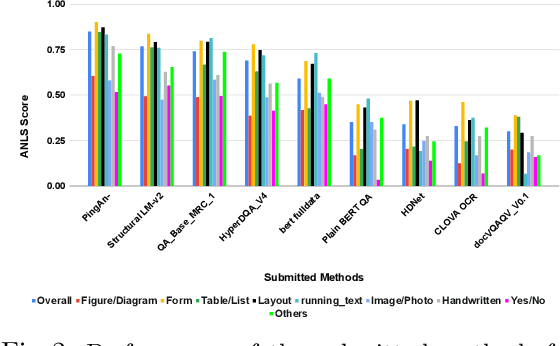
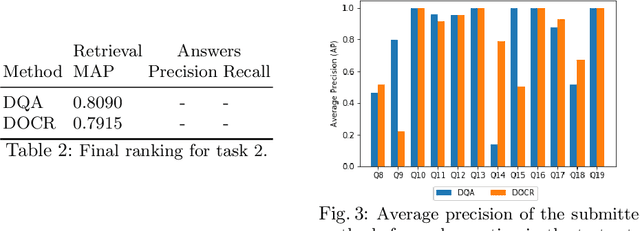
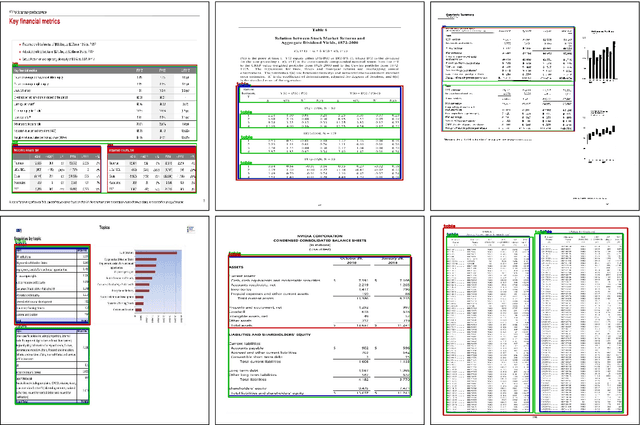
This paper presents results of Document Visual Question Answering Challenge organized as part of "Text and Documents in the Deep Learning Era" workshop, in CVPR 2020. The challenge introduces a new problem - Visual Question Answering on document images. The challenge comprised two tasks. The first task concerns with asking questions on a single document image. On the other hand, the second task is set as a retrieval task where the question is posed over a collection of images. For the task 1 a new dataset is introduced comprising 50,000 questions-answer(s) pairs defined over 12,767 document images. For task 2 another dataset has been created comprising 20 questions over 14,362 document images which share the same document template.
Revisiting Low Resource Status of Indian Languages in Machine Translation
Aug 11, 2020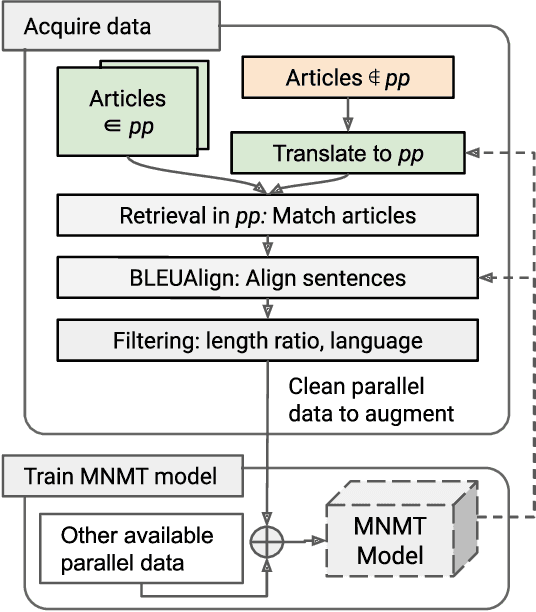
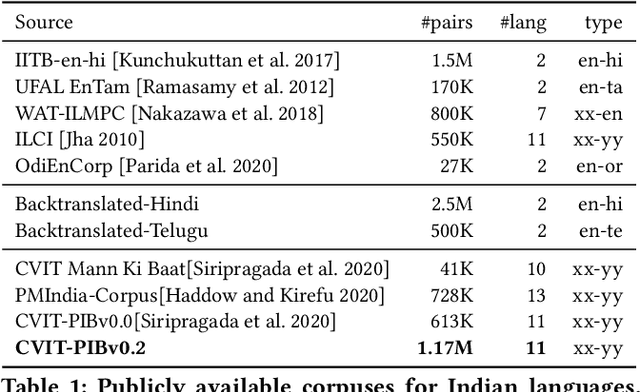
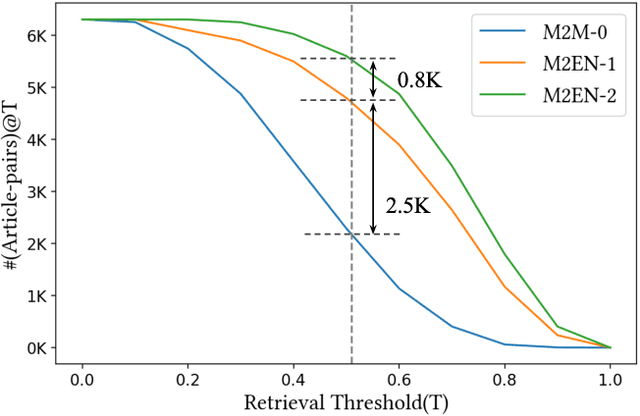
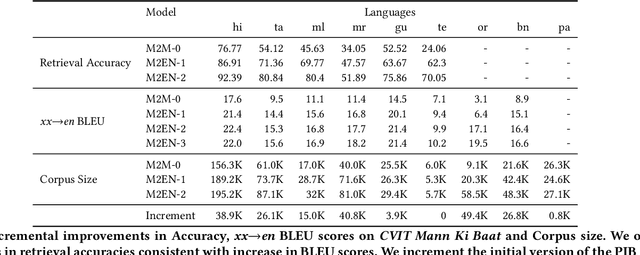
Indian language machine translation performance is hampered due to the lack of large scale multi-lingual sentence aligned corpora and robust benchmarks. Through this paper, we provide and analyse an automated framework to obtain such a corpus for Indian language neural machine translation (NMT) systems. Our pipeline consists of a baseline NMT system, a retrieval module, and an alignment module that is used to work with publicly available websites such as press releases by the government. The main contribution towards this effort is to obtain an incremental method that uses the above pipeline to iteratively improve the size of the corpus as well as improve each of the components of our system. Through our work, we also evaluate the design choices such as the choice of pivoting language and the effect of iterative incremental increase in corpus size. Our work in addition to providing an automated framework also results in generating a relatively larger corpus as compared to existing corpora that are available for Indian languages. This corpus helps us obtain substantially improved results on the publicly available WAT evaluation benchmark and other standard evaluation benchmarks.
Textual Description for Mathematical Equations
Aug 07, 2020
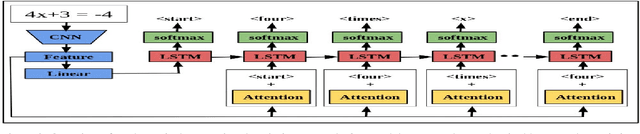


