 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwriting recognition using Cohort of LSTM and lexicon verification with extremely large lexicon
Sep 25, 2017

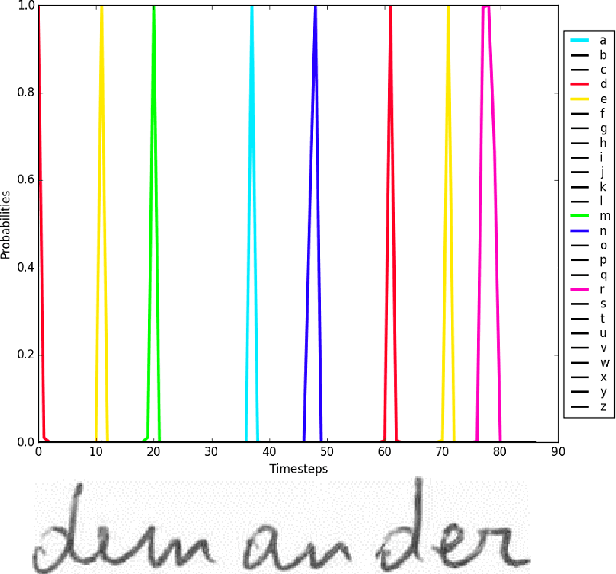
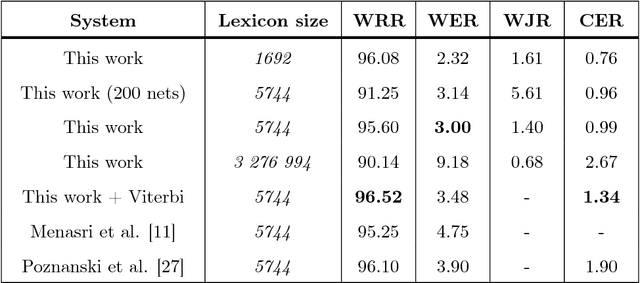
State-of-the-art methods for handwriting recognition are based on Long Short Term Memory (LSTM) recurrent neural networks (RNN), which now provides very impressive character recognition performance. The character recognition is generally coupled with a lexicon driven decoding process which integrates dictionaries. Unfortunately these dictionaries are limited to hundred of thousands words for the best systems, which prevent from having a good language coverage, and therefore limit the global recognition performance. In this article, we propose an alternative to the lexicon driven decoding process based on a lexicon verification process, coupled with an original cascade architecture. The cascade is made of a large number of complementary networks extracted from a single training (called cohort), making the learning process very light. The proposed method achieves new state-of-the art word recognition performance on the Rimes and IAM databases. Dealing with gigantic lexicon of 3 millions words, the methods also demonstrates interesting performance with a fast decision stage.
LV-ROVER: Lexicon Verified Recognizer Output Voting Error Reduction
Jul 24, 2017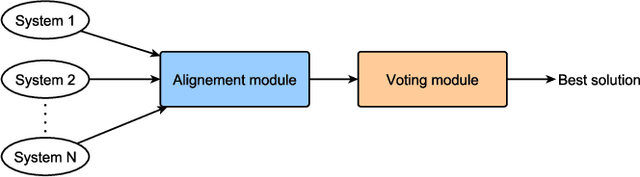
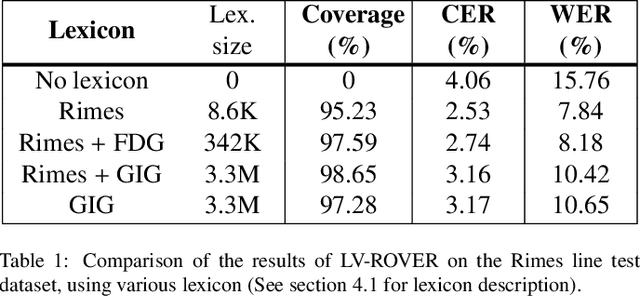
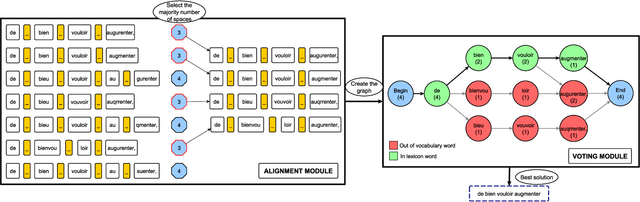
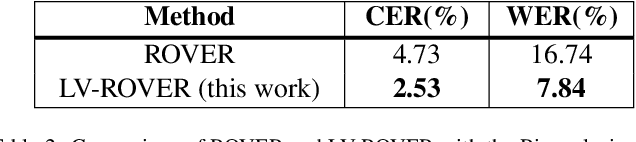
Offline handwritten text line recognition is a hard task that requires both an efficient optical character recognizer and language model. Handwriting recognition state of the art methods are based on Long Short Term Memory (LSTM) recurrent neural networks (RNN) coupled with the use of linguistic knowledge. Most of the proposed approaches in the literature focus on improving one of the two components and use constraint, dedicated to a database lexicon. However, state of the art performance is achieved by combining multiple optical models, and possibly multiple language models with the Recognizer Output Voting Error Reduction (ROVER) framework. Though handwritten line recognition with ROVER has been implemented by combining only few recognizers because training multiple complete recognizers is hard. In this paper we propose a Lexicon Verified ROVER: LV-ROVER, that has a reduce complexity compare to the original one and that can combine hundreds of recognizers without language models. We achieve state of the art for handwritten line text on the RIMES dataset.