 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVCACHE: A Stateful Tool-Value Cache for Post-Training LLM Agents
Feb 11, 2026In RL post-training of LLM agents, calls to external tools take several seconds or even minutes, leaving allocated GPUs idle and inflating post-training time and cost. While many tool invocations repeat across parallel rollouts and could in principle be cached, naively caching their outputs for reuse is incorrect since tool outputs depend on the environment state induced by prior agent interactions. We present TVCACHE, a stateful tool-value cache for LLM agent post-training. TVCACHE maintains a tree of observed tool-call sequences and performs longest-prefix matching for cache lookups: a hit occurs only when the agent's full tool history matches a previously executed sequence, guaranteeing identical environment state. On three diverse workloads-terminal-based tasks, SQL generation, and video understanding. TVCACHE achieves cache hit rates of up to 70% and reduces median tool call execution time by up to 6.9X, with no degradation in post-training reward accumulation.
FlashDMoE: Fast Distributed MoE in a Single Kernel
Jun 05, 2025The computational sparsity of Mixture-of-Experts (MoE) models enables sub-linear growth in compute cost as model size increases, offering a scalable path to training massive neural networks. However, existing implementations suffer from \emph{low GPU utilization}, \emph{significant latency overhead}, and a fundamental \emph{inability to leverage task locality}, primarily due to CPU-managed scheduling, host-initiated communication, and frequent kernel launches. To overcome these limitations, we develop FlashDMoE, a fully GPU-resident MoE operator that fuses expert computation and inter-GPU communication into a \emph{single persistent GPU kernel}. FlashDMoE enables fine-grained pipelining of dispatch, compute, and combine phases, eliminating launch overheads and reducing idle gaps. Its device-initiated communication protocol introduces \emph{payload-efficient} data transfers, significantly shrinking buffer sizes in sparsely activated MoE layers. When evaluated on a single 8-H100 GPU node with MoE models having up to 128 experts and 16K token sequences, FlashDMoE achieves up to \textbf{6}x lower latency, \textbf{5,7}x higher throughput, \textbf{4}x better weak scaling efficiency, and \textbf{9}x higher GPU utilization compared to state-of-the-art baselines, despite using FP32 while baselines use FP16. FlashDMoE demonstrates that principled GPU kernel-hardware co-design is key to unlocking the performance ceiling of large-scale distributed ML workloads.
DAPAS : Denoising Autoencoder to Prevent Adversarial attack in Semantic Segmentation
Aug 18, 2019
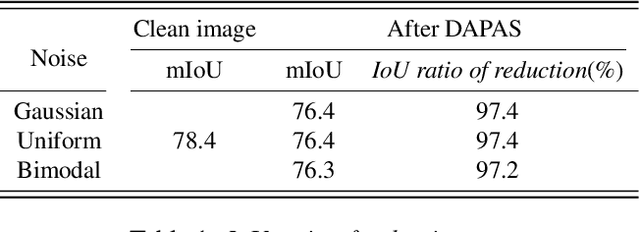
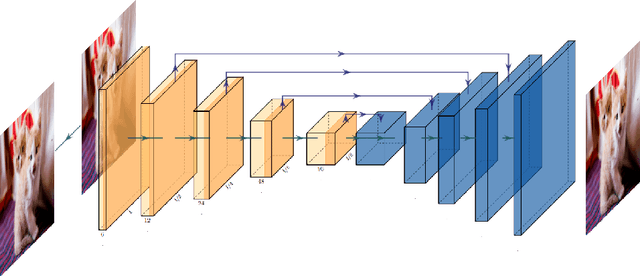
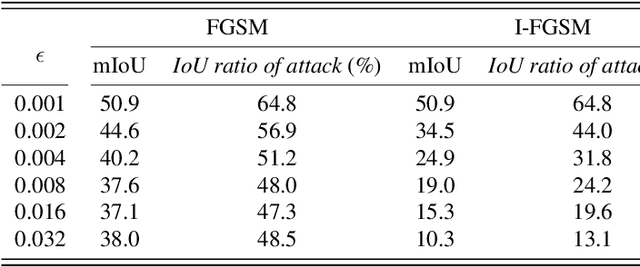
Nowadays, Deep learning techniques show dramatic performance on computer vision area, and they even outperform human. But it is also vulnerable to some small perturbation called an adversarial attack. This is a problem combined with the safety of artificial intelligence, which has recently been studied a lot. These attacks have shown that they can fool models of image classification, semantic segmentation, and object detection. We point out this attack can be protected by denoise autoencoder, which is used for denoising the perturbation and restoring the original images. We experiment with various noise distributions and verify the effect of denoise autoencoder against adversarial attack in semantic segmentation.