Reading of mathematical expression or equation in the document images is very challenging due to the large variability of mathematical symbols and expressions. In this paper, we pose reading of mathematical equation as a task of generation of the textual description which interprets the internal meaning of this equation. Inspired by the natural image captioning problem in computer vision, we present a mathematical equation description (MED) model, a novel end-to-end trainable deep neural network based approach that learns to generate a textual description for reading mathematical equation images. Our MED model consists of a convolution neural network as an encoder that extracts features of input mathematical equation images and a recurrent neural network with attention mechanism which generates description related to the input mathematical equation images. Due to the unavailability of mathematical equation image data sets with their textual descriptions, we generate two data sets for experimental purpose. To validate the effectiveness of our MED model, we conduct a real-world experiment to see whether the students are able to write equations by only reading or listening their textual descriptions or not. Experiments conclude that the students are able to write most of the equations correctly by reading their textual descriptions only.
* 8
IIIT-AR-13K: A New Dataset for Graphical Object Detection in Documents
Aug 06, 2020
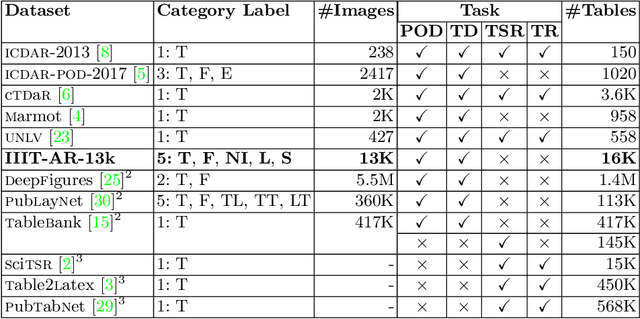

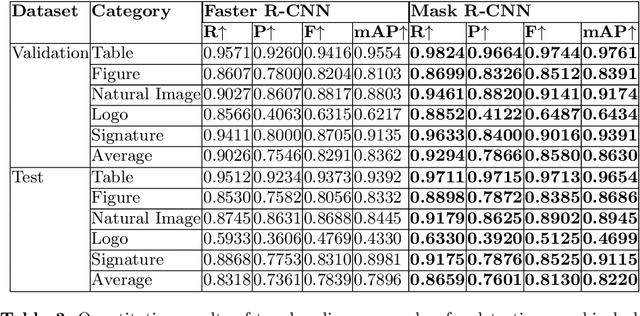
We introduce a new dataset for graphical object detection in business documents, more specifically annual reports. This dataset, IIIT-AR-13k, is created by manually annotating the bounding boxes of graphical or page objects in publicly available annual reports. This dataset contains a total of 13k annotated page images with objects in five different popular categories - table, figure, natural image, logo, and signature. It is the largest manually annotated dataset for graphical object detection. Annual reports created in multiple languages for several years from various companies bring high diversity into this dataset. We benchmark IIIT-AR-13K dataset with two state of the art graphical object detection techniques using Faster R-CNN [20] and Mask R-CNN [11] and establish high baselines for further research. Our dataset is highly effective as training data for developing practical solutions for graphical object detection in both business documents and technical articles. By training with IIIT-AR-13K, we demonstrate the feasibility of a single solution that can report superior performance compared to the equivalent ones trained with a much larger amount of data, for table detection. We hope that our dataset helps in advancing the research for detecting various types of graphical objects in business documents.
