 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeflation-Free Optimal Scoring
Apr 28, 2026Sparse Optimal Scoring (SOS) reformulates linear discriminant analysis to enable feature selection through elastic net regularization, making it well-suited for high-dimensional settings where the number of features exceeds observations. Most existing SOS methods use deflation-based strategies that compute discriminant vectors sequentially, which can propagate errors and produce suboptimal solutions. We propose a novel approach that estimates all discriminant vectors simultaneously under an explicit global orthogonality constraint, which we call Deflation-Free Sparse Optimal Scoring (DFSOS). DFSOS combines Bregman iteration with orthogonality-constrained optimization, decomposing the problem into tractable subproblems for scoring vectors, discriminant vectors, and orthogonality enforcement. We establish convergence to stationary points of the augmented Lagrangian under mild conditions. Extensive experiments using synthetic data and real-world time series data demonstrate that DFSOS achieves classification accuracy comparable to or better than existing deflation-based methods. These results indicate that deflation-free approaches offer a robust and effective framework for sparse discriminant analysis in high-dimensional problems.
Provably Finding a Hidden Dense Submatrix among Many Planted Dense Submatrices via Convex Programming
Jan 07, 2026We consider the densest submatrix problem, which seeks the submatrix of fixed size of a given binary matrix that contains the most nonzero entries. This problem is a natural generalization of fundamental problems in combinatorial optimization, e.g., the densest subgraph, maximum clique, and maximum edge biclique problems, and has wide application the study of complex networks. Much recent research has focused on the development of sufficient conditions for exact solution of the densest submatrix problem via convex relaxation. The vast majority of these sufficient conditions establish identification of the densest submatrix within a graph containing exactly one large dense submatrix hidden by noise. The assumptions of these underlying models are not observed in real-world networks, where the data may correspond to a matrix containing many dense submatrices of varying sizes. We extend and generalize these results to the more realistic setting where the input matrix may contain \emph{many} large dense subgraphs. Specifically, we establish sufficient conditions under which we can expect to solve the densest submatrix problem in polynomial time for random input matrices sampled from a generalization of the stochastic block model. Moreover, we also provide sufficient conditions for perfect recovery under a deterministic adversarial. Numerical experiments involving randomly generated problem instances and real-world collaboration and communication networks are used empirically to verify the theoretical phase-transitions to perfect recovery given by these sufficient conditions.
Convex optimization for the densest subgraph and densest submatrix problems
Apr 05, 2019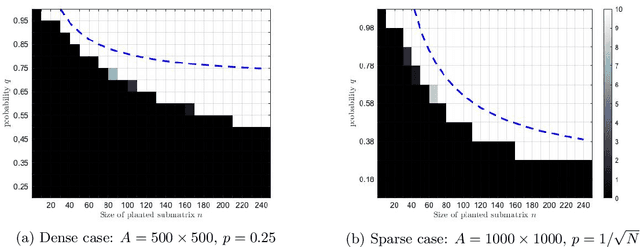


We consider the densest $k$-subgraph problem, which seeks to identify the $k$-node subgraph of a given input graph with maximum number of edges. This problem is well-known to be NP-hard, by reduction to the maximum clique problem. We propose a new convex relaxation for the densest $k$-subgraph problem, based on a nuclear norm relaxation of a low-rank plus sparse decomposition of the adjacency matrices of $k$-node subgraphs to partially address this intractability. We establish that the densest $k$-subgraph can be recovered with high probability from the optimal solution of this convex relaxation if the input graph is randomly sampled from a distribution of random graphs constructed to contain an especially dense $k$-node subgraph with high probability. Specifically, the relaxation is exact when the edges of the input graph are added independently at random, with edges within a particular $k$-node subgraph added with higher probability than other edges in the graph. We provide a sufficient condition on the size of this subgraph $k$ and the expected density under which the optimal solution of the proposed relaxation recovers this $k$-node subgraph with high probability. Further, we propose a first-order method for solving this relaxation based on the alternating direction method of multipliers, and empirically confirm our predicted recovery thresholds using simulations involving randomly generated graphs, as well as graphs drawn from social and collaborative networks.
Exact Clustering of Weighted Graphs via Semidefinite Programming
Oct 02, 2018
As a model problem for clustering, we consider the densest k-disjoint-clique problem of partitioning a weighted complete graph into k disjoint subgraphs such that the sum of the densities of these subgraphs is maximized. We establish that such subgraphs can be recovered from the solution of a particular semidefinite relaxation with high probability if the input graph is sampled from a distribution of clusterable graphs. Specifically, the semidefinite relaxation is exact if the graph consists of k large disjoint subgraphs, corresponding to clusters, with weight concentrated within these subgraphs, plus a moderate number of outliers. Further, we establish that if noise is weakly obscuring these clusters, i.e, the between-cluster edges are assigned very small weights, then we can recover significantly smaller clusters. For example, we show that in approximately sparse graphs, where the between-cluster weights tend to zero as the size n of the graph tends to infinity, we can recover clusters of size polylogarithmic in n. Empirical evidence from numerical simulations is also provided to support these theoretical phase transitions to perfect recovery of the cluster structure.