 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Framework to Leverage State-Of-The-Art Single-Image Super-Resolution Methods to Restore Light Fields
Sep 27, 2018

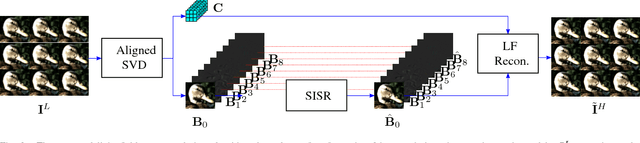
Plenoptic cameras offer a cost effective solution to capture light fields by multiplexing multiple views on a single image sensor. However, the high angular resolution is achieved at the expense of reducing the spatial resolution of each view by orders of magnitude compared to the raw sensor image. While light field super-resolution is still at an early stage, the field of single image super-resolution (SISR) has recently known significant advances with the use of deep learning techniques. This paper describes a simple framework allowing us to leverage state-of-the-art SISR techniques into light fields, while taking into account specific light field geometrical constraints. The idea is to first compute a representation compacting most of the light field energy into as few components as possible. This is achieved by aligning the light field using optical flows and then by decomposing the aligned light field using singular value decomposition (SVD). The principal basis captures the information that is coherent across all the views, while the other basis contain the high angular frequencies. Super-resolving this principal basis using an SISR method allows us to super-resolve all the information that is coherent across the entire light field. This framework allows the proposed light field super-resolution method to inherit the benefits of the SISR method used. Experimental results show that the proposed method is competitive, and most of the time superior, to recent light field super-resolution methods in terms of both PSNR and SSIM quality metrics, with a lower complexity.
Partial light field tomographic reconstruction from a fixed-camera focal stack
Mar 06, 2015



This paper describes a novel approach to partially reconstruct high-resolution 4D light fields from a stack of differently focused photographs taken with a fixed camera. First, a focus map is calculated from this stack using a simple approach combining gradient detection and region expansion with graph-cut. Then, this focus map is converted into a depth map thanks to the calibration of the camera. We proceed after this with the tomographic reconstruction of the epipolar images by back-projecting the focused regions of the scene only. We call it masked back-projection. The angles of back-projection are calculated from the depth map. Thanks to the high angular resolution we achieve by suitably exploiting the image content captured over a large interval of focus distances, we are able to render puzzling perspective shifts although the original photographs were taken from a single fixed camera at a fixed position.