* 15 pages, DAS 2020
Weakly Supervised Instance Segmentation by Learning Annotation Consistent Instances
Jul 18, 2020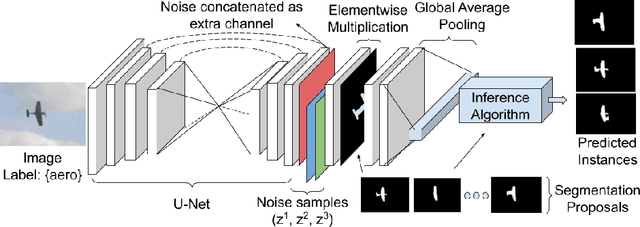
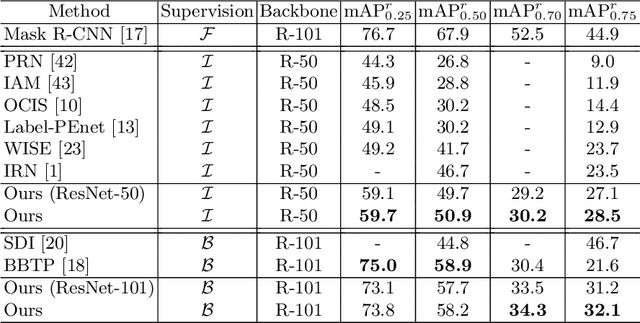


Recent approaches for weakly supervised instance segmentations depend on two components: (i) a pseudo label generation model that provides instances which are consistent with a given annotation; and (ii) an instance segmentation model, which is trained in a supervised manner using the pseudo labels as ground-truth. Unlike previous approaches, we explicitly model the uncertainty in the pseudo label generation process using a conditional distribution. The samples drawn from our conditional distribution provide accurate pseudo labels due to the use of semantic class aware unary terms, boundary aware pairwise smoothness terms, and annotation aware higher order terms. Furthermore, we represent the instance segmentation model as an annotation agnostic prediction distribution. In contrast to previous methods, our representation allows us to define a joint probabilistic learning objective that minimizes the dissimilarity between the two distributions. Our approach achieves state of the art results on the PASCAL VOC 2012 data set, outperforming the best baseline by 4.2% mAP@0.5 and 4.8% mAP@0.75.
DocVQA: A Dataset for VQA on Document Images
Jul 01, 2020
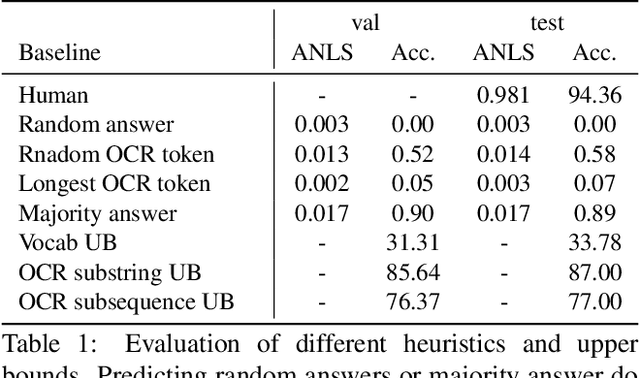

We present a new dataset for Visual Question Answering on document images called DocVQA. The dataset consistsof 50,000 questions defined on 12,000+ document images. We provide detailed analysis of the dataset in comparison with similar datasets for VQA and reading comprehension. We report several baseline results by adopting existing VQA and reading comprehension models. Although the existing models perform reasonably well on certain types of questions, there is large performance gap compared to human performance (94.36% accuracy). The models need to improve specifically on questions where understanding structure of the document is crucial.